 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-Media Re-Ranker: A User Satisfaction-Driven LLM Re-ranking Framework for Rich-Media Search
Feb 05, 2026Re-ranking plays a crucial role in modern information search systems by refining the ranking of initial search results to better satisfy user information needs. However, existing methods show two notable limitations in improving user search satisfaction: inadequate modeling of multifaceted user intents and neglect of rich side information such as visual perception signals. To address these challenges, we propose the Rich-Media Re-Ranker framework, which aims to enhance user search satisfaction through multi-dimensional and fine-grained modeling. Our approach begins with a Query Planner that analyzes the sequence of query refinements within a session to capture genuine search intents, decomposing the query into clear and complementary sub-queries to enable broader coverage of users' potential intents. Subsequently, moving beyond primary text content, we integrate richer side information of candidate results, including signals modeling visual content generated by the VLM-based evaluator. These comprehensive signals are then processed alongside carefully designed re-ranking principle that considers multiple facets, including content relevance and quality, information gain, information novelty, and the visual presentation of cover images. Then, the LLM-based re-ranker performs the holistic evaluation based on these principles and integrated signals. To enhance the scenario adaptability of the VLM-based evaluator and the LLM-based re-ranker, we further enhance their capabilities through multi-task reinforcement learning. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art baselines. Notably, the proposed framework has been deployed in a large-scale industrial search system, yielding substantial improvements in online user engagement rates and satisfaction metrics.
RAG-GFM: Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation
Jan 24, 2026Graph Foundation Models (GFMs) have emerged as a frontier in graph learning, which are expected to deliver transferable representations across diverse tasks. However, GFMs remain constrained by in-memory bottlenecks: they attempt to encode knowledge into model parameters, which limits semantic capacity, introduces heavy lossy compression with conflicts, and entangles graph representation with the knowledge in ways that hinder efficient adaptation, undermining scalability and interpretability. In this work,we propose RAG-GFM, a Retrieval-Augmented Generation aided Graph Foundation Model that offloads knowledge from parameters and complements parameterized learning. To externalize graph knowledge, we build a dual-modal unified retrieval module, where a semantic store from prefix-structured text and a structural store from centrality-based motif. To preserve heterogeneous information, we design a dual-view alignment objective that contrasts both modalities to capture both content and relational patterns. To enable efficient downstream adaptation, we perform in-context augmentation to enrich supporting instances with retrieved texts and motifs as contextual evidence. Extensive experiments on five benchmark graph datasets demonstrate that RAG-GFM consistently outperforms 13 state-of-the-art baselines in both cross-domain node and graph classification, achieving superior effectiveness and efficiency.
Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation
Jan 21, 2026Graph Foundation Models (GFMs) have emerged as a frontier in graph learning, which are expected to deliver transferable representations across diverse tasks. However, GFMs remain constrained by in-memory bottlenecks: they attempt to encode knowledge into model parameters, which limits semantic capacity, introduces heavy lossy compression with conflicts, and entangles graph representation with the knowledge in ways that hinder efficient adaptation, undermining scalability and interpretability. In this work,we propose RAG-GFM, a Retrieval-Augmented Generation aided Graph Foundation Model that offloads knowledge from parameters and complements parameterized learning. To externalize graph knowledge, we build a dual-modal unified retrieval module, where a semantic store from prefix-structured text and a structural store from centrality-based motif. To preserve heterogeneous information, we design a dual-view alignment objective that contrasts both modalities to capture both content and relational patterns. To enable efficient downstream adaptation, we perform in-context augmentation to enrich supporting instances with retrieved texts and motifs as contextual evidence. Extensive experiments on five benchmark graph datasets demonstrate that RAG-GFM consistently outperforms 13 state-of-the-art baselines in both cross-domain node and graph classification, achieving superior effectiveness and efficiency.
Unlocking the Potentials of Retrieval-Augmented Generation for Diffusion Language Models
Jan 16, 2026Diffusion Language Models (DLMs) have recently demonstrated remarkable capabilities in natural language processing tasks. However, the potential of Retrieval-Augmented Generation (RAG), which shows great successes for enhancing large language models (LLMs), has not been well explored, due to the fundamental difference between LLM and DLM decoding. To fill this critical gap, we systematically test the performance of DLMs within the RAG framework. Our findings reveal that DLMs coupled with RAG show promising potentials with stronger dependency on contextual information, but suffer from limited generation precision. We identify a key underlying issue: Response Semantic Drift (RSD), where the generated answer progressively deviates from the query's original semantics, leading to low precision content. We trace this problem to the denoising strategies in DLMs, which fail to maintain semantic alignment with the query throughout the iterative denoising process. To address this, we propose Semantic-Preserving REtrieval-Augmented Diffusion (SPREAD), a novel framework that introduces a query-relevance-guided denoising strategy. By actively guiding the denoising trajectory, SPREAD ensures the generation remains anchored to the query's semantics and effectively suppresses drift. Experimental results demonstrate that SPREAD significantly enhances the precision and effectively mitigates RSD of generated answers within the RAG framework.
