 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Information Bottleneck Robust Enough? Towards Label-Noise Resistant Information Bottleneck Learning
Dec 11, 2025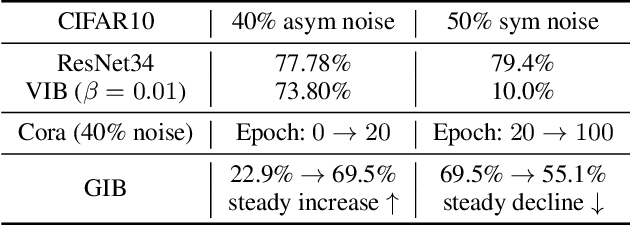
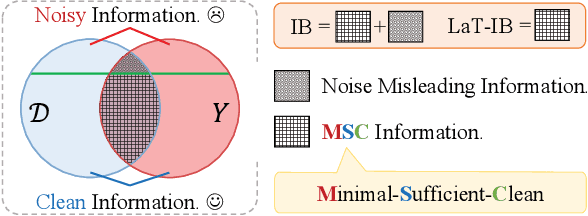
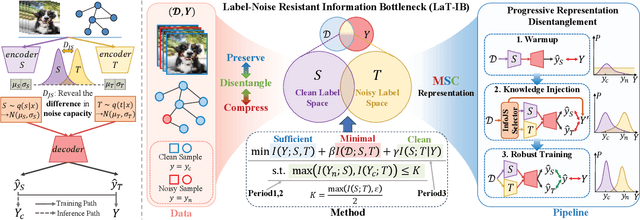
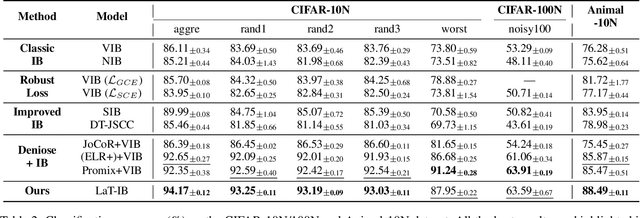
The Information Bottleneck (IB) principle facilitates effective representation learning by preserving label-relevant information while compressing irrelevant information. However, its strong reliance on accurate labels makes it inherently vulnerable to label noise, prevalent in real-world scenarios, resulting in significant performance degradation and overfitting. To address this issue, we propose LaT-IB, a novel Label-Noise ResistanT Information Bottleneck method which introduces a "Minimal-Sufficient-Clean" (MSC) criterion. Instantiated as a mutual information regularizer to retain task-relevant information while discarding noise, MSC addresses standard IB's vulnerability to noisy label supervision. To achieve this, LaT-IB employs a noise-aware latent disentanglement that decomposes the latent representation into components aligned with to the clean label space and the noise space. Theoretically, we first derive mutual information bounds for each component of our objective including prediction, compression, and disentanglement, and moreover prove that optimizing it encourages representations invariant to input noise and separates clean and noisy label information. Furthermore, we design a three-phase training framework: Warmup, Knowledge Injection and Robust Training, to progressively guide the model toward noise-resistant representations. Extensive experiments demonstrate that LaT-IB achieves superior robustness and efficiency under label noise, significantly enhancing robustness and applicability in real-world scenarios with label noise.
Toward a Unified Geometry Understanding: Riemannian Diffusion Framework for Graph Generation and Prediction
Oct 06, 2025Graph diffusion models have made significant progress in learning structured graph data and have demonstrated strong potential for predictive tasks. Existing approaches typically embed node, edge, and graph-level features into a unified latent space, modeling prediction tasks including classification and regression as a form of conditional generation. However, due to the non-Euclidean nature of graph data, features of different curvatures are entangled in the same latent space without releasing their geometric potential. To address this issue, we aim to construt an ideal Riemannian diffusion model to capture distinct manifold signatures of complex graph data and learn their distribution. This goal faces two challenges: numerical instability caused by exponential mapping during the encoding proces and manifold deviation during diffusion generation. To address these challenges, we propose GeoMancer: a novel Riemannian graph diffusion framework for both generation and prediction tasks. To mitigate numerical instability, we replace exponential mapping with an isometric-invariant Riemannian gyrokernel approach and decouple multi-level features onto their respective task-specific manifolds to learn optimal representations. To address manifold deviation, we introduce a manifold-constrained diffusion method and a self-guided strategy for unconditional generation, ensuring that the generated data remains aligned with the manifold signature. Extensive experiments validate the effectiveness of our approach, demonstrating superior performance across a variety of tasks.
