 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextLeak: Auditing Leakage in Private In-Context Learning Methods
Dec 18, 2025In-Context Learning (ICL) has become a standard technique for adapting Large Language Models (LLMs) to specialized tasks by supplying task-specific exemplars within the prompt. However, when these exemplars contain sensitive information, reliable privacy-preserving mechanisms are essential to prevent unintended leakage through model outputs. Many privacy-preserving methods are proposed to protect the information leakage in the context, but there are less efforts on how to audit those methods. We introduce ContextLeak, the first framework to empirically measure the worst-case information leakage in ICL. ContextLeak uses canary insertion, embedding uniquely identifiable tokens in exemplars and crafting targeted queries to detect their presence. We apply ContextLeak across a range of private ICL techniques, both heuristic such as prompt-based defenses and those with theoretical guarantees such as Embedding Space Aggregation and Report Noisy Max. We find that ContextLeak tightly correlates with the theoretical privacy budget ($ε$) and reliably detects leakage. Our results further reveal that existing methods often strike poor privacy-utility trade-offs, either leaking sensitive information or severely degrading performance.
Hubble: a Model Suite to Advance the Study of LLM Memorization
Oct 22, 2025We present Hubble, a suite of fully open-source large language models (LLMs) for the scientific study of LLM memorization. Hubble models come in standard and perturbed variants: standard models are pretrained on a large English corpus, and perturbed models are trained in the same way but with controlled insertion of text (e.g., book passages, biographies, and test sets) designed to emulate key memorization risks. Our core release includes 8 models -- standard and perturbed models with 1B or 8B parameters, pretrained on 100B or 500B tokens -- establishing that memorization risks are determined by the frequency of sensitive data relative to size of the training corpus (i.e., a password appearing once in a smaller corpus is memorized better than the same password in a larger corpus). Our release also includes 6 perturbed models with text inserted at different pretraining phases, showing that sensitive data without continued exposure can be forgotten. These findings suggest two best practices for addressing memorization risks: to dilute sensitive data by increasing the size of the training corpus, and to order sensitive data to appear earlier in training. Beyond these general empirical findings, Hubble enables a broad range of memorization research; for example, analyzing the biographies reveals how readily different types of private information are memorized. We also demonstrate that the randomized insertions in Hubble make it an ideal testbed for membership inference and machine unlearning, and invite the community to further explore, benchmark, and build upon our work.
Zebra-CoT: A Dataset for Interleaved Vision Language Reasoning
Jul 22, 2025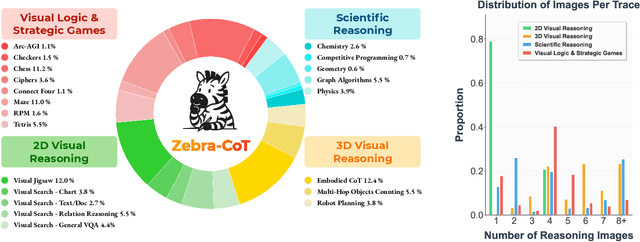

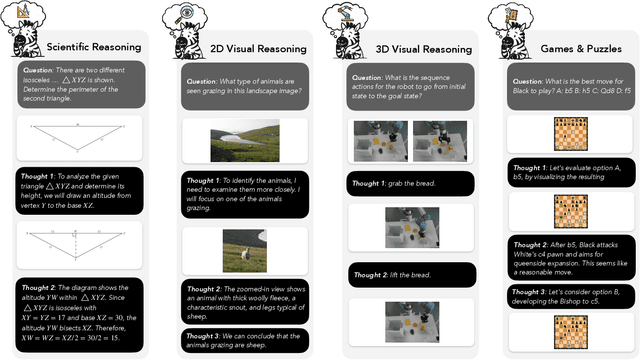

Humans often use visual aids, for example diagrams or sketches, when solving complex problems. Training multimodal models to do the same, known as Visual Chain of Thought (Visual CoT), is challenging due to: (1) poor off-the-shelf visual CoT performance, which hinders reinforcement learning, and (2) the lack of high-quality visual CoT training data. We introduce $\textbf{Zebra-CoT}$, a diverse large-scale dataset with 182,384 samples, containing logically coherent interleaved text-image reasoning traces. We focus on four categories of tasks where sketching or visual reasoning is especially natural, spanning scientific questions such as geometry, physics, and algorithms; 2D visual reasoning tasks like visual search and jigsaw puzzles; 3D reasoning tasks including 3D multi-hop inference, embodied and robot planning; visual logic problems and strategic games like chess. Fine-tuning the Anole-7B model on the Zebra-CoT training corpus results in an improvement of +12% in our test-set accuracy and yields up to +13% performance gain on standard VLM benchmark evaluations. Fine-tuning Bagel-7B yields a model that generates high-quality interleaved visual reasoning chains, underscoring Zebra-CoT's effectiveness for developing multimodal reasoning abilities. We open-source our dataset and models to support development and evaluation of visual CoT.
