 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRoD: Full-Rank Efficient Fine-Tuning with Rotational Degrees for Fast Convergence
Dec 29, 2025Parameter-efficient fine-tuning (PEFT) methods have emerged as a practical solution for adapting large foundation models to downstream tasks, reducing computational and memory costs by updating only a small subset of parameters. Among them, approaches like LoRA aim to strike a balance between efficiency and expressiveness, but often suffer from slow convergence and limited adaptation capacity due to their inherent low-rank constraints. This trade-off hampers the ability of PEFT methods to capture complex patterns needed for diverse tasks. To address these challenges, we propose FRoD, a novel fine-tuning method that combines hierarchical joint decomposition with rotational degrees of freedom. By extracting a globally shared basis across layers and injecting sparse, learnable perturbations into scaling factors for flexible full-rank updates, FRoD enhances expressiveness and efficiency, leading to faster and more robust convergence. On 20 benchmarks spanning vision, reasoning, and language understanding, FRoD matches full model fine-tuning in accuracy, while using only 1.72% of trainable parameters under identical training budgets.
Towards Long-window Anchoring in Vision-Language Model Distillation
Dec 25, 2025While large vision-language models (VLMs) demonstrate strong long-context understanding, their prevalent small branches fail on linguistics-photography alignment for a limited window size. We discover that knowledge distillation improves students' capability as a complement to Rotary Position Embeddings (RoPE) on window sizes (anchored from large models). Building on this insight, we propose LAid, which directly aims at the transfer of long-range attention mechanisms through two complementary components: (1) a progressive distance-weighted attention matching that dynamically emphasizes longer position differences during training, and (2) a learnable RoPE response gain modulation that selectively amplifies position sensitivity where needed. Extensive experiments across multiple model families demonstrate that LAid-distilled models achieve up to 3.2 times longer effective context windows compared to baseline small models, while maintaining or improving performance on standard VL benchmarks. Spectral analysis also suggests that LAid successfully preserves crucial low-frequency attention components that conventional methods fail to transfer. Our work not only provides practical techniques for building more efficient long-context VLMs but also offers theoretical insights into how positional understanding emerges and transfers during distillation.
CodeDance: A Dynamic Tool-integrated MLLM for Executable Visual Reasoning
Dec 19, 2025Recent releases such as o3 highlight human-like "thinking with images" reasoning that combines structured tool use with stepwise verification, yet most open-source approaches still rely on text-only chains, rigid visual schemas, or single-step pipelines, limiting flexibility, interpretability, and transferability on complex tasks. We introduce CodeDance, which explores executable code as a general solver for visual reasoning. Unlike fixed-schema calls (e.g., only predicting bounding-box coordinates), CodeDance defines, composes, and executes code to orchestrate multiple tools, compute intermediate results, and render visual artifacts (e.g., boxes, lines, plots) that support transparent, self-checkable reasoning. To guide this process, we introduce a reward for balanced and adaptive tool-call, which balances exploration with efficiency and mitigates tool overuse. Interestingly, beyond the expected capabilities taught by atomic supervision, we empirically observe novel emergent behaviors during RL training: CodeDance demonstrates novel tool invocations, unseen compositions, and cross-task transfer. These behaviors arise without task-specific fine-tuning, suggesting a general and scalable mechanism of executable visual reasoning. Extensive experiments across reasoning benchmarks (e.g., visual search, math, chart QA) show that CodeDance not only consistently outperforms schema-driven and text-only baselines, but also surpasses advanced closed models such as GPT-4o and larger open-source models.
Fine-Tuned LLMs Know They Don't Know: A Parameter-Efficient Approach to Recovering Honesty
Nov 17, 2025The honesty of Large Language Models (LLMs) is increasingly important for safe deployment in high-stakes domains. However, this crucial trait is severely undermined by supervised fine-tuning (SFT), a common technique for model specialization. Existing recovery methods rely on data-intensive global parameter adjustments, implicitly assuming that SFT deeply corrupts the models' ability to recognize their knowledge boundaries. However, we observe that fine-tuned LLMs still preserve this ability; what is damaged is their capacity to faithfully express that awareness. Building on this, we propose Honesty-Critical Neurons Restoration (HCNR) to surgically repair this suppressed capacity. HCNR identifies and restores key expression-governing neurons to their pre-trained state while harmonizing them with task-oriented neurons via Hessian-guided compensation. Experiments on four QA tasks and five LLM families demonstrate that HCNR effectively recovers 33.25% of the compromised honesty while achieving at least 2.23x speedup with over 10x less data compared to baseline methods, offering a practical solution for trustworthy LLM deployment.