Controllable Logical Hypothesis Generation for Abductive Reasoning in Knowledge Graphs
May 27, 2025Abductive reasoning in knowledge graphs aims to generate plausible logical hypotheses from observed entities, with broad applications in areas such as clinical diagnosis and scientific discovery. However, due to a lack of controllability, a single observation may yield numerous plausible but redundant or irrelevant hypotheses on large-scale knowledge graphs. To address this limitation, we introduce the task of controllable hypothesis generation to improve the practical utility of abductive reasoning. This task faces two key challenges when controlling for generating long and complex logical hypotheses: hypothesis space collapse and hypothesis oversensitivity. To address these challenges, we propose CtrlHGen, a Controllable logcial Hypothesis Generation framework for abductive reasoning over knowledge graphs, trained in a two-stage paradigm including supervised learning and subsequent reinforcement learning. To mitigate hypothesis space collapse, we design a dataset augmentation strategy based on sub-logical decomposition, enabling the model to learn complex logical structures by leveraging semantic patterns in simpler components. To address hypothesis oversensitivity, we incorporate smoothed semantic rewards including Dice and Overlap scores, and introduce a condition-adherence reward to guide the generation toward user-specified control constraints. Extensive experiments on three benchmark datasets demonstrate that our model not only better adheres to control conditions but also achieves superior semantic similarity performance compared to baselines.
Galaxy Walker: Geometry-aware VLMs For Galaxy-scale Understanding
Mar 24, 2025Modern vision-language models (VLMs) develop patch embedding and convolution backbone within vector space, especially Euclidean ones, at the very founding. When expanding VLMs to a galaxy scale for understanding astronomical phenomena, the integration of spherical space for planetary orbits and hyperbolic spaces for black holes raises two formidable challenges. a) The current pre-training model is confined to Euclidean space rather than a comprehensive geometric embedding. b) The predominant architecture lacks suitable backbones for anisotropic physical geometries. In this paper, we introduced Galaxy-Walker, a geometry-aware VLM, for the universe-level vision understanding tasks. We proposed the geometry prompt that generates geometry tokens by random walks across diverse spaces on a multi-scale physical graph, along with a geometry adapter that compresses and reshapes the space anisotropy in a mixture-of-experts manner. Extensive experiments demonstrate the effectiveness of our approach, with Galaxy-Walker achieving state-of-the-art performance in both galaxy property estimation ($R^2$ scores up to $0.91$) and morphology classification tasks (up to $+0.17$ F1 improvement in challenging features), significantly outperforming both domain-specific models and general-purpose VLMs.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025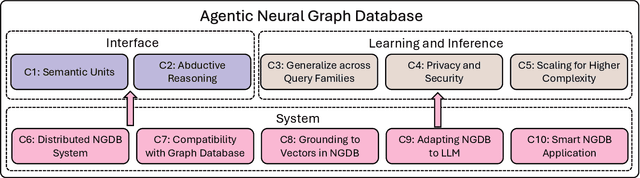
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Discrete Curvature Graph Information Bottleneck
Dec 28, 2024Graph neural networks(GNNs) have been demonstrated to depend on whether the node effective information is sufficiently passing. Discrete curvature (Ricci curvature) is used to study graph connectivity and information propagation efficiency with a geometric perspective, and has been raised in recent years to explore the efficient message-passing structure of GNNs. However, most empirical studies are based on directly observed graph structures or heuristic topological assumptions and lack in-depth exploration of underlying optimal information transport structures for downstream tasks. We suggest that graph curvature optimization is more in-depth and essential than directly rewiring or learning for graph structure with richer message-passing characterization and better information transport interpretability. From both graph geometry and information theory perspectives, we propose the novel Discrete Curvature Graph Information Bottleneck (CurvGIB) framework to optimize the information transport structure and learn better node representations simultaneously. CurvGIB advances the Variational Information Bottleneck (VIB) principle for Ricci curvature optimization to learn the optimal information transport pattern for specific downstream tasks. The learned Ricci curvature is used to refine the optimal transport structure of the graph, and the node representation is fully and efficiently learned. Moreover, for the computational complexity of Ricci curvature differentiation, we combine Ricci flow and VIB to deduce a curvature optimization approximation to form a tractable IB objective function. Extensive experiments on various datasets demonstrate the superior effectiveness and interpretability of CurvGIB.