When Do LLMs Admit Their Mistakes? Understanding the Role of Model Belief in Retraction
May 22, 2025Can large language models (LLMs) admit their mistakes when they should know better? In this work, we define the behavior of acknowledging errors in previously generated answers as "retraction" and aim to understand when and why LLMs choose to retract. We first construct model-specific datasets to evaluate whether a model will retract an incorrect answer that contradicts its own parametric knowledge. While LLMs are capable of retraction, they do so only infrequently. We demonstrate that retraction is closely tied to previously identified indicators of models' internal belief: models fail to retract wrong answers that they "believe" to be factually correct. Steering experiments further demonstrate that internal belief causally influences model retraction. In particular, when the model does not believe its answer, this not only encourages the model to attempt to verify the answer, but also alters attention behavior during self-verification. Finally, we demonstrate that simple supervised fine-tuning significantly improves retraction performance by helping the model learn more accurate internal beliefs. Code and datasets are available on https://github.com/ayyyq/llm-retraction.
Textual Steering Vectors Can Improve Visual Understanding in Multimodal Large Language Models
May 20, 2025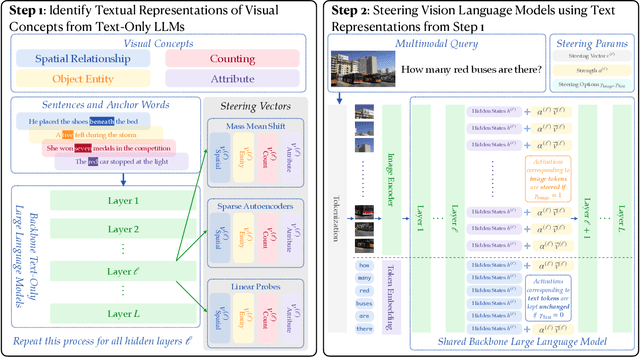
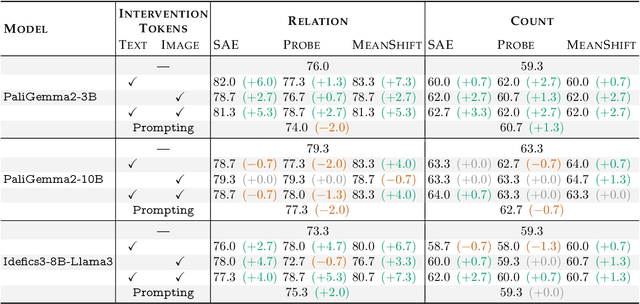
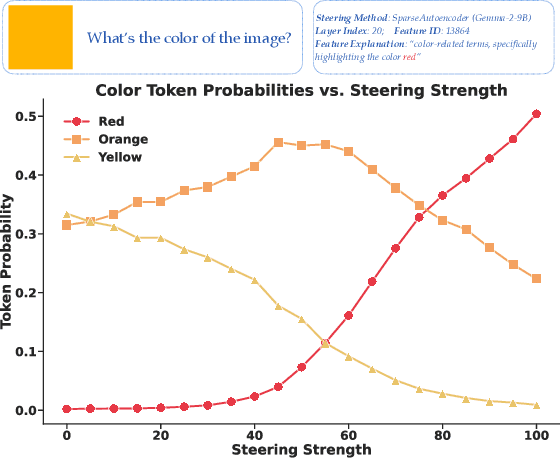
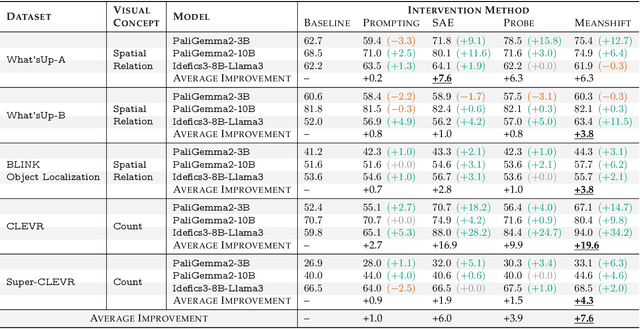
Steering methods have emerged as effective and targeted tools for guiding large language models' (LLMs) behavior without modifying their parameters. Multimodal large language models (MLLMs), however, do not currently enjoy the same suite of techniques, due in part to their recency and architectural diversity. Inspired by this gap, we investigate whether MLLMs can be steered using vectors derived from their text-only LLM backbone, via sparse autoencoders (SAEs), mean shift, and linear probing. We find that text-derived steering consistently enhances multimodal accuracy across diverse MLLM architectures and visual tasks. In particular, mean shift boosts spatial relationship accuracy on CV-Bench by up to +7.3% and counting accuracy by up to +3.3%, outperforming prompting and exhibiting strong generalization to out-of-distribution datasets. These results highlight textual steering vectors as a powerful, efficient mechanism for enhancing grounding in MLLMs with minimal additional data collection and computational overhead.
Teaching Models to Understand (but not Generate) High-risk Data
