 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models can Infer Action Semantics for Classical Planners from Environment Feedback
Jun 04, 2024Classical planning approaches guarantee finding a set of actions that can achieve a given goal state when possible, but require an expert to specify logical action semantics that govern the dynamics of the environment. Researchers have shown that Large Language Models (LLMs) can be used to directly infer planning steps based on commonsense knowledge and minimal domain information alone, but such plans often fail on execution. We bring together the strengths of classical planning and LLM commonsense inference to perform domain induction, learning and validating action pre- and post-conditions based on closed-loop interactions with the environment itself. We propose PSALM, which leverages LLM inference to heuristically complete partial plans emitted by a classical planner given partial domain knowledge, as well as to infer the semantic rules of the domain in a logical language based on environment feedback after execution. Our analysis on 7 environments shows that with just one expert-curated example plans, using LLMs as heuristic planners and rule predictors achieves lower environment execution steps and environment resets than random exploration while simultaneously recovering the underlying ground truth action semantics of the domain.
TwoStep: Multi-agent Task Planning using Classical Planners and Large Language Models
Mar 25, 2024
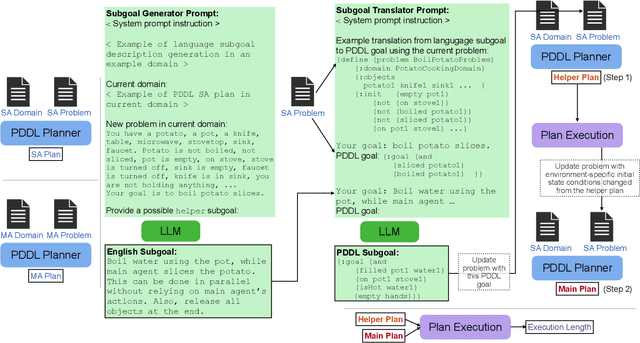


Classical planning formulations like the Planning Domain Definition Language (PDDL) admit action sequences guaranteed to achieve a goal state given an initial state if any are possible. However, reasoning problems defined in PDDL do not capture temporal aspects of action taking, for example that two agents in the domain can execute an action simultaneously if postconditions of each do not interfere with preconditions of the other. A human expert can decompose a goal into largely independent constituent parts and assign each agent to one of these subgoals to take advantage of simultaneous actions for faster execution of plan steps, each using only single agent planning. By contrast, large language models (LLMs) used for directly inferring plan steps do not guarantee execution success, but do leverage commonsense reasoning to assemble action sequences. We combine the strengths of classical planning and LLMs by approximating human intuitions for two-agent planning goal decomposition. We demonstrate that LLM-based goal decomposition leads to faster planning times than solving multi-agent PDDL problems directly while simultaneously achieving fewer plan execution steps than a single agent plan alone and preserving execution success. Additionally, we find that LLM-based approximations of subgoals can achieve similar multi-agent execution steps than those specified by human experts. Website and resources at https://glamor-usc.github.io/twostep
THE COLOSSEUM: A Benchmark for Evaluating Generalization for Robotic Manipulation
Feb 13, 2024To realize effective large-scale, real-world robotic applications, we must evaluate how well our robot policies adapt to changes in environmental conditions. Unfortunately, a majority of studies evaluate robot performance in environments closely resembling or even identical to the training setup. We present THE COLOSSEUM, a novel simulation benchmark, with 20 diverse manipulation tasks, that enables systematical evaluation of models across 12 axes of environmental perturbations. These perturbations include changes in color, texture, and size of objects, table-tops, and backgrounds; we also vary lighting, distractors, and camera pose. Using THE COLOSSEUM, we compare 4 state-of-the-art manipulation models to reveal that their success rate degrades between 30-50% across these perturbation factors. When multiple perturbations are applied in unison, the success rate degrades $\geq$75%. We identify that changing the number of distractor objects, target object color, or lighting conditions are the perturbations that reduce model performance the most. To verify the ecological validity of our results, we show that our results in simulation are correlated ($\bar{R}^2 = 0.614$) to similar perturbations in real-world experiments. We open source code for others to use THE COLOSSEUM, and also release code to 3D print the objects used to replicate the real-world perturbations. Ultimately, we hope that THE COLOSSEUM will serve as a benchmark to identify modeling decisions that systematically improve generalization for manipulation. See https://robot-colosseum.github.io/ for more details.
Does VLN Pretraining Work with Nonsensical or Irrelevant Instructions?
Dec 02, 2023



