 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapley-Coop: Credit Assignment for Emergent Cooperation in Self-Interested LLM Agents
Jun 09, 2025
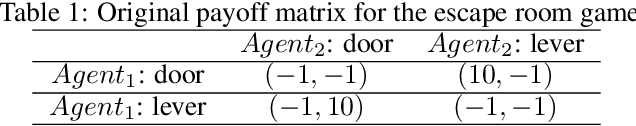

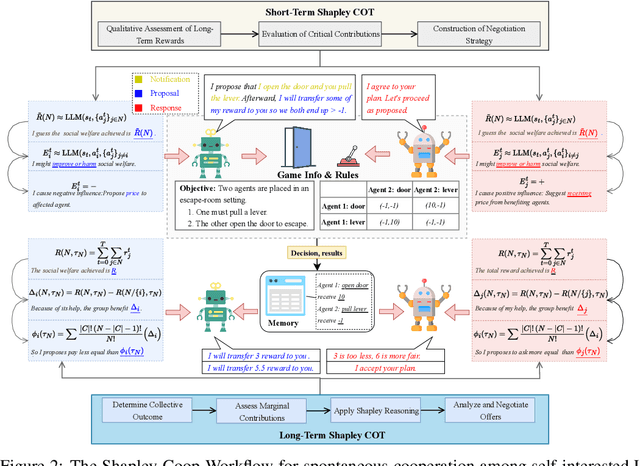
Large Language Models (LLMs) show strong collaborative performance in multi-agent systems with predefined roles and workflows. However, in open-ended environments lacking coordination rules, agents tend to act in self-interested ways. The central challenge in achieving coordination lies in credit assignment -- fairly evaluating each agent's contribution and designing pricing mechanisms that align their heterogeneous goals. This problem is critical as LLMs increasingly participate in complex human-AI collaborations, where fair compensation and accountability rely on effective pricing mechanisms. Inspired by how human societies address similar coordination challenges (e.g., through temporary collaborations such as employment or subcontracting), we propose a cooperative workflow, Shapley-Coop. Shapley-Coop integrates Shapley Chain-of-Thought -- leveraging marginal contributions as a principled basis for pricing -- with structured negotiation protocols for effective price matching, enabling LLM agents to coordinate through rational task-time pricing and post-task reward redistribution. This approach aligns agent incentives, fosters cooperation, and maintains autonomy. We evaluate Shapley-Coop across two multi-agent games and a software engineering simulation, demonstrating that it consistently enhances LLM agent collaboration and facilitates equitable credit assignment. These results highlight the effectiveness of Shapley-Coop's pricing mechanisms in accurately reflecting individual contributions during task execution.
TextAtari: 100K Frames Game Playing with Language Agents
Jun 04, 2025We present TextAtari, a benchmark for evaluating language agents on very long-horizon decision-making tasks spanning up to 100,000 steps. By translating the visual state representations of classic Atari games into rich textual descriptions, TextAtari creates a challenging test bed that bridges sequential decision-making with natural language processing. The benchmark includes nearly 100 distinct tasks with varying complexity, action spaces, and planning horizons, all rendered as text through an unsupervised representation learning framework (AtariARI). We evaluate three open-source large language models (Qwen2.5-7B, Gemma-7B, and Llama3.1-8B) across three agent frameworks (zero-shot, few-shot chain-of-thought, and reflection reasoning) to assess how different forms of prior knowledge affect performance on these long-horizon challenges. Four scenarios-Basic, Obscured, Manual Augmentation, and Reference-based-investigate the impact of semantic understanding, instruction comprehension, and expert demonstrations on agent decision-making. Our results reveal significant performance gaps between language agents and human players in extensive planning tasks, highlighting challenges in sequential reasoning, state tracking, and strategic planning across tens of thousands of steps. TextAtari provides standardized evaluation protocols, baseline implementations, and a framework for advancing research at the intersection of language models and planning.
