 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResa: Transparent Reasoning Models via SAEs
Jun 11, 2025How cost-effectively can we elicit strong reasoning in language models by leveraging their underlying representations? We answer this question with Resa, a family of 1.5B reasoning models trained via a novel and efficient sparse autoencoder tuning (SAE-Tuning) procedure. This method first trains an SAE to capture reasoning abilities from a source model, and then uses the trained SAE to guide a standard supervised fine-tuning process to elicit such abilities in a target model, all using verified question-answer data without any reasoning traces. Notably, when applied to certain base models before further RL post-training, SAE-Tuning retains >97% of its RL-trained counterpart's reasoning performance while reducing training costs by >2000x to roughly \$1 and training time by >450x to around 20 minutes. Furthermore, when applied to lightly RL-trained models (e.g., within 1 hour on 2 GPUs), it enables reasoning performance such as 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23 for only around \$1 additional cost. Surprisingly, the reasoning abilities extracted via SAEs are potentially both generalizable and modular. Generality means abilities extracted from one dataset still elevate performance on a larger and overlapping corpus. Modularity means abilities extracted from Qwen or Qwen-Math can be attached to the R1-Distill model at test time, without any retraining, and yield comparable gains. Extensive ablations validate these findings and all artifacts are fully open-sourced.
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
May 20, 2025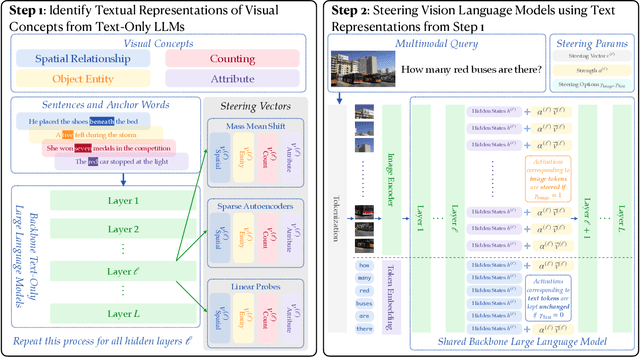
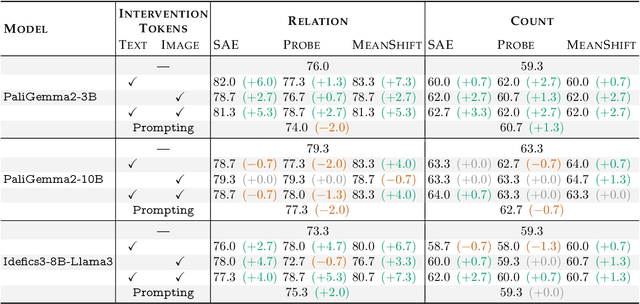
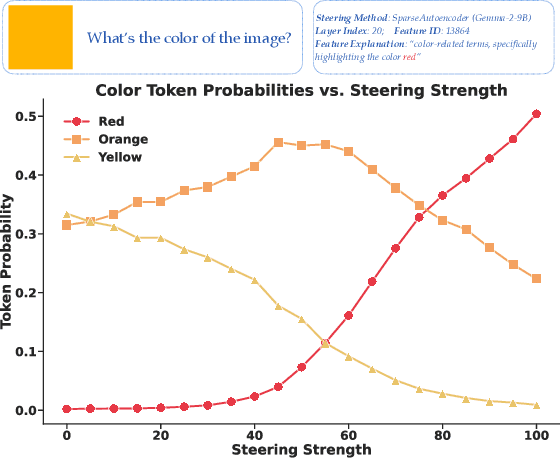
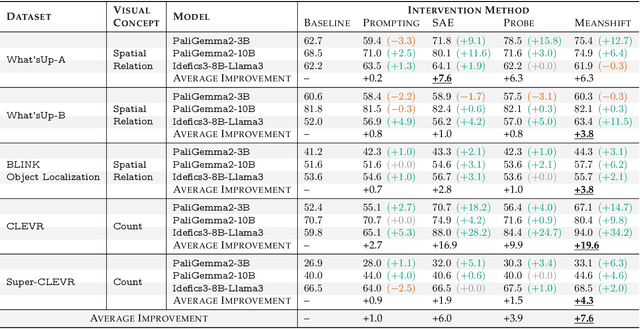
Steering methods have emerged as effective and targeted tools for guiding large language models' (LLMs) behavior without modifying their parameters. Multimodal large language models (MLLMs), however, do not currently enjoy the same suite of techniques, due in part to their recency and architectural diversity. Inspired by this gap, we investigate whether MLLMs can be steered using vectors derived from their text-only LLM backbone, via sparse autoencoders (SAEs), mean shift, and linear probing. We find that text-derived steering consistently enhances multimodal accuracy across diverse MLLM architectures and visual tasks. In particular, mean shift boosts spatial relationship accuracy on CV-Bench by up to +7.3% and counting accuracy by up to +3.3%, outperforming prompting and exhibiting strong generalization to out-of-distribution datasets. These results highlight textual steering vectors as a powerful, efficient mechanism for enhancing grounding in MLLMs with minimal additional data collection and computational overhead.