Is the Information Bottleneck Robust Enough? Towards Label-Noise Resistant Information Bottleneck Learning
Dec 11, 2025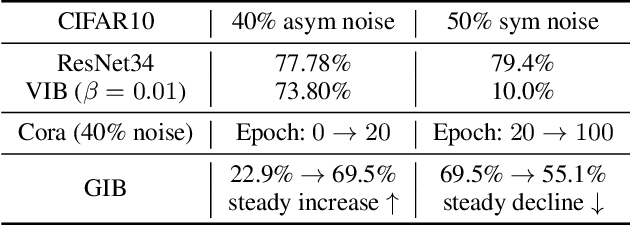
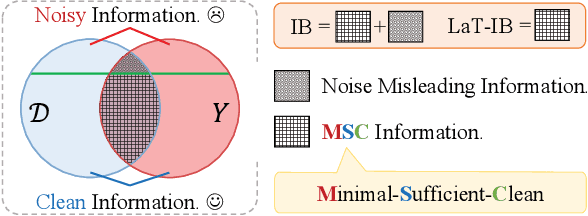
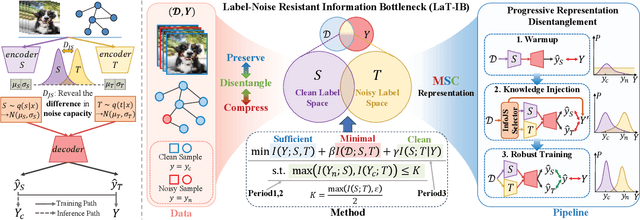
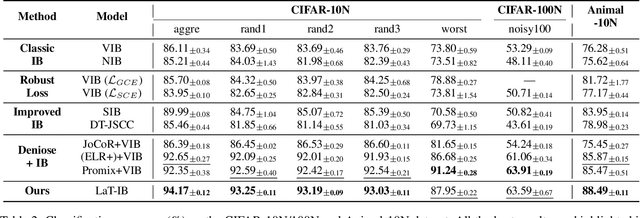
The Information Bottleneck (IB) principle facilitates effective representation learning by preserving label-relevant information while compressing irrelevant information. However, its strong reliance on accurate labels makes it inherently vulnerable to label noise, prevalent in real-world scenarios, resulting in significant performance degradation and overfitting. To address this issue, we propose LaT-IB, a novel Label-Noise ResistanT Information Bottleneck method which introduces a "Minimal-Sufficient-Clean" (MSC) criterion. Instantiated as a mutual information regularizer to retain task-relevant information while discarding noise, MSC addresses standard IB's vulnerability to noisy label supervision. To achieve this, LaT-IB employs a noise-aware latent disentanglement that decomposes the latent representation into components aligned with to the clean label space and the noise space. Theoretically, we first derive mutual information bounds for each component of our objective including prediction, compression, and disentanglement, and moreover prove that optimizing it encourages representations invariant to input noise and separates clean and noisy label information. Furthermore, we design a three-phase training framework: Warmup, Knowledge Injection and Robust Training, to progressively guide the model toward noise-resistant representations. Extensive experiments demonstrate that LaT-IB achieves superior robustness and efficiency under label noise, significantly enhancing robustness and applicability in real-world scenarios with label noise.
Fine-Tuned LLMs Know They Don't Know: A Parameter-Efficient Approach to Recovering Honesty
Nov 17, 2025The honesty of Large Language Models (LLMs) is increasingly important for safe deployment in high-stakes domains. However, this crucial trait is severely undermined by supervised fine-tuning (SFT), a common technique for model specialization. Existing recovery methods rely on data-intensive global parameter adjustments, implicitly assuming that SFT deeply corrupts the models' ability to recognize their knowledge boundaries. However, we observe that fine-tuned LLMs still preserve this ability; what is damaged is their capacity to faithfully express that awareness. Building on this, we propose Honesty-Critical Neurons Restoration (HCNR) to surgically repair this suppressed capacity. HCNR identifies and restores key expression-governing neurons to their pre-trained state while harmonizing them with task-oriented neurons via Hessian-guided compensation. Experiments on four QA tasks and five LLM families demonstrate that HCNR effectively recovers 33.25% of the compromised honesty while achieving at least 2.23x speedup with over 10x less data compared to baseline methods, offering a practical solution for trustworthy LLM deployment.
