 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking RL for LLM Reasoning: It's Sparse Policy Selection, Not Capability Learning
May 07, 2026Reinforcement learning has become the standard for improving reasoning in large language models, yet evidence increasingly suggests that RL does not teach new strategies; it redistributes probability mass over solutions the base model already contains. In this work, we ask: if RL merely steers the model toward paths it already knows, is the RL optimization loop itself necessary? Through token-level analysis across multiple model families and RL algorithms, we find that RL's beneficial footprint is a sparse, predictable correction concentrated at high-entropy decision points where the model is uncertain which branch to take. Only 1--3\% of token positions are affected, the promoted token always lies within the base model's top-5 alternatives, and targeted corrections at those few positions causally recover a large fraction of RL's accuracy gain, while random corrections fail. The base model's own entropy identifies these positions without any RL-trained model, and the entire correction is low-dimensional, representable in a tiny fraction of model parameters. These findings reframe reasoning improvement as sparse policy selection, not capability acquisition. We translate this insight into ReasonMaxxer, a minimal RL-free method that applies contrastive loss only at entropy-gated decision points, using a few hundred base-model rollouts and no online generation. Across three model families, six scales, and six math reasoning benchmarks, ReasonMaxxer matches or exceeds full RL performance while requiring only tens of problems and minutes of single-GPU training, a reduction in training cost of roughly three orders of magnitude.
Supercharging Simulation-Based Inference for Bayesian Optimal Experimental Design
Feb 06, 2026Bayesian optimal experimental design (BOED) seeks to maximize the expected information gain (EIG) of experiments. This requires a likelihood estimate, which in many settings is intractable. Simulation-based inference (SBI) provides powerful tools for this regime. However, existing work explicitly connecting SBI and BOED is restricted to a single contrastive EIG bound. We show that the EIG admits multiple formulations which can directly leverage modern SBI density estimators, encompassing neural posterior, likelihood, and ratio estimation. Building on this perspective, we define a novel EIG estimator using neural likelihood estimation. Further, we identify optimization as a key bottleneck of gradient based EIG maximization and show that a simple multi-start parallel gradient ascent procedure can substantially improve reliability and performance. With these innovations, our SBI-based BOED methods are able to match or outperform by up to $22\%$ existing state-of-the-art approaches across standard BOED benchmarks.
Neural Nonmyopic Bayesian Optimization in Dynamic Cost Settings
Jan 10, 2026Bayesian optimization (BO) is a common framework for optimizing black-box functions, yet most existing methods assume static query costs and rely on myopic acquisition strategies. We introduce LookaHES, a nonmyopic BO framework designed for dynamic, history-dependent cost environments, where evaluation costs vary with prior actions, such as travel distance in spatial tasks or edit distance in sequence design. LookaHES combines a multi-step variant of $H$-Entropy Search with pathwise sampling and neural policy optimization, enabling long-horizon planning beyond twenty steps without the exponential complexity of existing nonmyopic methods. The key innovation is the integration of neural policies, including large language models, to effectively navigate structured, combinatorial action spaces such as protein sequences. These policies amortize lookahead planning and can be integrated with domain-specific constraints during rollout. Empirically, LookaHES outperforms strong myopic and nonmyopic baselines across nine synthetic benchmarks from two to eight dimensions and two real-world tasks: geospatial optimization using NASA night-light imagery and protein sequence design with constrained token-level edits. In short, LookaHES provides a general, scalable, and cost-aware solution for robust long-horizon optimization in complex decision spaces, which makes it a useful tool for researchers in machine learning, statistics, and applied domains. Our implementation is available at https://github.com/sangttruong/nonmyopia.
Hubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Probabilistic Graphical Models: A Concise Tutorial
Jul 23, 2025Probabilistic graphical modeling is a branch of machine learning that uses probability distributions to describe the world, make predictions, and support decision-making under uncertainty. Underlying this modeling framework is an elegant body of theory that bridges two mathematical traditions: probability and graph theory. This framework provides compact yet expressive representations of joint probability distributions, yielding powerful generative models for probabilistic reasoning. This tutorial provides a concise introduction to the formalisms, methods, and applications of this modeling framework. After a review of basic probability and graph theory, we explore three dominant themes: (1) the representation of multivariate distributions in the intuitive visual language of graphs, (2) algorithms for learning model parameters and graphical structures from data, and (3) algorithms for inference, both exact and approximate.