May 05, 2025Language model developers typically filter out high-risk content -- such as toxic or copyrighted text -- from their pre-training data to prevent models from generating similar outputs. However, removing such data altogether limits models' ability to recognize and appropriately respond to harmful or sensitive content. In this paper, we introduce Selective Loss to Understand but Not Generate (SLUNG), a pre-training paradigm through which models learn to understand high-risk data without learning to generate it. Instead of uniformly applying the next-token prediction loss, SLUNG selectively avoids incentivizing the generation of high-risk tokens while ensuring they remain within the model's context window. As the model learns to predict low-risk tokens that follow high-risk ones, it is forced to understand the high-risk content. Through our experiments, we show that SLUNG consistently improves models' understanding of high-risk data (e.g., ability to recognize toxic content) without increasing its generation (e.g., toxicity of model responses). Overall, our SLUNG paradigm enables models to benefit from high-risk text that would otherwise be filtered out.
Cancer-Myth: Evaluating AI Chatbot on Patient Questions with False Presuppositions
Apr 15, 2025

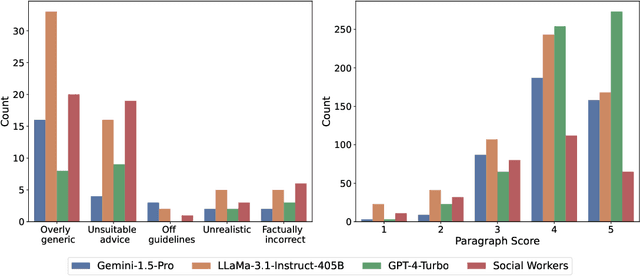
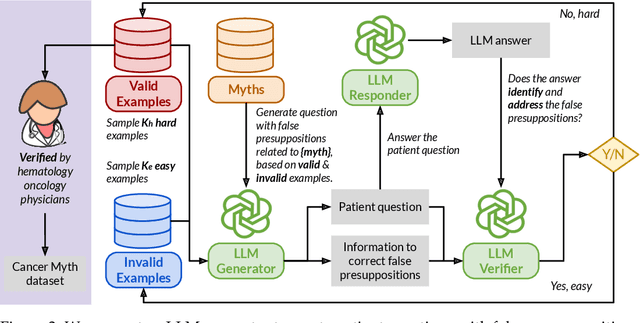
Cancer patients are increasingly turning to large language models (LLMs) as a new form of internet search for medical information, making it critical to assess how well these models handle complex, personalized questions. However, current medical benchmarks focus on medical exams or consumer-searched questions and do not evaluate LLMs on real patient questions with detailed clinical contexts. In this paper, we first evaluate LLMs on cancer-related questions drawn from real patients, reviewed by three hematology oncology physicians. While responses are generally accurate, with GPT-4-Turbo scoring 4.13 out of 5, the models frequently fail to recognize or address false presuppositions in the questions-posing risks to safe medical decision-making. To study this limitation systematically, we introduce Cancer-Myth, an expert-verified adversarial dataset of 585 cancer-related questions with false presuppositions. On this benchmark, no frontier LLM -- including GPT-4o, Gemini-1.Pro, and Claude-3.5-Sonnet -- corrects these false presuppositions more than 30% of the time. Even advanced medical agentic methods do not prevent LLMs from ignoring false presuppositions. These findings expose a critical gap in the clinical reliability of LLMs and underscore the need for more robust safeguards in medical AI systems.
