 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability-Invariant Random Walk Learning on Gyral Folding-Based Cortical Similarity Networks for Alzheimer's and Lewy Body Dementia Diagnosis
Feb 19, 2026Alzheimer's disease (AD) and Lewy body dementia (LBD) present overlapping clinical features yet require distinct diagnostic strategies. While neuroimaging-based brain network analysis is promising, atlas-based representations may obscure individualized anatomy. Gyral folding-based networks using three-hinge gyri provide a biologically grounded alternative, but inter-individual variability in cortical folding results in inconsistent landmark correspondence and highly irregular network sizes, violating the fixed-topology and node-alignment assumptions of most existing graph learning methods, particularly in clinical datasets where pathological changes further amplify anatomical heterogeneity. We therefore propose a probability-invariant random-walk-based framework that classifies individualized gyral folding networks without explicit node alignment. Cortical similarity networks are built from local morphometric features and represented by distributions of anonymized random walks, with an anatomy-aware encoding that preserves permutation invariance. Experiments on a large clinical cohort of AD and LBD subjects show consistent improvements over existing gyral folding and atlas-based models, demonstrating robustness and potential for dementia diagnosis.
STaR: Sensitive Trajectory Regulation for Unlearning in Large Reasoning Models
Jan 14, 2026Large Reasoning Models (LRMs) have advanced automated multi-step reasoning, but their ability to generate complex Chain-of-Thought (CoT) trajectories introduces severe privacy risks, as sensitive information may be deeply embedded throughout the reasoning process. Existing Large Language Models (LLMs) unlearning approaches that typically focus on modifying only final answers are insufficient for LRMs, as they fail to remove sensitive content from intermediate steps, leading to persistent privacy leakage and degraded security. To address these challenges, we propose Sensitive Trajectory Regulation (STaR), a parameter-free, inference-time unlearning framework that achieves robust privacy protection throughout the reasoning process. Specifically, we first identify sensitive content via semantic-aware detection. Then, we inject global safety constraints through secure prompt prefix. Next, we perform trajectory-aware suppression to dynamically block sensitive content across the entire reasoning chain. Finally, we apply token-level adaptive filtering to prevent both exact and paraphrased sensitive tokens during generation. Furthermore, to overcome the inadequacies of existing evaluation protocols, we introduce two metrics: Multi-Decoding Consistency Assessment (MCS), which measures the consistency of unlearning across diverse decoding strategies, and Multi-Granularity Membership Inference Attack (MIA) Evaluation, which quantifies privacy protection at both answer and reasoning-chain levels. Experiments on the R-TOFU benchmark demonstrate that STaR achieves comprehensive and stable unlearning with minimal utility loss, setting a new standard for privacy-preserving reasoning in LRMs.
Whole-brain Transferable Representations from Large-Scale fMRI Data Improve Task-Evoked Brain Activity Decoding
Jul 30, 2025A fundamental challenge in neuroscience is to decode mental states from brain activity. While functional magnetic resonance imaging (fMRI) offers a non-invasive approach to capture brain-wide neural dynamics with high spatial precision, decoding from fMRI data -- particularly from task-evoked activity -- remains challenging due to its high dimensionality, low signal-to-noise ratio, and limited within-subject data. Here, we leverage recent advances in computer vision and propose STDA-SwiFT, a transformer-based model that learns transferable representations from large-scale fMRI datasets via spatial-temporal divided attention and self-supervised contrastive learning. Using pretrained voxel-wise representations from 995 subjects in the Human Connectome Project (HCP), we show that our model substantially improves downstream decoding performance of task-evoked activity across multiple sensory and cognitive domains, even with minimal data preprocessing. We demonstrate performance gains from larger receptor fields afforded by our memory-efficient attention mechanism, as well as the impact of functional relevance in pretraining data when fine-tuning on small samples. Our work showcases transfer learning as a viable approach to harness large-scale datasets to overcome challenges in decoding brain activity from fMRI data.
