 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemoSight: Unifying Context Compression and Multi Token Prediction for Reasoning Acceleration
Apr 16, 2026While Chain-of-thought (CoT) reasoning enables LLMs to solve challenging reasoning problems, as KV cache grows linearly with the number of generated tokens, CoT reasoning faces scaling issues in terms of speed and memory usage. In this work, we propose MemoSight (Memory-Foresight-based reasoning), a unified framework that integrates both context compression and multi-token prediction to mitigate the efficiency issues while maintaining CoT reasoning performance. Our framework adopts the same minimalist design for both context compression and multi-token prediction via special tokens and their corresponding position layout tailored to each token type. Comprehensive experiments on four reasoning benchmarks demonstrate that MemoSight reduces the KV cache footprint by up to 66% and accelerates inference by 1.56x, while outperforming existing CoT compression methods.
Monocular Mesh Recovery and Body Measurement of Female Saanen Goats
Feb 23, 2026The lactation performance of Saanen dairy goats, renowned for their high milk yield, is intrinsically linked to their body size, making accurate 3D body measurement essential for assessing milk production potential, yet existing reconstruction methods lack goat-specific authentic 3D data. To address this limitation, we establish the FemaleSaanenGoat dataset containing synchronized eight-view RGBD videos of 55 female Saanen goats (6-18 months). Using multi-view DynamicFusion, we fuse noisy, non-rigid point cloud sequences into high-fidelity 3D scans, overcoming challenges from irregular surfaces and rapid movement. Based on these scans, we develop SaanenGoat, a parametric 3D shape model specifically designed for female Saanen goats. This model features a refined template with 41 skeletal joints and enhanced udder representation, registered with our scan data. A comprehensive shape space constructed from 48 goats enables precise representation of diverse individual variations. With the help of SaanenGoat model, we get high-precision 3D reconstruction from single-view RGBD input, and achieve automated measurement of six critical body dimensions: body length, height, chest width, chest girth, hip width, and hip height. Experimental results demonstrate the superior accuracy of our method in both 3D reconstruction and body measurement, presenting a novel paradigm for large-scale 3D vision applications in precision livestock farming.
It Takes Two to Tango: A Holistic Simulator for Joint Order Scheduling and Multi-Agent Path Finding in Robotic Warehouses
Feb 15, 2026The prevailing paradigm in Robotic Mobile Fulfillment Systems (RMFS) typically treats order scheduling and multi-agent pathfinding as isolated sub-problems. We argue that this decoupling is a fundamental bottleneck, masking the critical dependencies between high-level dispatching and low-level congestion. Existing simulators fail to bridge this gap, often abstracting away heterogeneous kinematics and stochastic execution failures. We propose WareRover, a holistic simulation platform that enforces a tight coupling between OS and MAPF via a unified, closed-loop optimization interface. Unlike standard benchmarks, WareRover integrates dynamic order streams, physics-aware motion constraints, and non-nominal recovery mechanisms into a single evaluation loop. Experiments reveal that SOTA algorithms often falter under these realistic coupled constraints, demonstrating that WareRover provides a necessary and challenging testbed for robust, next-generation warehouse coordination. The project and video is available at https://hhh-x.github.io/WareRover/.
Multi-Head Spectral-Adaptive Graph Anomaly Detection
Dec 25, 2025Graph anomaly detection technology has broad applications in financial fraud and risk control. However, existing graph anomaly detection methods often face significant challenges when dealing with complex and variable abnormal patterns, as anomalous nodes are often disguised and mixed with normal nodes, leading to the coexistence of homophily and heterophily in the graph domain. Recent spectral graph neural networks have made notable progress in addressing this issue; however, current techniques typically employ fixed, globally shared filters. This 'one-size-fits-all' approach can easily cause over-smoothing, erasing critical high-frequency signals needed for fraud detection, and lacks adaptive capabilities for different graph instances. To solve this problem, we propose a Multi-Head Spectral-Adaptive Graph Neural Network (MHSA-GNN). The core innovation is the design of a lightweight hypernetwork that, conditioned on a 'spectral fingerprint' containing structural statistics and Rayleigh quotient features, dynamically generates Chebyshev filter parameters tailored to each instance. This enables a customized filtering strategy for each node and its local subgraph. Additionally, to prevent mode collapse in the multi-head mechanism, we introduce a novel dual regularization strategy that combines teacher-student contrastive learning (TSC) to ensure representation accuracy and Barlow Twins diversity loss (BTD) to enforce orthogonality among heads. Extensive experiments on four real-world datasets demonstrate that our method effectively preserves high-frequency abnormal signals and significantly outperforms existing state-of-the-art methods, especially showing excellent robustness on highly heterogeneous datasets.
MOCHA: Discovering Multi-Order Dynamic Causality in Temporal Point Processes
Aug 26, 2025Discovering complex causal dependencies in temporal point processes (TPPs) is critical for modeling real-world event sequences. Existing methods typically rely on static or first-order causal structures, overlooking the multi-order and time-varying nature of causal relationships. In this paper, we propose MOCHA, a novel framework for discovering multi-order dynamic causality in TPPs. MOCHA characterizes multi-order influences as multi-hop causal paths over a latent time-evolving graph. To model such dynamics, we introduce a time-varying directed acyclic graph (DAG) with learnable structural weights, where acyclicity and sparsity constraints are enforced to ensure structural validity. We design an end-to-end differentiable framework that jointly models causal discovery and TPP dynamics, enabling accurate event prediction and revealing interpretable structures. Extensive experiments on real-world datasets demonstrate that MOCHA not only achieves state-of-the-art performance in event prediction, but also reveals meaningful and interpretable causal structures.