Can language agents be alternatives to PPO? A Preliminary Empirical Study On OpenAI Gym
Dec 06, 2023The formidable capacity for zero- or few-shot decision-making in language agents encourages us to pose a compelling question: Can language agents be alternatives to PPO agents in traditional sequential decision-making tasks? To investigate this, we first take environments collected in OpenAI Gym as our testbeds and ground them to textual environments that construct the TextGym simulator. This allows for straightforward and efficient comparisons between PPO agents and language agents, given the widespread adoption of OpenAI Gym. To ensure a fair and effective benchmarking, we introduce $5$ levels of scenario for accurate domain-knowledge controlling and a unified RL-inspired framework for language agents. Additionally, we propose an innovative explore-exploit-guided language (EXE) agent to solve tasks within TextGym. Through numerical experiments and ablation studies, we extract valuable insights into the decision-making capabilities of language agents and make a preliminary evaluation of their potential to be alternatives to PPO in classical sequential decision-making problems. This paper sheds light on the performance of language agents and paves the way for future research in this exciting domain. Our code is publicly available at~\url{https://github.com/mail-ecnu/Text-Gym-Agents}.
VMAgent: Scheduling Simulator for Reinforcement Learning
Dec 09, 2021
A novel simulator called VMAgent is introduced to help RL researchers better explore new methods, especially for virtual machine scheduling. VMAgent is inspired by practical virtual machine (VM) scheduling tasks and provides an efficient simulation platform that can reflect the real situations of cloud computing. Three scenarios (fading, recovering, and expansion) are concluded from practical cloud computing and corresponds to many reinforcement learning challenges (high dimensional state and action spaces, high non-stationarity, and life-long demand). VMAgent provides flexible configurations for RL researchers to design their customized scheduling environments considering different problem features. From the VM scheduling perspective, VMAgent also helps to explore better learning-based scheduling solutions.
Structured Diversification Emergence via Reinforced Organization Control and Hierarchical Consensus Learning
Feb 09, 2021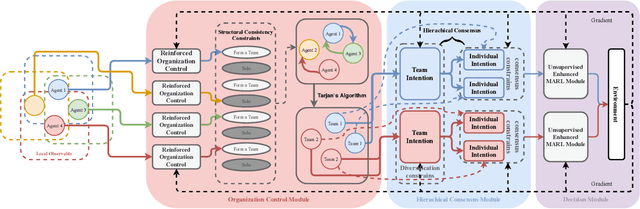
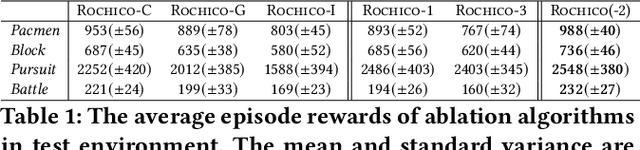
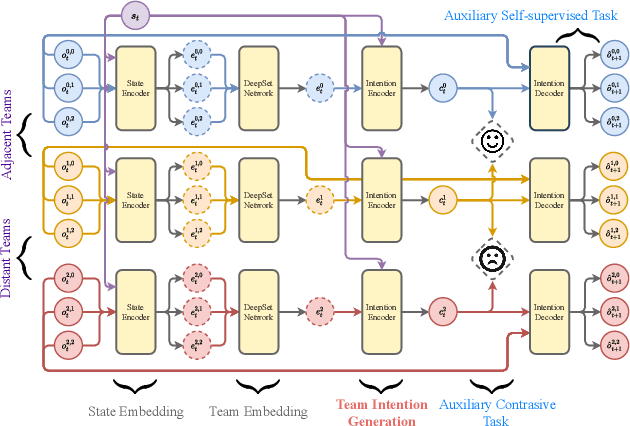
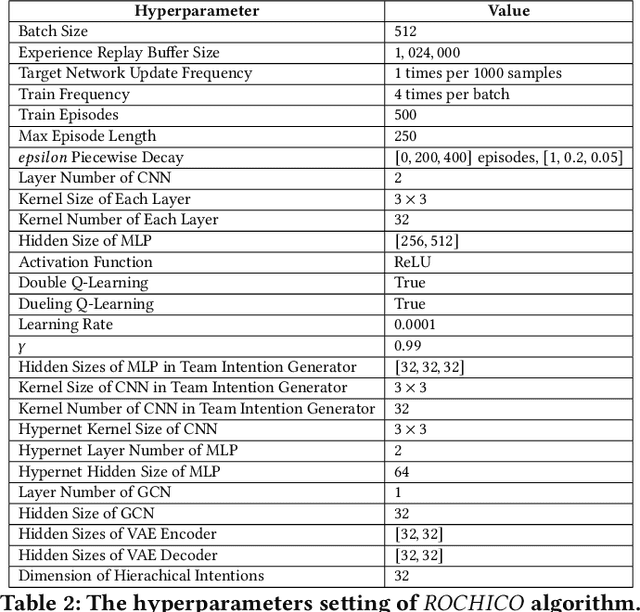
When solving a complex task, humans will spontaneously form teams and to complete different parts of the whole task, respectively. Meanwhile, the cooperation between teammates will improve efficiency. However, for current cooperative MARL methods, the cooperation team is constructed through either heuristics or end-to-end blackbox optimization. In order to improve the efficiency of cooperation and exploration, we propose a structured diversification emergence MARL framework named {\sc{Rochico}} based on reinforced organization control and hierarchical consensus learning. {\sc{Rochico}} first learns an adaptive grouping policy through the organization control module, which is established by independent multi-agent reinforcement learning. Further, the hierarchical consensus module based on the hierarchical intentions with consensus constraint is introduced after team formation. Simultaneously, utilizing the hierarchical consensus module and a self-supervised intrinsic reward enhanced decision module, the proposed cooperative MARL algorithm {\sc{Rochico}} can output the final diversified multi-agent cooperative policy. All three modules are organically combined to promote the structured diversification emergence. Comparative experiments on four large-scale cooperation tasks show that {\sc{Rochico}} is significantly better than the current SOTA algorithms in terms of exploration efficiency and cooperation strength.