Tina: Tiny Reasoning Models via LoRA
Apr 22, 2025How cost-effectively can strong reasoning abilities be achieved in language models? Driven by this fundamental question, we present Tina, a family of tiny reasoning models achieved with high cost-efficiency. Notably, Tina demonstrates that substantial reasoning performance can be developed using only minimal resources, by applying parameter-efficient updates during reinforcement learning (RL), using low-rank adaptation (LoRA), to an already tiny 1.5B parameter base model. This minimalist approach produces models that achieve reasoning performance which is competitive with, and sometimes surpasses, SOTA RL reasoning models built upon the same base model. Crucially, this is achieved at a tiny fraction of the computational post-training cost employed by existing SOTA models. In fact, the best Tina model achieves a >20\% reasoning performance increase and 43.33\% Pass@1 accuracy on AIME24, at only \$9 USD post-training and evaluation cost (i.e., an estimated 260x cost reduction). Our work reveals the surprising effectiveness of efficient RL reasoning via LoRA. We validate this across multiple open-source reasoning datasets and various ablation settings starting with a single, fixed set of hyperparameters. Furthermore, we hypothesize that this effectiveness and efficiency stem from LoRA rapidly adapting the model to the structural format of reasoning rewarded by RL, while largely preserving the base model's underlying knowledge. In service of accessibility and open research, we fully open-source all code, training logs, and model weights \& checkpoints.
On Agnostic PAC Learning in the Small Error Regime
Feb 13, 2025
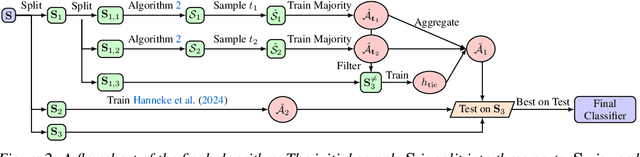
Binary classification in the classic PAC model exhibits a curious phenomenon: Empirical Risk Minimization (ERM) learners are suboptimal in the realizable case yet optimal in the agnostic case. Roughly speaking, this owes itself to the fact that non-realizable distributions $\mathcal{D}$ are simply more difficult to learn than realizable distributions -- even when one discounts a learner's error by $\mathrm{err}(h^*_{\mathcal{D}})$, the error of the best hypothesis in $\mathcal{H}$ for $\mathcal{D}$. Thus, optimal agnostic learners are permitted to incur excess error on (easier-to-learn) distributions $\mathcal{D}$ for which $\tau = \mathrm{err}(h^*_{\mathcal{D}})$ is small. Recent work of Hanneke, Larsen, and Zhivotovskiy (FOCS `24) addresses this shortcoming by including $\tau$ itself as a parameter in the agnostic error term. In this more fine-grained model, they demonstrate tightness of the error lower bound $\tau + \Omega \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ in a regime where $\tau > d/m$, and leave open the question of whether there may be a higher lower bound when $\tau \approx d/m$, with $d$ denoting $\mathrm{VC}(\mathcal{H})$. In this work, we resolve this question by exhibiting a learner which achieves error $c \cdot \tau + O \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ for a constant $c \leq 2.1$, thus matching the lower bound when $\tau \approx d/m$. Further, our learner is computationally efficient and is based upon careful aggregations of ERM classifiers, making progress on two other questions of Hanneke, Larsen, and Zhivotovskiy (FOCS `24). We leave open the interesting question of whether our approach can be refined to lower the constant from 2.1 to 1, which would completely settle the complexity of agnostic learning.
Local Regularizers Are Not Transductive Learners
Feb 11, 2025We partly resolve an open question raised by Asilis et al. (COLT 2024): whether the algorithmic template of local regularization -- an intriguing generalization of explicit regularization, a.k.a. structural risk minimization -- suffices to learn all learnable multiclass problems. Specifically, we provide a negative answer to this question in the transductive model of learning. We exhibit a multiclass classification problem which is learnable in both the transductive and PAC models, yet cannot be learned transductively by any local regularizer. The corresponding hypothesis class, and our proof, are based on principles from cryptographic secret sharing. We outline challenges in extending our negative result to the PAC model, leaving open the tantalizing possibility of a PAC/transductive separation with respect to local regularization.