Exploring Hallucination of Large Multimodal Models in Video Understanding: Benchmark, Analysis and Mitigation
Mar 25, 2025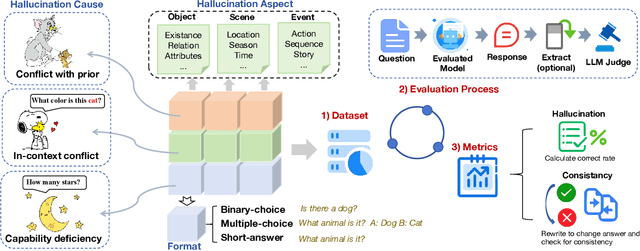
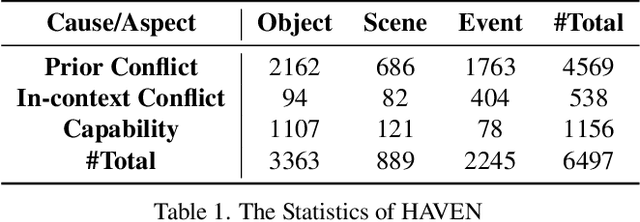
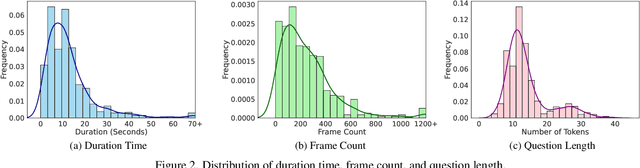
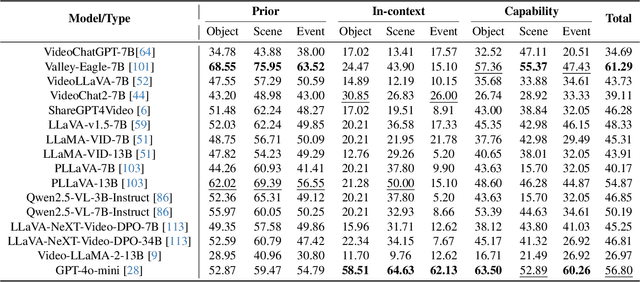
The hallucination of large multimodal models (LMMs), providing responses that appear correct but are actually incorrect, limits their reliability and applicability. This paper aims to study the hallucination problem of LMMs in video modality, which is dynamic and more challenging compared to static modalities like images and text. From this motivation, we first present a comprehensive benchmark termed HAVEN for evaluating hallucinations of LMMs in video understanding tasks. It is built upon three dimensions, i.e., hallucination causes, hallucination aspects, and question formats, resulting in 6K questions. Then, we quantitatively study 7 influential factors on hallucinations, e.g., duration time of videos, model sizes, and model reasoning, via experiments of 16 LMMs on the presented benchmark. In addition, inspired by recent thinking models like OpenAI o1, we propose a video-thinking model to mitigate the hallucinations of LMMs via supervised reasoning fine-tuning (SRFT) and direct preference optimization (TDPO)-- where SRFT enhances reasoning capabilities while TDPO reduces hallucinations in the thinking process. Extensive experiments and analyses demonstrate the effectiveness. Remarkably, it improves the baseline by 7.65% in accuracy on hallucination evaluation and reduces the bias score by 4.5%. The code and data are public at https://github.com/Hongcheng-Gao/HAVEN.
