 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreqMoE: Dynamic Frequency Enhancement for Neural PDE Solvers
May 11, 2025Fourier Neural Operators (FNO) have emerged as promising solutions for efficiently solving partial differential equations (PDEs) by learning infinite-dimensional function mappings through frequency domain transformations. However, the sparsity of high-frequency signals limits computational efficiency for high-dimensional inputs, and fixed-pattern truncation often causes high-frequency signal loss, reducing performance in scenarios such as high-resolution inputs or long-term predictions. To address these challenges, we propose FreqMoE, an efficient and progressive training framework that exploits the dependency of high-frequency signals on low-frequency components. The model first learns low-frequency weights and then applies a sparse upward-cycling strategy to construct a mixture of experts (MoE) in the frequency domain, effectively extending the learned weights to high-frequency regions. Experiments on both regular and irregular grid PDEs demonstrate that FreqMoE achieves up to 16.6% accuracy improvement while using merely 2.1% parameters (47.32x reduction) compared to dense FNO. Furthermore, the approach demonstrates remarkable stability in long-term predictions and generalizes seamlessly to various FNO variants and grid structures, establishing a new ``Low frequency Pretraining, High frequency Fine-tuning'' paradigm for solving PDEs.
From Text to Trajectory: Exploring Complex Constraint Representation and Decomposition in Safe Reinforcement Learning
Dec 12, 2024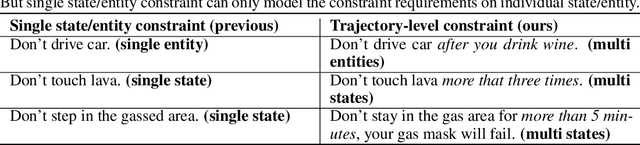
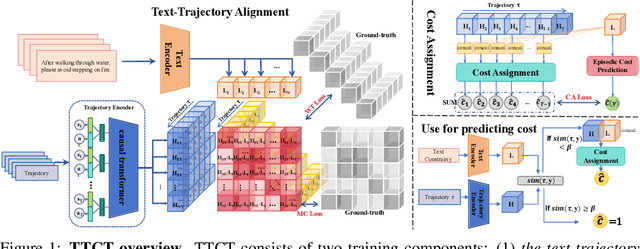
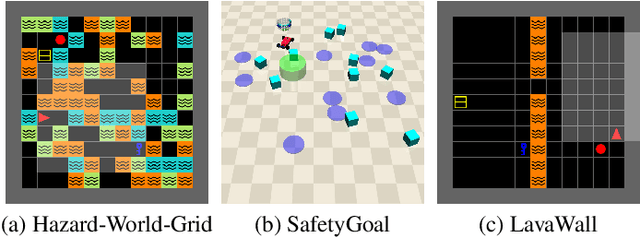

Safe reinforcement learning (RL) requires the agent to finish a given task while obeying specific constraints. Giving constraints in natural language form has great potential for practical scenarios due to its flexible transfer capability and accessibility. Previous safe RL methods with natural language constraints typically need to design cost functions manually for each constraint, which requires domain expertise and lacks flexibility. In this paper, we harness the dual role of text in this task, using it not only to provide constraint but also as a training signal. We introduce the Trajectory-level Textual Constraints Translator (TTCT) to replace the manually designed cost function. Our empirical results demonstrate that TTCT effectively comprehends textual constraint and trajectory, and the policies trained by TTCT can achieve a lower violation rate than the standard cost function. Extra studies are conducted to demonstrate that the TTCT has zero-shot transfer capability to adapt to constraint-shift environments.
Beyond Human Preferences: Exploring Reinforcement Learning Trajectory Evaluation and Improvement through LLMs
Jun 28, 2024



Reinforcement learning (RL) faces challenges in evaluating policy trajectories within intricate game tasks due to the difficulty in designing comprehensive and precise reward functions. This inherent difficulty curtails the broader application of RL within game environments characterized by diverse constraints. Preference-based reinforcement learning (PbRL) presents a pioneering framework that capitalizes on human preferences as pivotal reward signals, thereby circumventing the need for meticulous reward engineering. However, obtaining preference data from human experts is costly and inefficient, especially under conditions marked by complex constraints. To tackle this challenge, we propose a LLM-enabled automatic preference generation framework named LLM4PG , which harnesses the capabilities of large language models (LLMs) to abstract trajectories, rank preferences, and reconstruct reward functions to optimize conditioned policies. Experiments on tasks with complex language constraints demonstrated the effectiveness of our LLM-enabled reward functions, accelerating RL convergence and overcoming stagnation caused by slow or absent progress under original reward structures. This approach mitigates the reliance on specialized human knowledge and demonstrates the potential of LLMs to enhance RL's effectiveness in complex environments in the wild.