Towards Objective Fine-tuning: How LLMs' Prior Knowledge Causes Potential Poor Calibration?
May 27, 2025Fine-tuned Large Language Models (LLMs) often demonstrate poor calibration, with their confidence scores misaligned with actual performance. While calibration has been extensively studied in models trained from scratch, the impact of LLMs' prior knowledge on calibration during fine-tuning remains understudied. Our research reveals that LLMs' prior knowledge causes potential poor calibration due to the ubiquitous presence of known data in real-world fine-tuning, which appears harmful for calibration. Specifically, data aligned with LLMs' prior knowledge would induce overconfidence, while new knowledge improves calibration. Our findings expose a tension: LLMs' encyclopedic knowledge, while enabling task versatility, undermines calibration through unavoidable knowledge overlaps. To address this, we propose CogCalib, a cognition-aware framework that applies targeted learning strategies according to the model's prior knowledge. Experiments across 7 tasks using 3 LLM families prove that CogCalib significantly improves calibration while maintaining performance, achieving an average 57\% reduction in ECE compared to standard fine-tuning in Llama3-8B. These improvements generalize well to out-of-domain tasks, enhancing the objectivity and reliability of domain-specific LLMs, and making them more trustworthy for critical human-AI interaction applications.
FreqMoE: Dynamic Frequency Enhancement for Neural PDE Solvers
May 11, 2025Fourier Neural Operators (FNO) have emerged as promising solutions for efficiently solving partial differential equations (PDEs) by learning infinite-dimensional function mappings through frequency domain transformations. However, the sparsity of high-frequency signals limits computational efficiency for high-dimensional inputs, and fixed-pattern truncation often causes high-frequency signal loss, reducing performance in scenarios such as high-resolution inputs or long-term predictions. To address these challenges, we propose FreqMoE, an efficient and progressive training framework that exploits the dependency of high-frequency signals on low-frequency components. The model first learns low-frequency weights and then applies a sparse upward-cycling strategy to construct a mixture of experts (MoE) in the frequency domain, effectively extending the learned weights to high-frequency regions. Experiments on both regular and irregular grid PDEs demonstrate that FreqMoE achieves up to 16.6% accuracy improvement while using merely 2.1% parameters (47.32x reduction) compared to dense FNO. Furthermore, the approach demonstrates remarkable stability in long-term predictions and generalizes seamlessly to various FNO variants and grid structures, establishing a new ``Low frequency Pretraining, High frequency Fine-tuning'' paradigm for solving PDEs.
Galaxy Walker: Geometry-aware VLMs For Galaxy-scale Understanding
Mar 24, 2025Modern vision-language models (VLMs) develop patch embedding and convolution backbone within vector space, especially Euclidean ones, at the very founding. When expanding VLMs to a galaxy scale for understanding astronomical phenomena, the integration of spherical space for planetary orbits and hyperbolic spaces for black holes raises two formidable challenges. a) The current pre-training model is confined to Euclidean space rather than a comprehensive geometric embedding. b) The predominant architecture lacks suitable backbones for anisotropic physical geometries. In this paper, we introduced Galaxy-Walker, a geometry-aware VLM, for the universe-level vision understanding tasks. We proposed the geometry prompt that generates geometry tokens by random walks across diverse spaces on a multi-scale physical graph, along with a geometry adapter that compresses and reshapes the space anisotropy in a mixture-of-experts manner. Extensive experiments demonstrate the effectiveness of our approach, with Galaxy-Walker achieving state-of-the-art performance in both galaxy property estimation ($R^2$ scores up to $0.91$) and morphology classification tasks (up to $+0.17$ F1 improvement in challenging features), significantly outperforming both domain-specific models and general-purpose VLMs.