Computational Analysis of Yaredawi YeZema Silt in Ethiopian Orthodox Tewahedo Church Chants
Dec 25, 2024Despite its musicological, cultural, and religious significance, the Ethiopian Orthodox Tewahedo Church (EOTC) chant is relatively underrepresented in music research. Historical records, including manuscripts, research papers, and oral traditions, confirm Saint Yared's establishment of three canonical EOTC chanting modes during the 6th century. This paper attempts to investigate the EOTC chants using music information retrieval (MIR) techniques. Among the research questions regarding the analysis and understanding of EOTC chants, Yaredawi YeZema Silt, namely the mode of chanting adhering to Saint Yared's standards, is of primary importance. Therefore, we consider the task of Yaredawi YeZema Silt classification in EOTC chants by introducing a new dataset and showcasing a series of classification experiments for this task. Results show that using the distribution of stabilized pitch contours as the feature representation on a simple neural network-based classifier becomes an effective solution. The musicological implications and insights of such results are further discussed through a comparative study with the previous ethnomusicology literature on EOTC chants. By making this dataset publicly accessible, we aim to promote future exploration and analysis of EOTC chants and highlight potential directions for further research, thereby fostering a deeper understanding and preservation of this unique spiritual and cultural heritage.
* 6 pages
Zema Dataset: A Comprehensive Study of Yaredawi Zema with a Focus on Horologium Chants
Dec 25, 2024



Computational music research plays a critical role in advancing music production, distribution, and understanding across various musical styles worldwide. Despite the immense cultural and religious significance, the Ethiopian Orthodox Tewahedo Church (EOTC) chants are relatively underrepresented in computational music research. This paper contributes to this field by introducing a new dataset specifically tailored for analyzing EOTC chants, also known as Yaredawi Zema. This work provides a comprehensive overview of a 10-hour dataset, 369 instances, creation, and curation process, including rigorous quality assurance measures. Our dataset has a detailed word-level temporal boundary and reading tone annotation along with the corresponding chanting mode label of audios. Moreover, we have also identified the chanting options associated with multiple chanting notations in the manuscript by annotating them accordingly. Our goal in making this dataset available to the public 1 is to encourage more research and study of EOTC chants, including lyrics transcription, lyric-to-audio alignment, and music generation tasks. Such research work will advance knowledge and efforts to preserve this distinctive liturgical music, a priceless cultural artifact for the Ethiopian people.
* 6 pages
Query-centric Audio-Visual Cognition Network for Moment Retrieval, Segmentation and Step-Captioning
Dec 18, 2024Video has emerged as a favored multimedia format on the internet. To better gain video contents, a new topic HIREST is presented, including video retrieval, moment retrieval, moment segmentation, and step-captioning. The pioneering work chooses the pre-trained CLIP-based model for video retrieval, and leverages it as a feature extractor for other three challenging tasks solved in a multi-task learning paradigm. Nevertheless, this work struggles to learn the comprehensive cognition of user-preferred content, due to disregarding the hierarchies and association relations across modalities. In this paper, guided by the shallow-to-deep principle, we propose a query-centric audio-visual cognition (QUAG) network to construct a reliable multi-modal representation for moment retrieval, segmentation and step-captioning. Specifically, we first design the modality-synergistic perception to obtain rich audio-visual content, by modeling global contrastive alignment and local fine-grained interaction between visual and audio modalities. Then, we devise the query-centric cognition that uses the deep-level query to perform the temporal-channel filtration on the shallow-level audio-visual representation. This can cognize user-preferred content and thus attain a query-centric audio-visual representation for three tasks. Extensive experiments show QUAG achieves the SOTA results on HIREST. Further, we test QUAG on the query-based video summarization task and verify its good generalization.
Distortion Recovery: A Two-Stage Method for Guitar Effect Removal
Jul 23, 2024

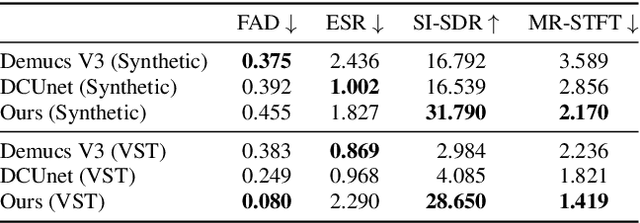

Removing audio effects from electric guitar recordings makes it easier for post-production and sound editing. An audio distortion recovery model not only improves the clarity of the guitar sounds but also opens up new opportunities for creative adjustments in mixing and mastering. While progress have been made in creating such models, previous efforts have largely focused on synthetic distortions that may be too simplistic to accurately capture the complexities seen in real-world recordings. In this paper, we tackle the task by using a dataset of guitar recordings rendered with commercial-grade audio effect VST plugins. Moreover, we introduce a novel two-stage methodology for audio distortion recovery. The idea is to firstly process the audio signal in the Mel-spectrogram domain in the first stage, and then use a neural vocoder to generate the pristine original guitar sound from the processed Mel-spectrogram in the second stage. We report a set of experiments demonstrating the effectiveness of our approach over existing methods, through both subjective and objective evaluation metrics.
Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning
Jul 16, 2024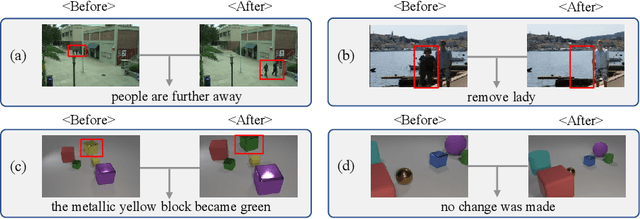
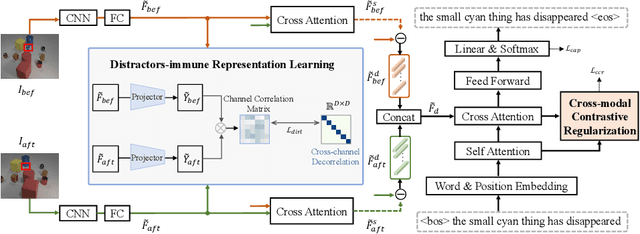
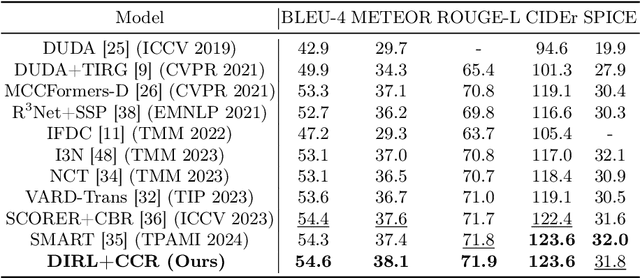
Change captioning aims to succinctly describe the semantic change between a pair of similar images, while being immune to distractors (illumination and viewpoint changes). Under these distractors, unchanged objects often appear pseudo changes about location and scale, and certain objects might overlap others, resulting in perturbational and discrimination-degraded features between two images. However, most existing methods directly capture the difference between them, which risk obtaining error-prone difference features. In this paper, we propose a distractors-immune representation learning network that correlates the corresponding channels of two image representations and decorrelates different ones in a self-supervised manner, thus attaining a pair of stable image representations under distractors. Then, the model can better interact them to capture the reliable difference features for caption generation. To yield words based on the most related difference features, we further design a cross-modal contrastive regularization, which regularizes the cross-modal alignment by maximizing the contrastive alignment between the attended difference features and generated words. Extensive experiments show that our method outperforms the state-of-the-art methods on four public datasets. The code is available at https://github.com/tuyunbin/DIRL.
A Study on Synthesizing Expressive Violin Performances: Approaches and Comparisons
Jun 26, 2024



Expressive music synthesis (EMS) for violin performance is a challenging task due to the disagreement among music performers in the interpretation of expressive musical terms (EMTs), scarcity of labeled recordings, and limited generalization ability of the synthesis model. These challenges create trade-offs between model effectiveness, diversity of generated results, and controllability of the synthesis system, making it essential to conduct a comparative study on EMS model design. This paper explores two violin EMS approaches. The end-to-end approach is a modification of a state-of-the-art text-to-speech generator. The parameter-controlled approach is based on a simple parameter sampling process that can render note lengths and other parameters compatible with MIDI-DDSP. We study these two approaches (in total, three model variants) through objective and subjective experiments and discuss several key issues of EMS based on the results.