 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled and Divergence-Conditioned Prompt for Multi-domain Dynamic Graph Foundation Models
May 13, 2026Dynamic graphs are ubiquitous in real-world systems, and building generalizable dynamic Graph Foundation Models has become a frontier in graph learning. However, dynamic graphs from different domains pose fundamental challenges to unified modeling, as their semantic and temporal patterns are inherently inconsistent, making the multi-domain pre-training difficult. Consequently, the widely used "pretrain-then-finetune" paradigm often suffers from severe negative knowledge transfer. To the best of our knowledge, there exists no multi-domain dynamic GFM. In this work, we propose DyGFM, a Dynamic Graph Foundation Model over multiple domains based on decoupled and divergence-conditioned prompting. To disentangle transferable semantics from the domain-specific dynamics, we introduce a dual-branch pre-training strategy with semantic-temporal decoupling. To alleviate negative transfer during domain adaptation, we further develop a cross-domain routing mechanism with divergence-aware expert selection. To enable efficient downstream fine-tuning, we design a divergence-conditioned prompt generator that injects lightweight, learnable graph prompts tailored to semantic and temporal traits. Extensive experiments on continuous dynamic graph benchmarks demonstrate that DyGFM consistently outperforms 12 state-of-the-art baselines on both node classification and link prediction tasks, achieving superior effectiveness and efficiency.
Towards LLM-Empowered Knowledge Tracing via LLM-Student Hierarchical Behavior Alignment in Hyperbolic Space
Feb 26, 2026Knowledge Tracing (KT) diagnoses students' concept mastery through continuous learning state monitoring in education.Existing methods primarily focus on studying behavioral sequences based on ID or textual information.While existing methods rely on ID-based sequences or shallow textual features, they often fail to capture (1) the hierarchical evolution of cognitive states and (2) individualized problem difficulty perception due to limited semantic modeling. Therefore, this paper proposes a Large Language Model Hyperbolic Aligned Knowledge Tracing(L-HAKT). First, the teacher agent deeply parses question semantics and explicitly constructs hierarchical dependencies of knowledge points; the student agent simulates learning behaviors to generate synthetic data. Then, contrastive learning is performed between synthetic and real data in hyperbolic space to reduce distribution differences in key features such as question difficulty and forgetting patterns. Finally, by optimizing hyperbolic curvature, we explicitly model the tree-like hierarchical structure of knowledge points, precisely characterizing differences in learning curve morphology for knowledge points at different levels. Extensive experiments on four real-world educational datasets validate the effectiveness of our Large Language Model Hyperbolic Aligned Knowledge Tracing (L-HAKT) framework.
Zero-shot Generalizable Graph Anomaly Detection with Mixture of Riemannian Experts
Feb 09, 2026Graph Anomaly Detection (GAD) aims to identify irregular patterns in graph data, and recent works have explored zero-shot generalist GAD to enable generalization to unseen graph datasets. However, existing zero-shot GAD methods largely ignore intrinsic geometric differences across diverse anomaly patterns, substantially limiting their cross-domain generalization. In this work, we reveal that anomaly detectability is highly dependent on the underlying geometric properties and that embedding graphs from different domains into a single static curvature space can distort the structural signatures of anomalies. To address the challenge that a single curvature space cannot capture geometry-dependent graph anomaly patterns, we propose GAD-MoRE, a novel framework for zero-shot Generalizable Graph Anomaly Detection with a Mixture of Riemannian Experts architecture. Specifically, to ensure that each anomaly pattern is modeled in the Riemannian space where it is most detectable, GAD-MoRE employs a set of specialized Riemannian expert networks, each operating in a distinct curvature space. To align raw node features with curvature-specific anomaly characteristics, we introduce an anomaly-aware multi-curvature feature alignment module that projects inputs into parallel Riemannian spaces, enabling the capture of diverse geometric characteristics. Finally, to facilitate better generalization beyond seen patterns, we design a memory-based dynamic router that adaptively assigns each input to the most compatible expert based on historical reconstruction performance on similar anomalies. Extensive experiments in the zero-shot setting demonstrate that GAD-MoRE significantly outperforms state-of-the-art generalist GAD baselines, and even surpasses strong competitors that are few-shot fine-tuned with labeled data from the target domain.