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025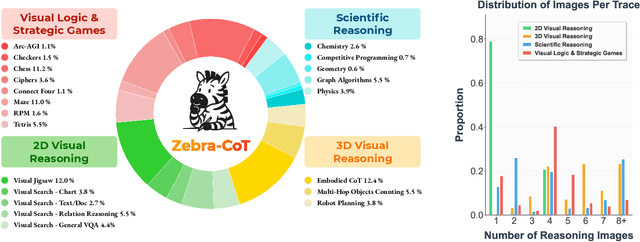

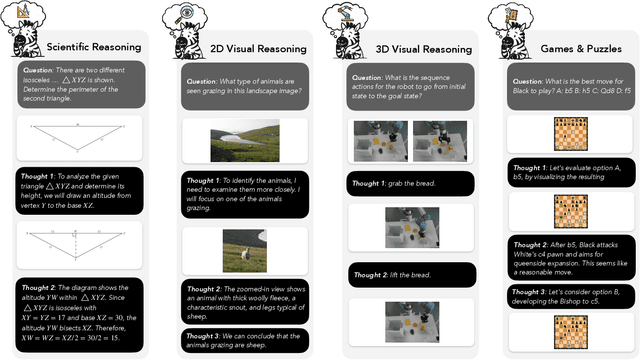

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
Resa: Transparent Reasoning Models via SAEs
Jun 11, 2025How cost-effectively can we elicit strong reasoning in language models by leveraging their underlying representations? We answer this question with Resa, a family of 1.5B reasoning models trained via a novel and efficient sparse autoencoder tuning (SAE-Tuning) procedure. This method first trains an SAE to capture reasoning abilities from a source model, and then uses the trained SAE to guide a standard supervised fine-tuning process to elicit such abilities in a target model, all using verified question-answer data without any reasoning traces. Notably, when applied to certain base models before further RL post-training, SAE-Tuning retains >97% of its RL-trained counterpart's reasoning performance while reducing training costs by >2000x to roughly \$1 and training time by >450x to around 20 minutes. Furthermore, when applied to lightly RL-trained models (e.g., within 1 hour on 2 GPUs), it enables reasoning performance such as 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23 for only around \$1 additional cost. Surprisingly, the reasoning abilities extracted via SAEs are potentially both generalizable and modular. Generality means abilities extracted from one dataset still elevate performance on a larger and overlapping corpus. Modularity means abilities extracted from Qwen or Qwen-Math can be attached to the R1-Distill model at test time, without any retraining, and yield comparable gains. Extensive ablations validate these findings and all artifacts are fully open-sourced.
From Calibration to Collaboration: LLM Uncertainty Quantification Should Be More Human-Centered
Jun 09, 2025Large Language Models (LLMs) are increasingly assisting users in the real world, yet their reliability remains a concern. Uncertainty quantification (UQ) has been heralded as a tool to enhance human-LLM collaboration by enabling users to know when to trust LLM predictions. We argue that current practices for uncertainty quantification in LLMs are not optimal for developing useful UQ for human users making decisions in real-world tasks. Through an analysis of 40 LLM UQ methods, we identify three prevalent practices hindering the community's progress toward its goal of benefiting downstream users: 1) evaluating on benchmarks with low ecological validity; 2) considering only epistemic uncertainty; and 3) optimizing metrics that are not necessarily indicative of downstream utility. For each issue, we propose concrete user-centric practices and research directions that LLM UQ researchers should consider. Instead of hill-climbing on unrepresentative tasks using imperfect metrics, we argue that the community should adopt a more human-centered approach to LLM uncertainty quantification.
Auditing Black-Box LLM APIs with a Rank-Based Uniformity Test
Jun 08, 2025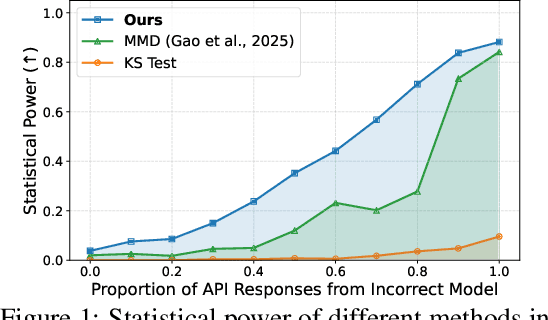

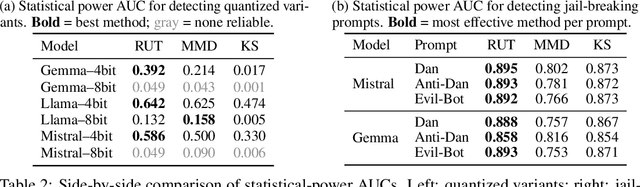
As API access becomes a primary interface to large language models (LLMs), users often interact with black-box systems that offer little transparency into the deployed model. To reduce costs or maliciously alter model behaviors, API providers may discreetly serve quantized or fine-tuned variants, which can degrade performance and compromise safety. Detecting such substitutions is difficult, as users lack access to model weights and, in most cases, even output logits. To tackle this problem, we propose a rank-based uniformity test that can verify the behavioral equality of a black-box LLM to a locally deployed authentic model. Our method is accurate, query-efficient, and avoids detectable query patterns, making it robust to adversarial providers that reroute or mix responses upon the detection of testing attempts. We evaluate the approach across diverse threat scenarios, including quantization, harmful fine-tuning, jailbreak prompts, and full model substitution, showing that it consistently achieves superior statistical power over prior methods under constrained query budgets.