Robust Data Watermarking in Language Models by Injecting Fictitious Knowledge
Mar 06, 2025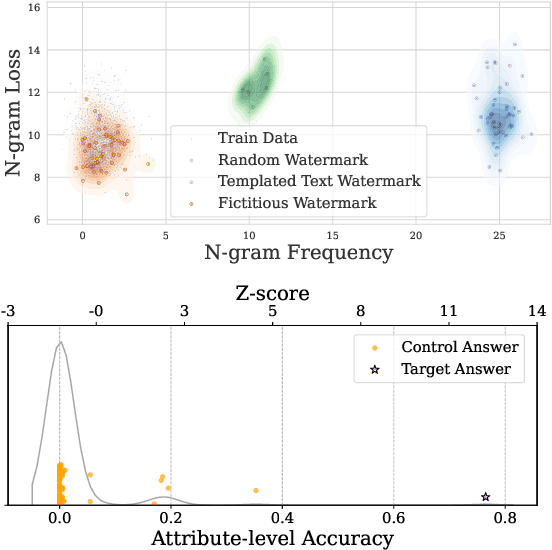

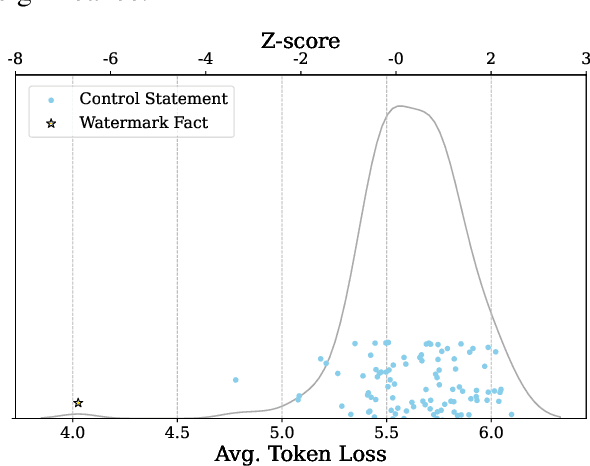

Data watermarking in language models injects traceable signals, such as specific token sequences or stylistic patterns, into copyrighted text, allowing copyright holders to track and verify training data ownership. Previous data watermarking techniques primarily focus on effective memorization after pretraining, while overlooking challenges that arise in other stages of the LLM pipeline, such as the risk of watermark filtering during data preprocessing, or potential forgetting through post-training, or verification difficulties due to API-only access. We propose a novel data watermarking approach that injects coherent and plausible yet fictitious knowledge into training data using generated passages describing a fictitious entity and its associated attributes. Our watermarks are designed to be memorized by the LLM through seamlessly integrating in its training data, making them harder to detect lexically during preprocessing.We demonstrate that our watermarks can be effectively memorized by LLMs, and that increasing our watermarks' density, length, and diversity of attributes strengthens their memorization. We further show that our watermarks remain robust throughout LLM development, maintaining their effectiveness after continual pretraining and supervised finetuning. Finally, we show that our data watermarks can be evaluated even under API-only access via question answering.