Hyper-Meta Reinforcement Learning with Sparse Reward
Feb 11, 2020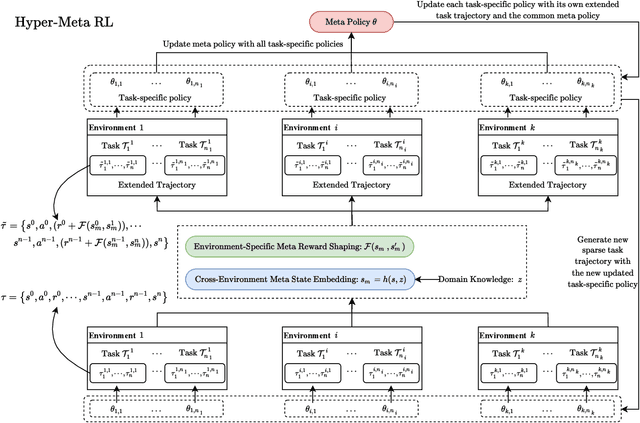
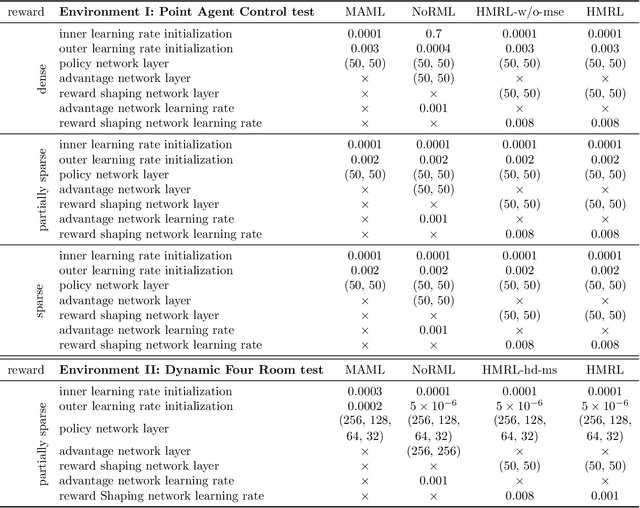
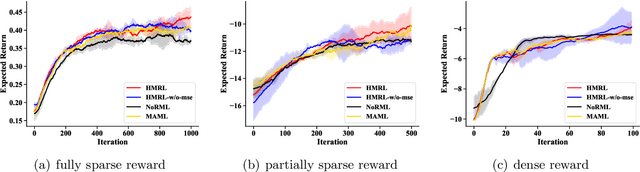

Despite their success, existing meta reinforcement learning methods still have difficulty in learning a meta policy effectively for RL problems with sparse reward. To this end, we develop a novel meta reinforcement learning framework, Hyper-Meta RL (HMRL), for sparse reward RL problems. It consists of meta state embedding, meta reward shaping and meta policy learning modules: The cross-environment meta state embedding module constructs a common meta state space to adapt to different environments; The meta state based environment-specific meta reward shaping effectively extends the original sparse reward trajectory by cross-environmental knowledge complementarity; As a consequence, the meta policy then achieves better generalization and efficiency with the shaped meta reward. Experiments with sparse reward show the superiority of HMRL on both transferability and policy learning efficiency.