RAG-GFM: Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation
Jan 24, 2026Graph Foundation Models (GFMs) have emerged as a frontier in graph learning, which are expected to deliver transferable representations across diverse tasks. However, GFMs remain constrained by in-memory bottlenecks: they attempt to encode knowledge into model parameters, which limits semantic capacity, introduces heavy lossy compression with conflicts, and entangles graph representation with the knowledge in ways that hinder efficient adaptation, undermining scalability and interpretability. In this work,we propose RAG-GFM, a Retrieval-Augmented Generation aided Graph Foundation Model that offloads knowledge from parameters and complements parameterized learning. To externalize graph knowledge, we build a dual-modal unified retrieval module, where a semantic store from prefix-structured text and a structural store from centrality-based motif. To preserve heterogeneous information, we design a dual-view alignment objective that contrasts both modalities to capture both content and relational patterns. To enable efficient downstream adaptation, we perform in-context augmentation to enrich supporting instances with retrieved texts and motifs as contextual evidence. Extensive experiments on five benchmark graph datasets demonstrate that RAG-GFM consistently outperforms 13 state-of-the-art baselines in both cross-domain node and graph classification, achieving superior effectiveness and efficiency.
Overcoming In-Memory Bottlenecks in Graph Foundation Models via Retrieval-Augmented Generation
Jan 21, 2026Graph Foundation Models (GFMs) have emerged as a frontier in graph learning, which are expected to deliver transferable representations across diverse tasks. However, GFMs remain constrained by in-memory bottlenecks: they attempt to encode knowledge into model parameters, which limits semantic capacity, introduces heavy lossy compression with conflicts, and entangles graph representation with the knowledge in ways that hinder efficient adaptation, undermining scalability and interpretability. In this work,we propose RAG-GFM, a Retrieval-Augmented Generation aided Graph Foundation Model that offloads knowledge from parameters and complements parameterized learning. To externalize graph knowledge, we build a dual-modal unified retrieval module, where a semantic store from prefix-structured text and a structural store from centrality-based motif. To preserve heterogeneous information, we design a dual-view alignment objective that contrasts both modalities to capture both content and relational patterns. To enable efficient downstream adaptation, we perform in-context augmentation to enrich supporting instances with retrieved texts and motifs as contextual evidence. Extensive experiments on five benchmark graph datasets demonstrate that RAG-GFM consistently outperforms 13 state-of-the-art baselines in both cross-domain node and graph classification, achieving superior effectiveness and efficiency.
Is the Information Bottleneck Robust Enough? Towards Label-Noise Resistant Information Bottleneck Learning
Dec 11, 2025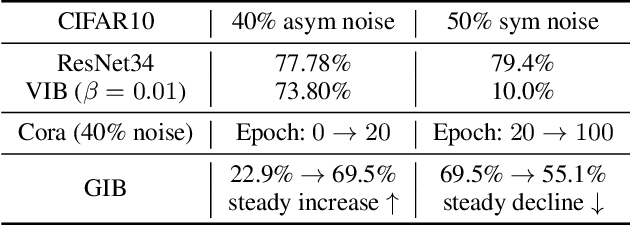
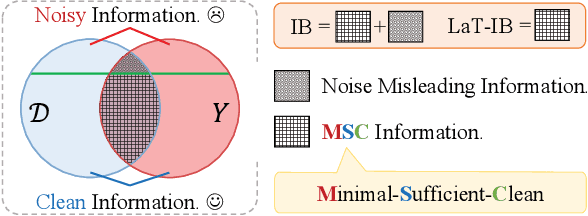
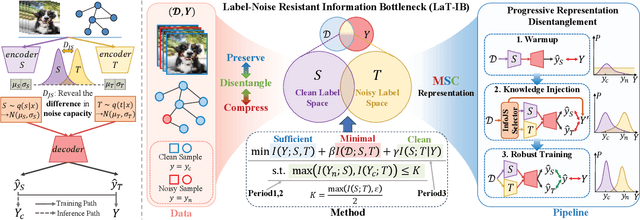
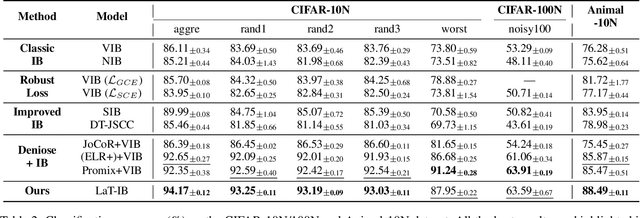
