 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025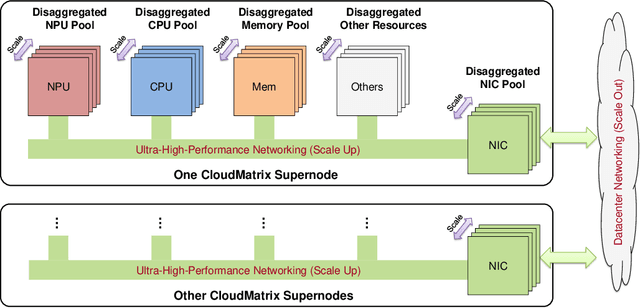
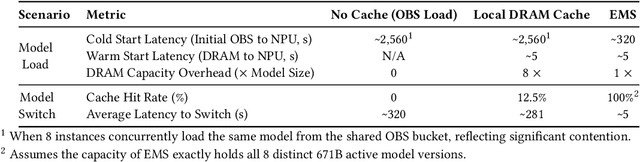
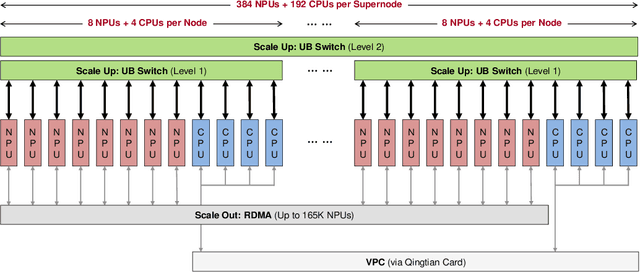
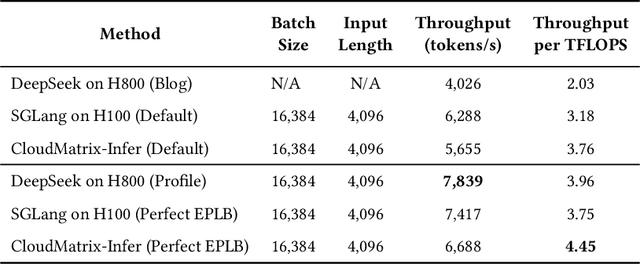
The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
ReAssigner: A Plug-and-Play Virtual Machine Scheduling Intensifier for Heterogeneous Requests
Nov 29, 2022With the rapid development of cloud computing, virtual machine scheduling has become one of the most important but challenging issues for the cloud computing community, especially for practical heterogeneous request sequences. By analyzing the impact of request heterogeneity on some popular heuristic schedulers, it can be found that existing scheduling algorithms can not handle the request heterogeneity properly and efficiently. In this paper, a plug-and-play virtual machine scheduling intensifier, called Resource Assigner (ReAssigner), is proposed to enhance the scheduling efficiency of any given scheduler for heterogeneous requests. The key idea of ReAssigner is to pre-assign roles to physical resources and let resources of the same role form a virtual cluster to handle homogeneous requests. ReAssigner can cooperate with arbitrary schedulers by restricting their scheduling space to virtual clusters. With evaluations on the real dataset from Huawei Cloud, the proposed ReAssigner achieves significant scheduling performance improvement compared with some state-of-the-art scheduling methods.
Gleo-Det: Deep Convolution Feature-Guided Detector with Local Entropy Optimization for Salient Points
Apr 27, 2022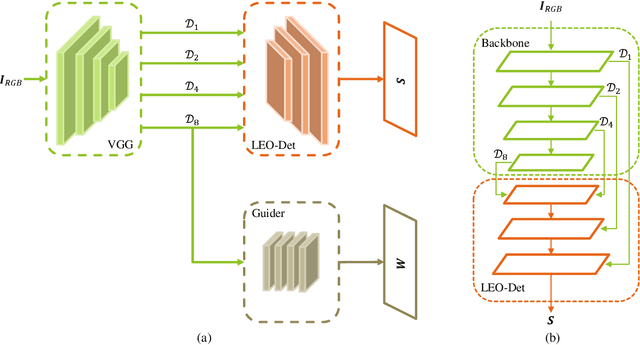