Data augmentation via back-translation is common when pretraining Vision-and-Language Navigation (VLN) models, even though the generated instructions are noisy. But: does that noise matter? We find that nonsensical or irrelevant language instructions during pretraining can have little effect on downstream performance for both HAMT and VLN-BERT on R2R, and is still better than only using clean, human data. To underscore these results, we concoct an efficient augmentation method, Unigram + Object, which generates nonsensical instructions that nonetheless improve downstream performance. Our findings suggest that what matters for VLN R2R pretraining is the quantity of visual trajectories, not the quality of instructions.
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models
Sep 22, 2022



Task planning can require defining myriad domain knowledge about the world in which a robot needs to act. To ameliorate that effort, large language models (LLMs) can be used to score potential next actions during task planning, and even generate action sequences directly, given an instruction in natural language with no additional domain information. However, such methods either require enumerating all possible next steps for scoring, or generate free-form text that may contain actions not possible on a given robot in its current context. We present a programmatic LLM prompt structure that enables plan generation functional across situated environments, robot capabilities, and tasks. Our key insight is to prompt the LLM with program-like specifications of the available actions and objects in an environment, as well as with example programs that can be executed. We make concrete recommendations about prompt structure and generation constraints through ablation experiments, demonstrate state of the art success rates in VirtualHome household tasks, and deploy our method on a physical robot arm for tabletop tasks. Website at progprompt.github.io
Pre-trained Language Models as Prior Knowledge for Playing Text-based Games
Jul 18, 2021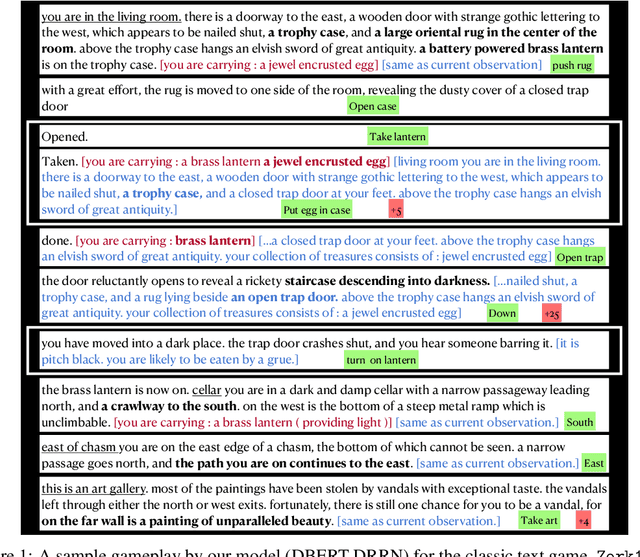