The Information Bottleneck (IB) principle facilitates effective representation learning by preserving label-relevant information while compressing irrelevant information. However, its strong reliance on accurate labels makes it inherently vulnerable to label noise, prevalent in real-world scenarios, resulting in significant performance degradation and overfitting. To address this issue, we propose LaT-IB, a novel Label-Noise ResistanT Information Bottleneck method which introduces a "Minimal-Sufficient-Clean" (MSC) criterion. Instantiated as a mutual information regularizer to retain task-relevant information while discarding noise, MSC addresses standard IB's vulnerability to noisy label supervision. To achieve this, LaT-IB employs a noise-aware latent disentanglement that decomposes the latent representation into components aligned with to the clean label space and the noise space. Theoretically, we first derive mutual information bounds for each component of our objective including prediction, compression, and disentanglement, and moreover prove that optimizing it encourages representations invariant to input noise and separates clean and noisy label information. Furthermore, we design a three-phase training framework: Warmup, Knowledge Injection and Robust Training, to progressively guide the model toward noise-resistant representations. Extensive experiments demonstrate that LaT-IB achieves superior robustness and efficiency under label noise, significantly enhancing robustness and applicability in real-world scenarios with label noise.
GRAVER: Generative Graph Vocabularies for Robust Graph Foundation Models Fine-tuning
Nov 05, 2025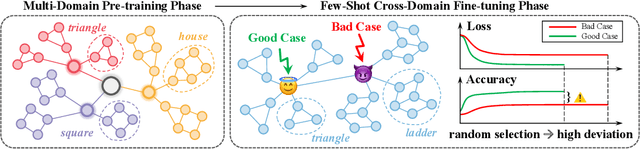
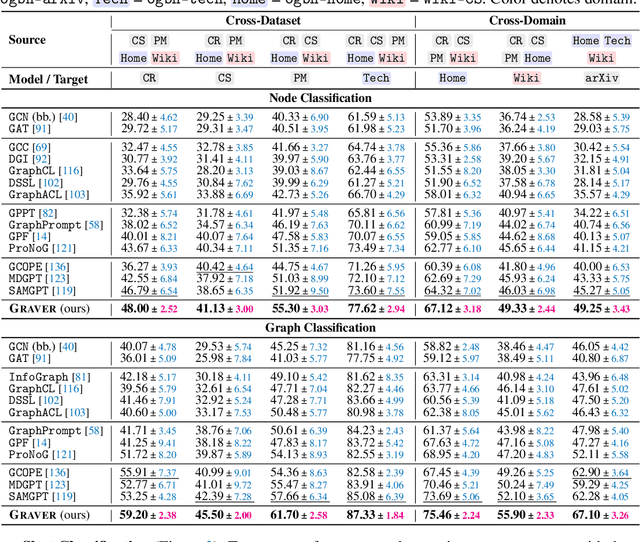
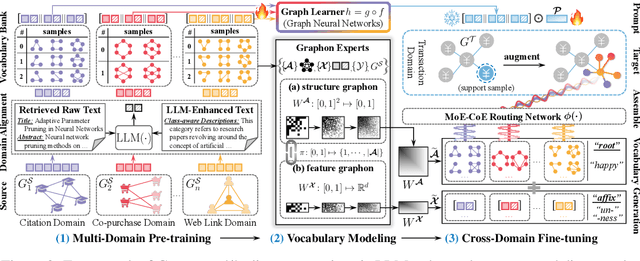
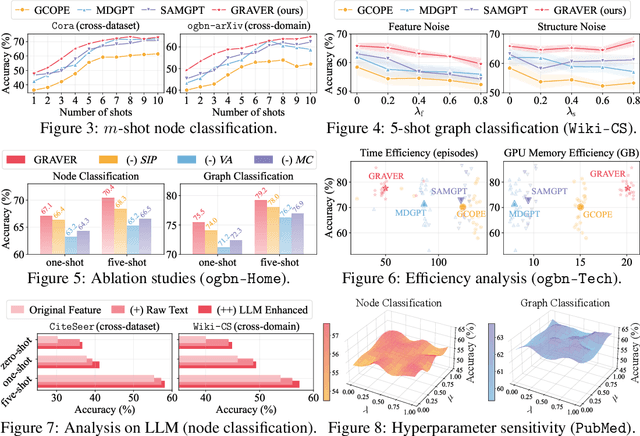
Inspired by the remarkable success of foundation models in language and vision, Graph Foundation Models (GFMs) hold significant promise for broad applicability across diverse graph tasks and domains. However, existing GFMs struggle with unstable few-shot fine-tuning, where both performance and adaptation efficiency exhibit significant fluctuations caused by the randomness in the support sample selection and structural discrepancies between the pre-trained and target graphs. How to fine-tune GFMs robustly and efficiently to enable trustworthy knowledge transfer across domains and tasks is the major challenge. In this paper, we propose GRAVER, a novel Generative gRAph VocabulariEs for Robust GFM fine-tuning framework that tackles the aforementioned instability via generative augmentations. Specifically, to identify transferable units, we analyze and extract key class-specific subgraph patterns by ego-graph disentanglement and validate their transferability both theoretically and empirically. To enable effective pre-training across diverse domains, we leverage a universal task template based on ego-graph similarity and construct graph vocabularies via graphon-based generative experts. To facilitate robust and efficient prompt fine-tuning, we grave the support samples with in-context vocabularies, where the lightweight MoE-CoE network attentively routes knowledge from source domains. Extensive experiments demonstrate the superiority of GRAVER over effectiveness, robustness, and efficiency on downstream few-shot node and graph classification tasks compared with 15 state-of-the-art baselines.