GRAVER: Generative Graph Vocabularies for Robust Graph Foundation Models Fine-tuning
Nov 05, 2025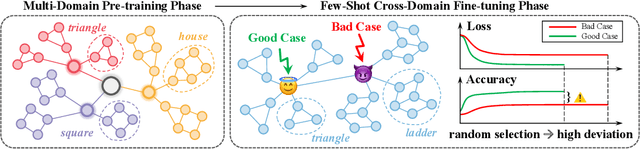
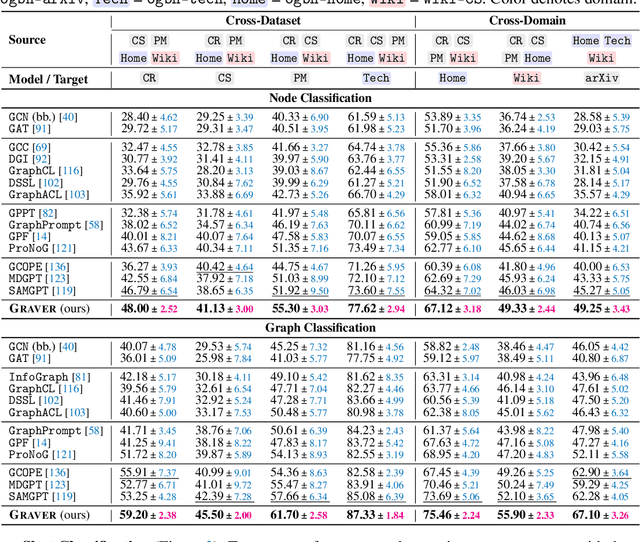
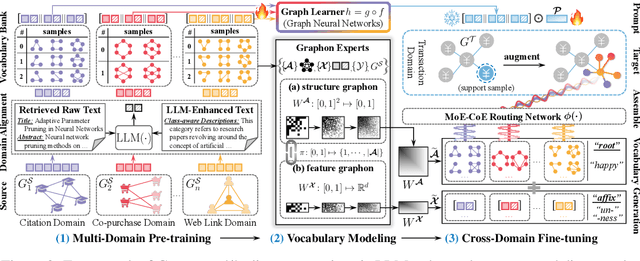
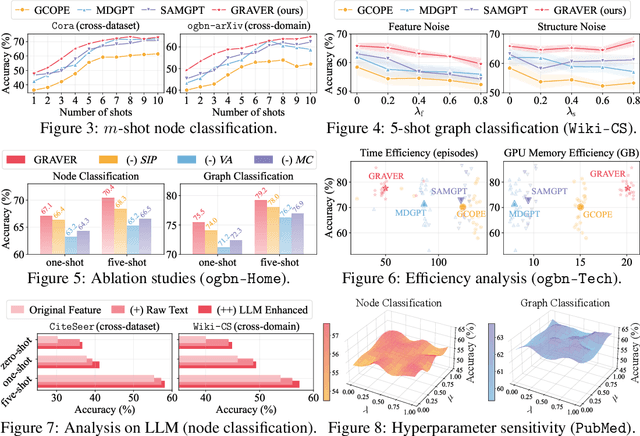
Inspired by the remarkable success of foundation models in language and vision, Graph Foundation Models (GFMs) hold significant promise for broad applicability across diverse graph tasks and domains. However, existing GFMs struggle with unstable few-shot fine-tuning, where both performance and adaptation efficiency exhibit significant fluctuations caused by the randomness in the support sample selection and structural discrepancies between the pre-trained and target graphs. How to fine-tune GFMs robustly and efficiently to enable trustworthy knowledge transfer across domains and tasks is the major challenge. In this paper, we propose GRAVER, a novel Generative gRAph VocabulariEs for Robust GFM fine-tuning framework that tackles the aforementioned instability via generative augmentations. Specifically, to identify transferable units, we analyze and extract key class-specific subgraph patterns by ego-graph disentanglement and validate their transferability both theoretically and empirically. To enable effective pre-training across diverse domains, we leverage a universal task template based on ego-graph similarity and construct graph vocabularies via graphon-based generative experts. To facilitate robust and efficient prompt fine-tuning, we grave the support samples with in-context vocabularies, where the lightweight MoE-CoE network attentively routes knowledge from source domains. Extensive experiments demonstrate the superiority of GRAVER over effectiveness, robustness, and efficiency on downstream few-shot node and graph classification tasks compared with 15 state-of-the-art baselines.
Robust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.
Toward a Unified Geometry Understanding: Riemannian Diffusion Framework for Graph Generation and Prediction
Oct 06, 2025Graph diffusion models have made significant progress in learning structured graph data and have demonstrated strong potential for predictive tasks. Existing approaches typically embed node, edge, and graph-level features into a unified latent space, modeling prediction tasks including classification and regression as a form of conditional generation. However, due to the non-Euclidean nature of graph data, features of different curvatures are entangled in the same latent space without releasing their geometric potential. To address this issue, we aim to construt an ideal Riemannian diffusion model to capture distinct manifold signatures of complex graph data and learn their distribution. This goal faces two challenges: numerical instability caused by exponential mapping during the encoding proces and manifold deviation during diffusion generation. To address these challenges, we propose GeoMancer: a novel Riemannian graph diffusion framework for both generation and prediction tasks. To mitigate numerical instability, we replace exponential mapping with an isometric-invariant Riemannian gyrokernel approach and decouple multi-level features onto their respective task-specific manifolds to learn optimal representations. To address manifold deviation, we introduce a manifold-constrained diffusion method and a self-guided strategy for unconditional generation, ensuring that the generated data remains aligned with the manifold signature. Extensive experiments validate the effectiveness of our approach, demonstrating superior performance across a variety of tasks.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.