Differentiable Adaptive Kalman Filtering via Optimal Transport
Aug 09, 2025Learning-based filtering has demonstrated strong performance in non-linear dynamical systems, particularly when the statistics of noise are unknown. However, in real-world deployments, environmental factors, such as changing wind conditions or electromagnetic interference, can induce unobserved noise-statistics drift, leading to substantial degradation of learning-based methods. To address this challenge, we propose OTAKNet, the first online solution to noise-statistics drift within learning-based adaptive Kalman filtering. Unlike existing learning-based methods that perform offline fine-tuning using batch pointwise matching over entire trajectories, OTAKNet establishes a connection between the state estimate and the drift via one-step predictive measurement likelihood, and addresses it using optimal transport. This leverages OT's geometry - aware cost and stable gradients to enable fully online adaptation without ground truth labels or retraining. We compare OTAKNet against classical model-based adaptive Kalman filtering and offline learning-based filtering. The performance is demonstrated on both synthetic and real-world NCLT datasets, particularly under limited training data.
TextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
Reinforced Reasoning for Embodied Planning
May 28, 2025
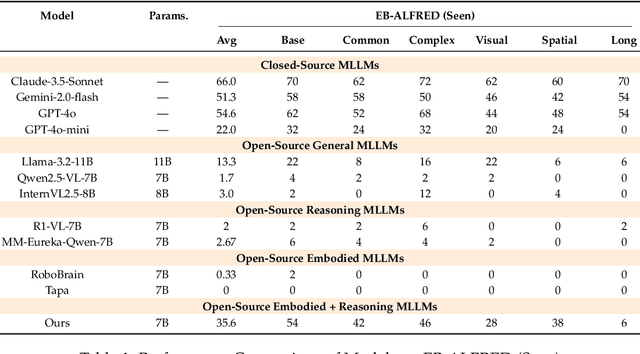


Embodied planning requires agents to make coherent multi-step decisions based on dynamic visual observations and natural language goals. While recent vision-language models (VLMs) excel at static perception tasks, they struggle with the temporal reasoning, spatial understanding, and commonsense grounding needed for planning in interactive environments. In this work, we introduce a reinforcement fine-tuning framework that brings R1-style reasoning enhancement into embodied planning. We first distill a high-quality dataset from a powerful closed-source model and perform supervised fine-tuning (SFT) to equip the model with structured decision-making priors. We then design a rule-based reward function tailored to multi-step action quality and optimize the policy via Generalized Reinforced Preference Optimization (GRPO). Our approach is evaluated on Embench, a recent benchmark for interactive embodied tasks, covering both in-domain and out-of-domain scenarios. Experimental results show that our method significantly outperforms models of similar or larger scale, including GPT-4o-mini and 70B+ open-source baselines, and exhibits strong generalization to unseen environments. This work highlights the potential of reinforcement-driven reasoning to advance long-horizon planning in embodied AI.
Optimization Problem Solving Can Transition to Evolutionary Agentic Workflows
May 07, 2025This position paper argues that optimization problem solving can transition from expert-dependent to evolutionary agentic workflows. Traditional optimization practices rely on human specialists for problem formulation, algorithm selection, and hyperparameter tuning, creating bottlenecks that impede industrial adoption of cutting-edge methods. We contend that an evolutionary agentic workflow, powered by foundation models and evolutionary search, can autonomously navigate the optimization space, comprising problem, formulation, algorithm, and hyperparameter spaces. Through case studies in cloud resource scheduling and ADMM parameter adaptation, we demonstrate how this approach can bridge the gap between academic innovation and industrial implementation. Our position challenges the status quo of human-centric optimization workflows and advocates for a more scalable, adaptive approach to solving real-world optimization problems.
Interpretable Hybrid-Rule Temporal Point Processes
Apr 15, 2025Temporal Point Processes (TPPs) are widely used for modeling event sequences in various medical domains, such as disease onset prediction, progression analysis, and clinical decision support. Although TPPs effectively capture temporal dynamics, their lack of interpretability remains a critical challenge. Recent advancements have introduced interpretable TPPs. However, these methods fail to incorporate numerical features, thereby limiting their ability to generate precise predictions. To address this issue, we propose Hybrid-Rule Temporal Point Processes (HRTPP), a novel framework that integrates temporal logic rules with numerical features, improving both interpretability and predictive accuracy in event modeling. HRTPP comprises three key components: basic intensity for intrinsic event likelihood, rule-based intensity for structured temporal dependencies, and numerical feature intensity for dynamic probability modulation. To effectively discover valid rules, we introduce a two-phase rule mining strategy with Bayesian optimization. To evaluate our method, we establish a multi-criteria assessment framework, incorporating rule validity, model fitting, and temporal predictive accuracy. Experimental results on real-world medical datasets demonstrate that HRTPP outperforms state-of-the-art interpretable TPPs in terms of predictive performance and clinical interpretability. In case studies, the rules extracted by HRTPP explain the disease progression, offering valuable contributions to medical diagnosis.