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
May 20, 2025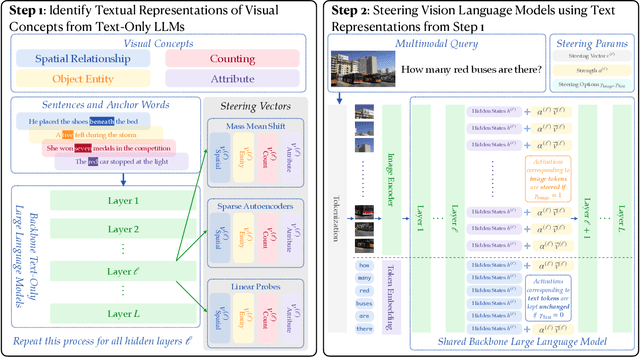
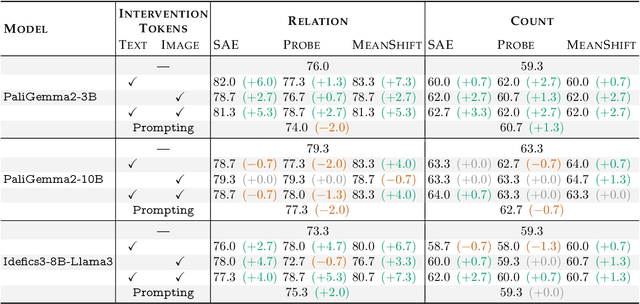
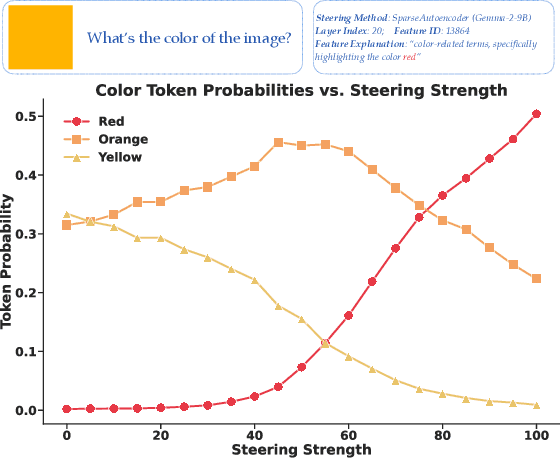
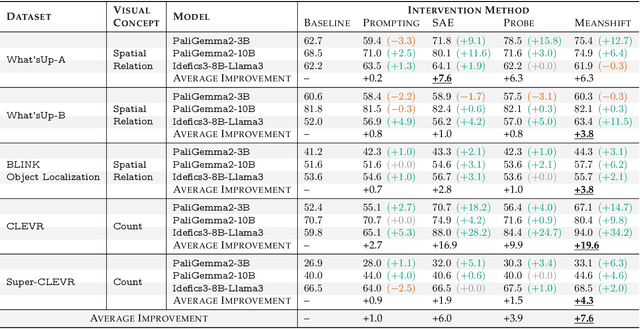
Steering methods have emerged as effective and targeted tools for guiding large language models' (LLMs) behavior without modifying their parameters. Multimodal large language models (MLLMs), however, do not currently enjoy the same suite of techniques, due in part to their recency and architectural diversity. Inspired by this gap, we investigate whether MLLMs can be steered using vectors derived from their text-only LLM backbone, via sparse autoencoders (SAEs), mean shift, and linear probing. We find that text-derived steering consistently enhances multimodal accuracy across diverse MLLM architectures and visual tasks. In particular, mean shift boosts spatial relationship accuracy on CV-Bench by up to +7.3% and counting accuracy by up to +3.3%, outperforming prompting and exhibiting strong generalization to out-of-distribution datasets. These results highlight textual steering vectors as a powerful, efficient mechanism for enhancing grounding in MLLMs with minimal additional data collection and computational overhead.