Robust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.
Toward a Unified Geometry Understanding: Riemannian Diffusion Framework for Graph Generation and Prediction
Oct 06, 2025Graph diffusion models have made significant progress in learning structured graph data and have demonstrated strong potential for predictive tasks. Existing approaches typically embed node, edge, and graph-level features into a unified latent space, modeling prediction tasks including classification and regression as a form of conditional generation. However, due to the non-Euclidean nature of graph data, features of different curvatures are entangled in the same latent space without releasing their geometric potential. To address this issue, we aim to construt an ideal Riemannian diffusion model to capture distinct manifold signatures of complex graph data and learn their distribution. This goal faces two challenges: numerical instability caused by exponential mapping during the encoding proces and manifold deviation during diffusion generation. To address these challenges, we propose GeoMancer: a novel Riemannian graph diffusion framework for both generation and prediction tasks. To mitigate numerical instability, we replace exponential mapping with an isometric-invariant Riemannian gyrokernel approach and decouple multi-level features onto their respective task-specific manifolds to learn optimal representations. To address manifold deviation, we introduce a manifold-constrained diffusion method and a self-guided strategy for unconditional generation, ensuring that the generated data remains aligned with the manifold signature. Extensive experiments validate the effectiveness of our approach, demonstrating superior performance across a variety of tasks.
Mitigating Message Imbalance in Fraud Detection with Dual-View Graph Representation Learning
Jul 09, 2025Graph representation learning has become a mainstream method for fraud detection due to its strong expressive power, which focuses on enhancing node representations through improved neighborhood knowledge capture. However, the focus on local interactions leads to imbalanced transmission of global topological information and increased risk of node-specific information being overwhelmed during aggregation due to the imbalance between fraud and benign nodes. In this paper, we first summarize the impact of topology and class imbalance on downstream tasks in GNN-based fraud detection, as the problem of imbalanced supervisory messages is caused by fraudsters' topological behavior obfuscation and identity feature concealment. Based on statistical validation, we propose a novel dual-view graph representation learning method to mitigate Message imbalance in Fraud Detection(MimbFD). Specifically, we design a topological message reachability module for high-quality node representation learning to penetrate fraudsters' camouflage and alleviate insufficient propagation. Then, we introduce a local confounding debiasing module to adjust node representations, enhancing the stable association between node representations and labels to balance the influence of different classes. Finally, we conducted experiments on three public fraud datasets, and the results demonstrate that MimbFD exhibits outstanding performance in fraud detection.