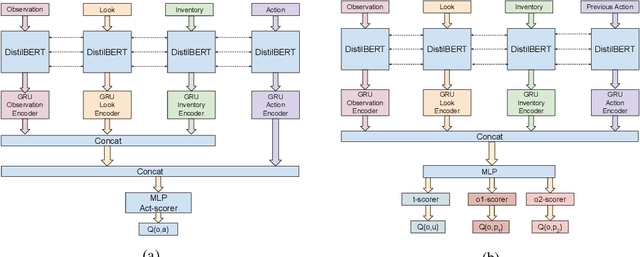

Recently, text world games have been proposed to enable artificial agents to understand and reason about real-world scenarios. These text-based games are challenging for artificial agents, as it requires understanding and interaction using natural language in a partially observable environment. In this paper, we improve the semantic understanding of the agent by proposing a simple RL with LM framework where we use transformer-based language models with Deep RL models. We perform a detailed study of our framework to demonstrate how our model outperforms all existing agents on the popular game, Zork1, to achieve a score of 44.7, which is 1.6 higher than the state-of-the-art model. Our proposed approach also performs comparably to the state-of-the-art models on the other set of text games.
Adapting a Language Model for Controlled Affective Text Generation
Nov 08, 2020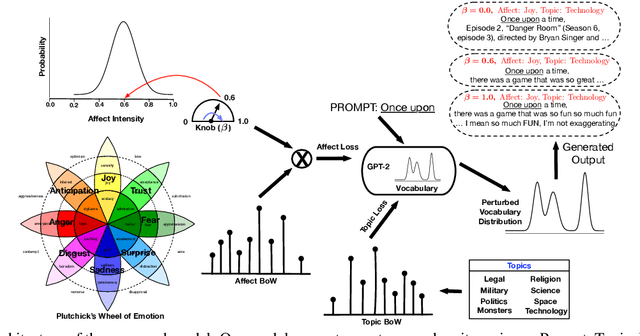
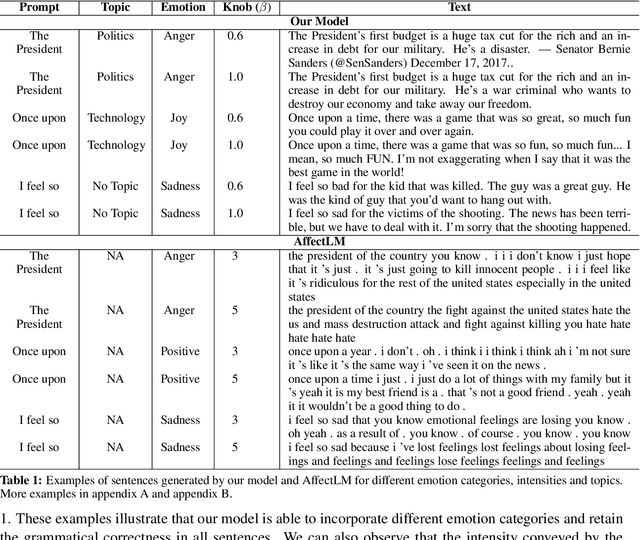
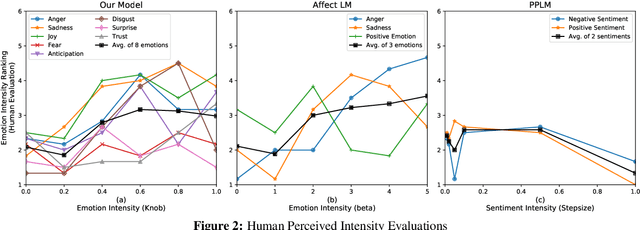
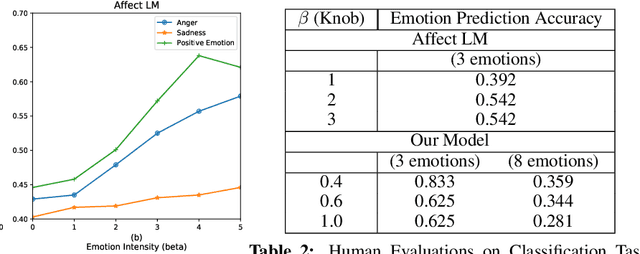
Human use language not just to convey information but also to express their inner feelings and mental states. In this work, we adapt the state-of-the-art language generation models to generate affective (emotional) text. We posit a model capable of generating affect-driven and topic-focused sentences without losing grammatical correctness as the affect intensity increases. We propose to incorporate emotion as prior for the probabilistic state-of-the-art text generation model such as GPT-2. The model gives a user the flexibility to control the category and intensity of emotion as well as the topic of the generated text. Previous attempts at modelling fine-grained emotions fall out on grammatical correctness at extreme intensities, but our model is resilient to this and delivers robust results at all intensities. We conduct automated evaluations and human studies to test the performance of our model and provide a detailed comparison of the results with other models. In all evaluations, our model outperforms existing affective text generation models.
Differentially-private Federated Neural Architecture Search
Jun 22, 2020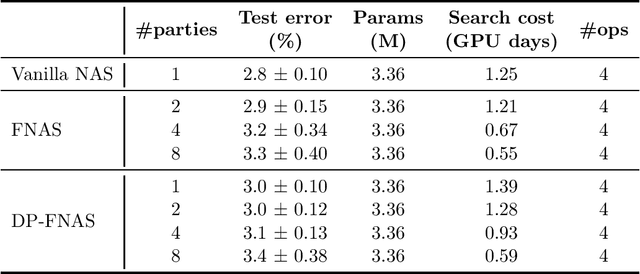
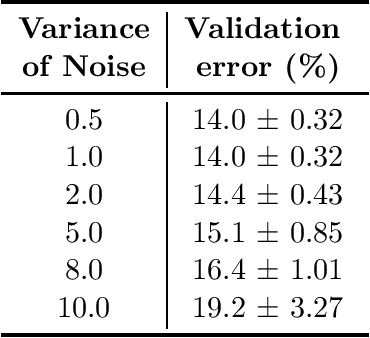
Neural architecture search, which aims to automatically search for architectures (e.g., convolution, max pooling) of neural networks that maximize validation performance, has achieved remarkable progress recently. In many application scenarios, several parties would like to collaboratively search for a shared neural architecture by leveraging data from all parties. However, due to privacy concerns, no party wants its data to be seen by other parties. To address this problem, we propose federated neural architecture search (FNAS), where different parties collectively search for a differentiable architecture by exchanging gradients of architecture variables without exposing their data to other parties. To further preserve privacy, we study differentially-private FNAS (DP-FNAS), which adds random noise to the gradients of architecture variables. We provide theoretical guarantees of DP-FNAS in achieving differential privacy. Experiments show that DP-FNAS can search highly-performant neural architectures while protecting the privacy of individual parties. The code is available at https://github.com/UCSD-AI4H/DP-FNAS