 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI as a Cybersecurity Attack Surface: Threats, Exploits, and Defenses in Runtime Supply Chains
Feb 23, 2026Agentic systems built on large language models (LLMs) extend beyond text generation to autonomously retrieve information and invoke tools. This runtime execution model shifts the attack surface from build-time artifacts to inference-time dependencies, exposing agents to manipulation through untrusted data and probabilistic capability resolution. While prior work has focused on model-level vulnerabilities, security risks emerging from cyclic and interdependent runtime behavior remain fragmented. We systematize these risks within a unified runtime framework, categorizing threats into data supply chain attacks (transient context injection and persistent memory poisoning) and tool supply chain attacks (discovery, implementation, and invocation). We further identify the Viral Agent Loop, in which agents act as vectors for self-propagating generative worms without exploiting code-level flaws. Finally, we advocate a Zero-Trust Runtime Architecture that treats context as untrusted control flow and constrains tool execution through cryptographic provenance rather than semantic inference.
Cross-Cloud Data Privacy Protection: Optimizing Collaborative Mechanisms of AI Systems by Integrating Federated Learning and LLMs
May 19, 2025


In the age of cloud computing, data privacy protection has become a major challenge, especially when sharing sensitive data across cloud environments. However, how to optimize collaboration across cloud environments remains an unresolved problem. In this paper, we combine federated learning with large-scale language models to optimize the collaborative mechanism of AI systems. Based on the existing federated learning framework, we introduce a cross-cloud architecture in which federated learning works by aggregating model updates from decentralized nodes without exposing the original data. At the same time, combined with large-scale language models, its powerful context and semantic understanding capabilities are used to improve model training efficiency and decision-making ability. We've further innovated by introducing a secure communication layer to ensure the privacy and integrity of model updates and training data. The model enables continuous model adaptation and fine-tuning across different cloud environments while protecting sensitive data. Experimental results show that the proposed method is significantly better than the traditional federated learning model in terms of accuracy, convergence speed and data privacy protection.
Cloud-Based AI Systems: Leveraging Large Language Models for Intelligent Fault Detection and Autonomous Self-Healing
May 16, 2025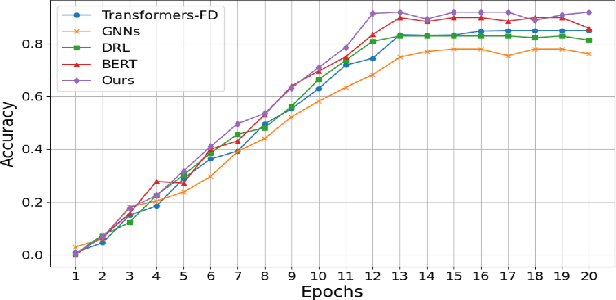
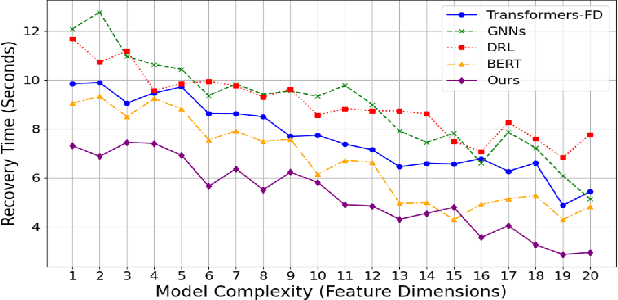
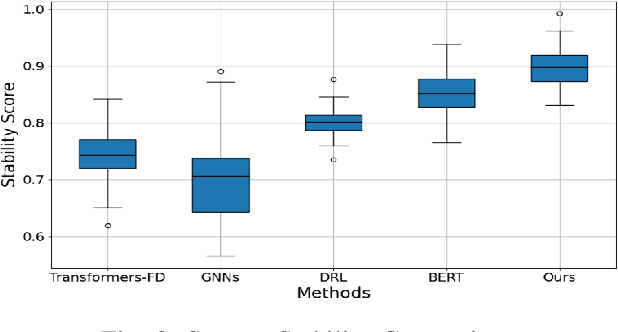
With the rapid development of cloud computing systems and the increasing complexity of their infrastructure, intelligent mechanisms to detect and mitigate failures in real time are becoming increasingly important. Traditional methods of failure detection are often difficult to cope with the scale and dynamics of modern cloud environments. In this study, we propose a novel AI framework based on Massive Language Model (LLM) for intelligent fault detection and self-healing mechanisms in cloud systems. The model combines existing machine learning fault detection algorithms with LLM's natural language understanding capabilities to process and parse system logs, error reports, and real-time data streams through semantic context. The method adopts a multi-level architecture, combined with supervised learning for fault classification and unsupervised learning for anomaly detection, so that the system can predict potential failures before they occur and automatically trigger the self-healing mechanism. Experimental results show that the proposed model is significantly better than the traditional fault detection system in terms of fault detection accuracy, system downtime reduction and recovery speed.
Data Augmentation Through Random Style Replacement
Apr 14, 2025In this paper, we introduce a novel data augmentation technique that combines the advantages of style augmentation and random erasing by selectively replacing image subregions with style-transferred patches. Our approach first applies a random style transfer to training images, then randomly substitutes selected areas of these images with patches derived from the style-transferred versions. This method is able to seamlessly accommodate a wide range of existing style transfer algorithms and can be readily integrated into diverse data augmentation pipelines. By incorporating our strategy, the training process becomes more robust and less prone to overfitting. Comparative experiments demonstrate that, relative to previous style augmentation methods, our technique achieves superior performance and faster convergence.
Graph Size-imbalanced Learning with Energy-guided Structural Smoothing
Dec 23, 2024