Bi-Directional Multi-Scale Graph Dataset Condensation via Information Bottleneck
Dec 23, 2024Dataset condensation has significantly improved model training efficiency, but its application on devices with different computing power brings new requirements for different data sizes. Thus, condensing multiple scale graphs simultaneously is the core of achieving efficient training in different on-device scenarios. Existing efficient works for multi-scale graph dataset condensation mainly perform efficient approximate computation in scale order (large-to-small or small-to-large scales). However, for non-Euclidean structures of sparse graph data, these two commonly used paradigms for multi-scale graph dataset condensation have serious scaling down degradation and scaling up collapse problems of a graph. The main bottleneck of the above paradigms is whether the effective information of the original graph is fully preserved when consenting to the primary sub-scale (the first of multiple scales), which determines the condensation effect and consistency of all scales. In this paper, we proposed a novel GNN-centric Bi-directional Multi-Scale Graph Dataset Condensation (BiMSGC) framework, to explore unifying paradigms by operating on both large-to-small and small-to-large for multi-scale graph condensation. Based on the mutual information theory, we estimate an optimal ``meso-scale'' to obtain the minimum necessary dense graph preserving the maximum utility information of the original graph, and then we achieve stable and consistent ``bi-directional'' condensation learning by optimizing graph eigenbasis matching with information bottleneck on other scales. Encouraging empirical results on several datasets demonstrates the significant superiority of the proposed framework in graph condensation at different scales.
GraphMoRE: Mitigating Topological Heterogeneity via Mixture of Riemannian Experts
Dec 15, 2024



Real-world graphs have inherently complex and diverse topological patterns, known as topological heterogeneity. Most existing works learn graph representation in a single constant curvature space that is insufficient to match the complex geometric shapes, resulting in low-quality embeddings with high distortion. This also constitutes a critical challenge for graph foundation models, which are expected to uniformly handle a wide variety of diverse graph data. Recent studies have indicated that product manifold gains the possibility to address topological heterogeneity. However, the product manifold is still homogeneous, which is inadequate and inflexible for representing the mixed heterogeneous topology. In this paper, we propose a novel Graph Mixture of Riemannian Experts (GraphMoRE) framework to effectively tackle topological heterogeneity by personalized fine-grained topology geometry pattern preservation. Specifically, to minimize the embedding distortion, we propose a topology-aware gating mechanism to select the optimal embedding space for each node. By fusing the outputs of diverse Riemannian experts with learned gating weights, we construct personalized mixed curvature spaces for nodes, effectively embedding the graph into a heterogeneous manifold with varying curvatures at different points. Furthermore, to fairly measure pairwise distances between different embedding spaces, we present a concise and effective alignment strategy. Extensive experiments on real-world and synthetic datasets demonstrate that our method achieves superior performance with lower distortion, highlighting its potential for modeling complex graphs with topological heterogeneity, and providing a novel architectural perspective for graph foundation models.
Hyperbolic Geometric Latent Diffusion Model for Graph Generation
May 06, 2024Diffusion models have made significant contributions to computer vision, sparking a growing interest in the community recently regarding the application of them to graph generation. Existing discrete graph diffusion models exhibit heightened computational complexity and diminished training efficiency. A preferable and natural way is to directly diffuse the graph within the latent space. However, due to the non-Euclidean structure of graphs is not isotropic in the latent space, the existing latent diffusion models effectively make it difficult to capture and preserve the topological information of graphs. To address the above challenges, we propose a novel geometrically latent diffusion framework HypDiff. Specifically, we first establish a geometrically latent space with interpretability measures based on hyperbolic geometry, to define anisotropic latent diffusion processes for graphs. Then, we propose a geometrically latent diffusion process that is constrained by both radial and angular geometric properties, thereby ensuring the preservation of the original topological properties in the generative graphs. Extensive experimental results demonstrate the superior effectiveness of HypDiff for graph generation with various topologies.