CLDG: Contrastive Learning on Dynamic Graphs
Dec 19, 2024



The graph with complex annotations is the most potent data type, whose constantly evolving motivates further exploration of the unsupervised dynamic graph representation. One of the representative paradigms is graph contrastive learning. It constructs self-supervised signals by maximizing the mutual information between the statistic graph's augmentation views. However, the semantics and labels may change within the augmentation process, causing a significant performance drop in downstream tasks. This drawback becomes greatly magnified on dynamic graphs. To address this problem, we designed a simple yet effective framework named CLDG. Firstly, we elaborate that dynamic graphs have temporal translation invariance at different levels. Then, we proposed a sampling layer to extract the temporally-persistent signals. It will encourage the node to maintain consistent local and global representations, i.e., temporal translation invariance under the timespan views. The extensive experiments demonstrate the effectiveness and efficiency of the method on seven datasets by outperforming eight unsupervised state-of-the-art baselines and showing competitiveness against four semi-supervised methods. Compared with the existing dynamic graph method, the number of model parameters and training time is reduced by an average of 2,001.86 times and 130.31 times on seven datasets, respectively.
From Text to Trajectory: Exploring Complex Constraint Representation and Decomposition in Safe Reinforcement Learning
Dec 12, 2024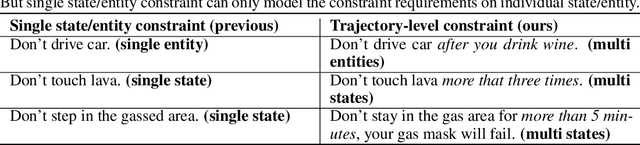
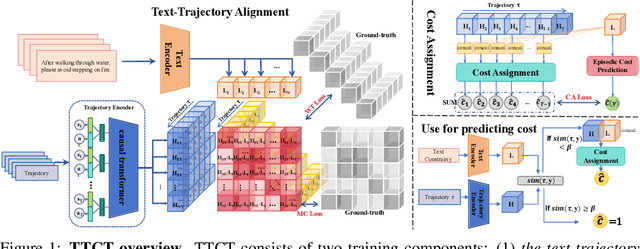
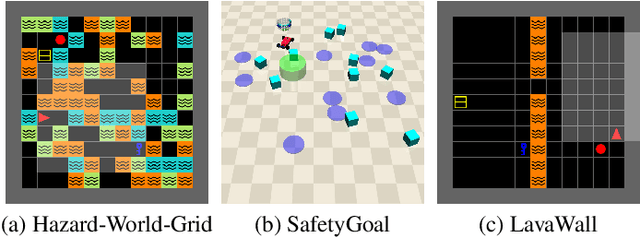

Safe reinforcement learning (RL) requires the agent to finish a given task while obeying specific constraints. Giving constraints in natural language form has great potential for practical scenarios due to its flexible transfer capability and accessibility. Previous safe RL methods with natural language constraints typically need to design cost functions manually for each constraint, which requires domain expertise and lacks flexibility. In this paper, we harness the dual role of text in this task, using it not only to provide constraint but also as a training signal. We introduce the Trajectory-level Textual Constraints Translator (TTCT) to replace the manually designed cost function. Our empirical results demonstrate that TTCT effectively comprehends textual constraint and trajectory, and the policies trained by TTCT can achieve a lower violation rate than the standard cost function. Extra studies are conducted to demonstrate that the TTCT has zero-shot transfer capability to adapt to constraint-shift environments.
Building Flexible Machine Learning Models for Scientific Computing at Scale
Feb 25, 2024Foundation models have revolutionized knowledge acquisition across domains, and our study introduces OmniArch, a paradigm-shifting approach designed for building foundation models in multi-physics scientific computing. OmniArch's pre-training involves a versatile pipeline that processes multi-physics spatio-temporal data, casting forward problem learning into scalable auto-regressive tasks, while our novel Physics-Informed Reinforcement Learning (PIRL) technique during fine-tuning ensures alignment with physical laws. Pre-trained on the comprehensive PDEBench dataset, OmniArch not only sets new performance benchmarks for 1D, 2D and 3D PDEs but also demonstrates exceptional adaptability to new physics via few-shot and zero-shot learning approaches. The model's representations further extend to inverse problem-solving, highlighting the transformative potential of AI-enabled Scientific Computing(AI4SC) foundation models for engineering applications and physics discovery.