Graph is a prevalent data structure employed to represent the relationships between entities, frequently serving as a tool to depict and simulate numerous systems, such as molecules and social networks. However, real-world graphs usually suffer from the size-imbalanced problem in the multi-graph classification, i.e., a long-tailed distribution with respect to the number of nodes. Recent studies find that off-the-shelf Graph Neural Networks (GNNs) would compromise model performance under the long-tailed settings. We investigate this phenomenon and discover that the long-tailed graph distribution greatly exacerbates the discrepancies in structural features. To alleviate this problem, we propose a novel energy-based size-imbalanced learning framework named \textbf{SIMBA}, which smooths the features between head and tail graphs and re-weights them based on the energy propagation. Specifically, we construct a higher-level graph abstraction named \textit{Graphs-to-Graph} according to the correlations between graphs to link independent graphs and smooths the structural discrepancies. We further devise an energy-based message-passing belief propagation method for re-weighting lower compatible graphs in the training process and further smooth local feature discrepancies. Extensive experimental results over five public size-imbalanced datasets demonstrate the superior effectiveness of the model for size-imbalanced graph classification tasks.
DG-Mamba: Robust and Efficient Dynamic Graph Structure Learning with Selective State Space Models
Dec 11, 2024



Dynamic graphs exhibit intertwined spatio-temporal evolutionary patterns, widely existing in the real world. Nevertheless, the structure incompleteness, noise, and redundancy result in poor robustness for Dynamic Graph Neural Networks (DGNNs). Dynamic Graph Structure Learning (DGSL) offers a promising way to optimize graph structures. However, aside from encountering unacceptable quadratic complexity, it overly relies on heuristic priors, making it hard to discover underlying predictive patterns. How to efficiently refine the dynamic structures, capture intrinsic dependencies, and learn robust representations, remains under-explored. In this work, we propose the novel DG-Mamba, a robust and efficient Dynamic Graph structure learning framework with the Selective State Space Models (Mamba). To accelerate the spatio-temporal structure learning, we propose a kernelized dynamic message-passing operator that reduces the quadratic time complexity to linear. To capture global intrinsic dynamics, we establish the dynamic graph as a self-contained system with State Space Model. By discretizing the system states with the cross-snapshot graph adjacency, we enable the long-distance dependencies capturing with the selective snapshot scan. To endow learned dynamic structures more expressive with informativeness, we propose the self-supervised Principle of Relevant Information for DGSL to regularize the most relevant yet least redundant information, enhancing global robustness. Extensive experiments demonstrate the superiority of the robustness and efficiency of our DG-Mamba compared with the state-of-the-art baselines against adversarial attacks.
TabDeco: A Comprehensive Contrastive Framework for Decoupled Representations in Tabular Data
Nov 17, 2024



Representation learning is a fundamental aspect of modern artificial intelligence, driving substantial improvements across diverse applications. While selfsupervised contrastive learning has led to significant advancements in fields like computer vision and natural language processing, its adaptation to tabular data presents unique challenges. Traditional approaches often prioritize optimizing model architecture and loss functions but may overlook the crucial task of constructing meaningful positive and negative sample pairs from various perspectives like feature interactions, instance-level patterns and batch-specific contexts. To address these challenges, we introduce TabDeco, a novel method that leverages attention-based encoding strategies across both rows and columns and employs contrastive learning framework to effectively disentangle feature representations at multiple levels, including features, instances and data batches. With the innovative feature decoupling hierarchies, TabDeco consistently surpasses existing deep learning methods and leading gradient boosting algorithms, including XG-Boost, CatBoost, and LightGBM, across various benchmark tasks, underscoring its effectiveness in advancing tabular data representation learning.
MOLA: Enhancing Industrial Process Monitoring Using Multi-Block Orthogonal Long Short-Term Memory Autoencoder
Oct 10, 2024