Understanding Aggregations of Proper Learners in Multiclass Classification
Oct 30, 2024Multiclass learnability is known to exhibit a properness barrier: there are learnable classes which cannot be learned by any proper learner. Binary classification faces no such barrier for learnability, but a similar one for optimal learning, which can in general only be achieved by improper learners. Fortunately, recent advances in binary classification have demonstrated that this requirement can be satisfied using aggregations of proper learners, some of which are strikingly simple. This raises a natural question: to what extent can simple aggregations of proper learners overcome the properness barrier in multiclass classification? We give a positive answer to this question for classes which have finite Graph dimension, $d_G$. Namely, we demonstrate that the optimal binary learners of Hanneke, Larsen, and Aden-Ali et al. (appropriately generalized to the multiclass setting) achieve sample complexity $O\left(\frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$. This forms a strict improvement upon the sample complexity of ERM. We complement this with a lower bound demonstrating that for certain classes of Graph dimension $d_G$, majorities of ERM learners require $\Omega \left( \frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$ samples. Furthermore, we show that a single ERM requires $\Omega \left(\frac{d_G \ln(1 / \epsilon) + \ln(1 / \delta)}{\epsilon}\right)$ samples on such classes, exceeding the lower bound of Daniely et al. (2015) by a factor of $\ln(1 / \epsilon)$. For multiclass learning in full generality -- i.e., for classes of finite DS dimension but possibly infinite Graph dimension -- we give a strong refutation to these learning strategies, by exhibiting a learnable class which cannot be learned to constant error by any aggregation of a finite number of proper learners.
Learnability is a Compact Property
Feb 15, 2024
Recent work on learning has yielded a striking result: the learnability of various problems can be undecidable, or independent of the standard ZFC axioms of set theory. Furthermore, the learnability of such problems can fail to be a property of finite character: informally, it cannot be detected by examining finite projections of the problem. On the other hand, learning theory abounds with notions of dimension that characterize learning and consider only finite restrictions of the problem, i.e., are properties of finite character. How can these results be reconciled? More precisely, which classes of learning problems are vulnerable to logical undecidability, and which are within the grasp of finite characterizations? We demonstrate that the difficulty of supervised learning with metric losses admits a tight finite characterization. In particular, we prove that the sample complexity of learning a hypothesis class can be detected by examining its finite projections. For realizable and agnostic learning with respect to a wide class of proper loss functions, we demonstrate an exact compactness result: a class is learnable with a given sample complexity precisely when the same is true of all its finite projections. For realizable learning with improper loss functions, we show that exact compactness of sample complexity can fail, and provide matching upper and lower bounds of a factor of 2 on the extent to which such sample complexities can differ. We conjecture that larger gaps are possible for the agnostic case. At the heart of our technical work is a compactness result concerning assignments of variables that maintain a class of functions below a target value, which generalizes Hall's classic matching theorem and may be of independent interest.
Regularization and Optimal Multiclass Learning
Sep 24, 2023

The quintessential learning algorithm of empirical risk minimization (ERM) is known to fail in various settings for which uniform convergence does not characterize learning. It is therefore unsurprising that the practice of machine learning is rife with considerably richer algorithmic techniques for successfully controlling model capacity. Nevertheless, no such technique or principle has broken away from the pack to characterize optimal learning in these more general settings. The purpose of this work is to characterize the role of regularization in perhaps the simplest setting for which ERM fails: multiclass learning with arbitrary label sets. Using one-inclusion graphs (OIGs), we exhibit optimal learning algorithms that dovetail with tried-and-true algorithmic principles: Occam's Razor as embodied by structural risk minimization (SRM), the principle of maximum entropy, and Bayesian reasoning. Most notably, we introduce an optimal learner which relaxes structural risk minimization on two dimensions: it allows the regularization function to be "local" to datapoints, and uses an unsupervised learning stage to learn this regularizer at the outset. We justify these relaxations by showing that they are necessary: removing either dimension fails to yield a near-optimal learner. We also extract from OIGs a combinatorial sequence we term the Hall complexity, which is the first to characterize a problem's transductive error rate exactly. Lastly, we introduce a generalization of OIGs and the transductive learning setting to the agnostic case, where we show that optimal orientations of Hamming graphs -- judged using nodes' outdegrees minus a system of node-dependent credits -- characterize optimal learners exactly. We demonstrate that an agnostic version of the Hall complexity again characterizes error rates exactly, and exhibit an optimal learner using maximum entropy programs.
On computable learning of continuous features
Nov 24, 2021We introduce definitions of computable PAC learning for binary classification over computable metric spaces. We provide sufficient conditions for learners that are empirical risk minimizers (ERM) to be computable, and bound the strong Weihrauch degree of an ERM learner under more general conditions. We also give a presentation of a hypothesis class that does not admit any proper computable PAC learner with computable sample function, despite the underlying class being PAC learnable.