Promote, Suppress, Iterate: How Language Models Answer One-to-Many Factual Queries
Feb 27, 2025To answer one-to-many factual queries (e.g., listing cities of a country), a language model (LM) must simultaneously recall knowledge and avoid repeating previous answers. How are these two subtasks implemented and integrated internally? Across multiple datasets and models, we identify a promote-then-suppress mechanism: the model first recalls all answers, and then suppresses previously generated ones. Specifically, LMs use both the subject and previous answer tokens to perform knowledge recall, with attention propagating subject information and MLPs promoting the answers. Then, attention attends to and suppresses previous answer tokens, while MLPs amplify the suppression signal. Our mechanism is corroborated by extensive experimental evidence: in addition to using early decoding and causal tracing, we analyze how components use different tokens by introducing both \emph{Token Lens}, which decodes aggregated attention updates from specified tokens, and a knockout method that analyzes changes in MLP outputs after removing attention to specified tokens. Overall, we provide new insights into how LMs' internal components interact with different input tokens to support complex factual recall. Code is available at https://github.com/Lorenayannnnn/how-lms-answer-one-to-many-factual-queries.
Interrogating LLM design under a fair learning doctrine
Feb 22, 2025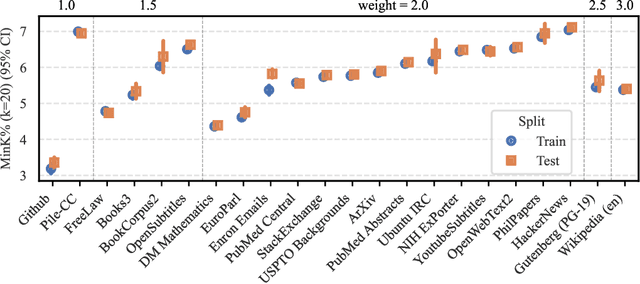
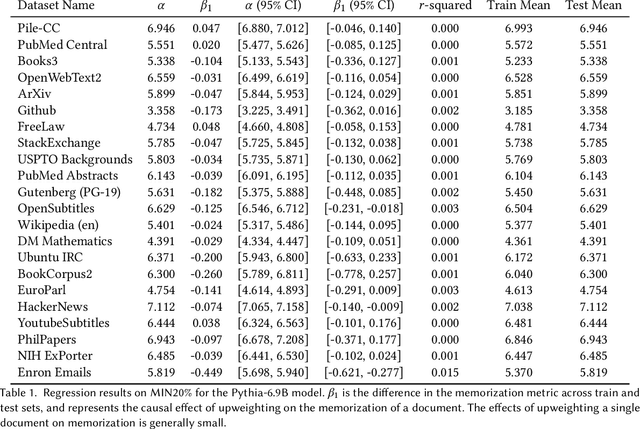
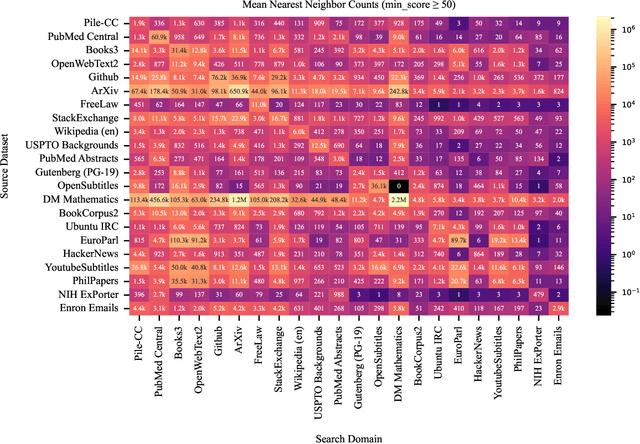
The current discourse on large language models (LLMs) and copyright largely takes a "behavioral" perspective, focusing on model outputs and evaluating whether they are substantially similar to training data. However, substantial similarity is difficult to define algorithmically and a narrow focus on model outputs is insufficient to address all copyright risks. In this interdisciplinary work, we take a complementary "structural" perspective and shift our focus to how LLMs are trained. We operationalize a notion of "fair learning" by measuring whether any training decision substantially affected the model's memorization. As a case study, we deconstruct Pythia, an open-source LLM, and demonstrate the use of causal and correlational analyses to make factual determinations about Pythia's training decisions. By proposing a legal standard for fair learning and connecting memorization analyses to this standard, we identify how judges may advance the goals of copyright law through adjudication. Finally, we discuss how a fair learning standard might evolve to enhance its clarity by becoming more rule-like and incorporating external technical guidelines.