In this work, we introduce MOLA: a Multi-block Orthogonal Long short-term memory Autoencoder paradigm, to conduct accurate, reliable fault detection of industrial processes. To achieve this, MOLA effectively extracts dynamic orthogonal features by introducing an orthogonality-based loss function to constrain the latent space output. This helps eliminate the redundancy in the features identified, thereby improving the overall monitoring performance. On top of this, a multi-block monitoring structure is proposed, which categorizes the process variables into multiple blocks by leveraging expert process knowledge about their associations with the overall process. Each block is associated with its specific Orthogonal Long short-term memory Autoencoder model, whose extracted dynamic orthogonal features are monitored by distance-based Hotelling's $T^2$ statistics and quantile-based cumulative sum (CUSUM) designed for multivariate data streams that are nonparametric, heterogeneous in nature. Compared to having a single model accounting for all process variables, such a multi-block structure improves the overall process monitoring performance significantly, especially for large-scale industrial processes. Finally, we propose an adaptive weight-based Bayesian fusion (W-BF) framework to aggregate all block-wise monitoring statistics into a global statistic that we monitor for faults, with the goal of improving fault detection speed by assigning weights to blocks based on the sequential order where alarms are raised. We demonstrate the efficiency and effectiveness of our MOLA framework by applying it to the Tennessee Eastman Process and comparing the performance with various benchmark methods.
GC-Bench: An Open and Unified Benchmark for Graph Condensation
Jun 30, 2024Graph condensation (GC) has recently garnered considerable attention due to its ability to reduce large-scale graph datasets while preserving their essential properties. The core concept of GC is to create a smaller, more manageable graph that retains the characteristics of the original graph. Despite the proliferation of graph condensation methods developed in recent years, there is no comprehensive evaluation and in-depth analysis, which creates a great obstacle to understanding the progress in this field. To fill this gap, we develop a comprehensive Graph Condensation Benchmark (GC-Bench) to analyze the performance of graph condensation in different scenarios systematically. Specifically, GC-Bench systematically investigates the characteristics of graph condensation in terms of the following dimensions: effectiveness, transferability, and complexity. We comprehensively evaluate 12 state-of-the-art graph condensation algorithms in node-level and graph-level tasks and analyze their performance in 12 diverse graph datasets. Further, we have developed an easy-to-use library for training and evaluating different GC methods to facilitate reproducible research. The GC-Bench library is available at https://github.com/RingBDStack/GC-Bench.
Variational Multi-Modal Hypergraph Attention Network for Multi-Modal Relation Extraction
Apr 18, 2024
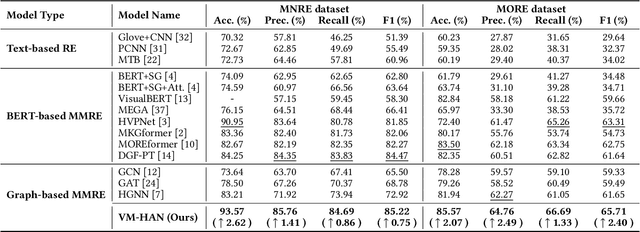
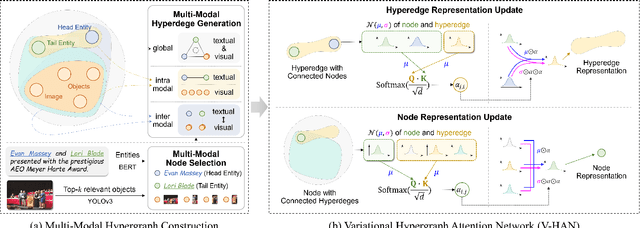
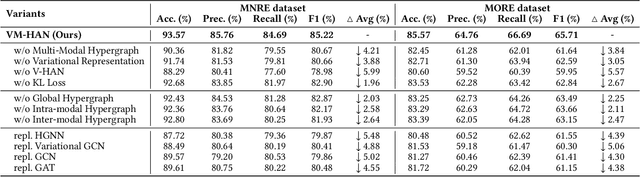
Multi-modal relation extraction (MMRE) is a challenging task that aims to identify relations between entities in text leveraging image information. Existing methods are limited by their neglect of the multiple entity pairs in one sentence sharing very similar contextual information (ie, the same text and image), resulting in increased difficulty in the MMRE task. To address this limitation, we propose the Variational Multi-Modal Hypergraph Attention Network (VM-HAN) for multi-modal relation extraction. Specifically, we first construct a multi-modal hypergraph for each sentence with the corresponding image, to establish different high-order intra-/inter-modal correlations for different entity pairs in each sentence. We further design the Variational Hypergraph Attention Networks (V-HAN) to obtain representational diversity among different entity pairs using Gaussian distribution and learn a better hypergraph structure via variational attention. VM-HAN achieves state-of-the-art performance on the multi-modal relation extraction task, outperforming existing methods in terms of accuracy and efficiency.