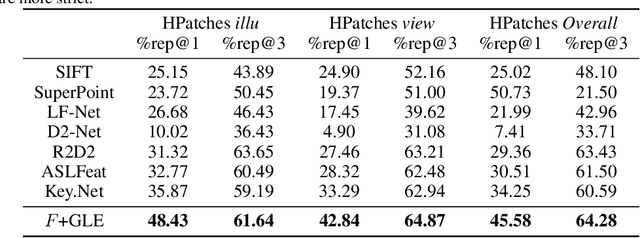
Feature detection is an important procedure for image matching, where unsupervised feature detection methods are the detection approaches that have been mostly studied recently, including the ones that are based on repeatability requirement to define loss functions, and the ones that attempt to use descriptor matching to drive the optimization of the pipelines. For the former type, mean square error (MSE) is usually used which cannot provide strong constraint for training and can make the model easy to be stuck into the collapsed solution. For the later one, due to the down sampling operation and the expansion of receptive fields, the details can be lost for local descriptors can be lost, making the constraint not fine enough. Considering the issues above, we propose to combine both ideas, which including three aspects. 1) We propose to achieve fine constraint based on the requirement of repeatability while coarse constraint with guidance of deep convolution features. 2) To address the issue that optimization with MSE is limited, entropy-based cost function is utilized, both soft cross-entropy and self-information. 3) With the guidance of convolution features, we define the cost function from both positive and negative sides. Finally, we study the effect of each modification proposed and experiments demonstrate that our method achieves competitive results over the state-of-the-art approaches.
VMAgent: Scheduling Simulator for Reinforcement Learning
Dec 09, 2021
A novel simulator called VMAgent is introduced to help RL researchers better explore new methods, especially for virtual machine scheduling. VMAgent is inspired by practical virtual machine (VM) scheduling tasks and provides an efficient simulation platform that can reflect the real situations of cloud computing. Three scenarios (fading, recovering, and expansion) are concluded from practical cloud computing and corresponds to many reinforcement learning challenges (high dimensional state and action spaces, high non-stationarity, and life-long demand). VMAgent provides flexible configurations for RL researchers to design their customized scheduling environments considering different problem features. From the VM scheduling perspective, VMAgent also helps to explore better learning-based scheduling solutions.
Meta Self-Learning for Multi-Source Domain Adaptation: A Benchmark
Aug 24, 2021
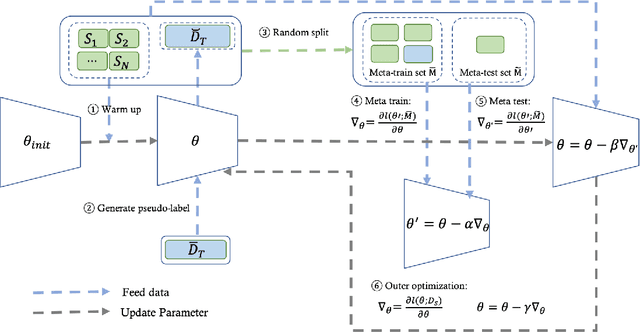

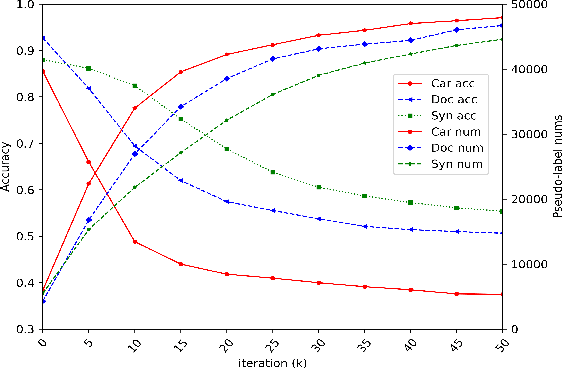
In recent years, deep learning-based methods have shown promising results in computer vision area. However, a common deep learning model requires a large amount of labeled data, which is labor-intensive to collect and label. What's more, the model can be ruined due to the domain shift between training data and testing data. Text recognition is a broadly studied field in computer vision and suffers from the same problems noted above due to the diversity of fonts and complicated backgrounds. In this paper, we focus on the text recognition problem and mainly make three contributions toward these problems. First, we collect a multi-source domain adaptation dataset for text recognition, including five different domains with over five million images, which is the first multi-domain text recognition dataset to our best knowledge. Secondly, we propose a new method called Meta Self-Learning, which combines the self-learning method with the meta-learning paradigm and achieves a better recognition result under the scene of multi-domain adaptation. Thirdly, extensive experiments are conducted on the dataset to provide a benchmark and also show the effectiveness of our method. The code of our work and dataset are available soon at https://bupt-ai-cz.github.io/Meta-SelfLearning/.
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
Aug 24, 2021
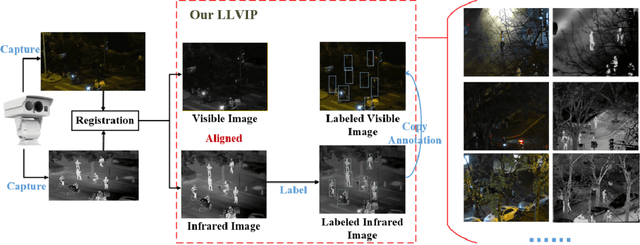
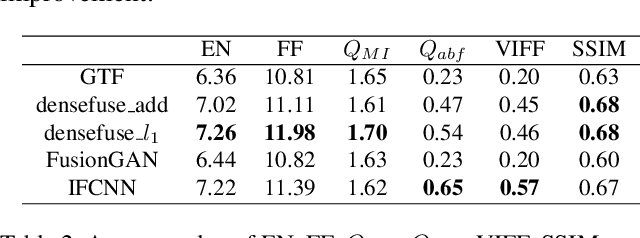

It is very challenging for various visual tasks such as image fusion, pedestrian detection and image-to-image translation in low light conditions due to the loss of effective target areas. In this case, infrared and visible images can be used together to provide both rich detail information and effective target areas. In this paper, we present LLVIP, a visible-infrared paired dataset for low-light vision. This dataset contains 33672 images, or 16836 pairs, most of which were taken at very dark scenes, and all of the images are strictly aligned in time and space. Pedestrians in the dataset are labeled. We compare the dataset with other visible-infrared datasets and evaluate the performance of some popular visual algorithms including image fusion, pedestrian detection and image-to-image translation on the dataset. The experimental results demonstrate the complementary effect of fusion on image information, and find the deficiency of existing algorithms of the three visual tasks in very low-light conditions. We believe the LLVIP dataset will contribute to the community of computer vision by promoting image fusion, pedestrian detection and image-to-image translation in very low-light applications. The dataset is being released in https://bupt-ai-cz.github.io/LLVIP.