 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKlear-AgentForge: Forging Agentic Intelligence through Posttraining Scaling
Nov 08, 2025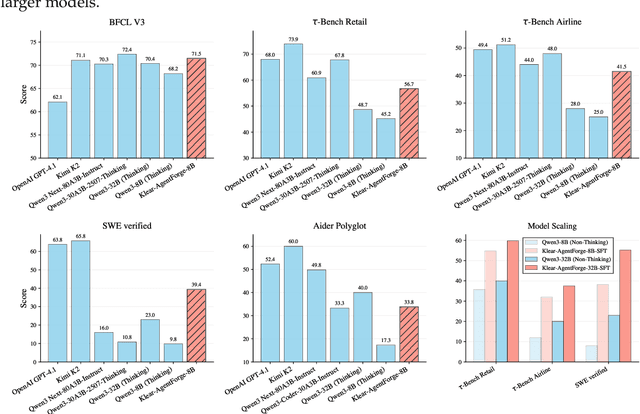
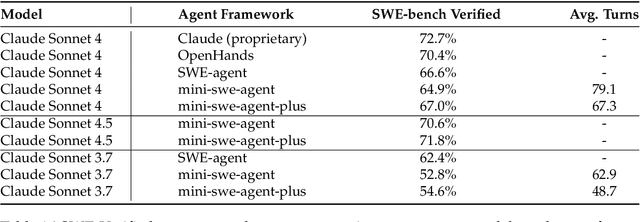
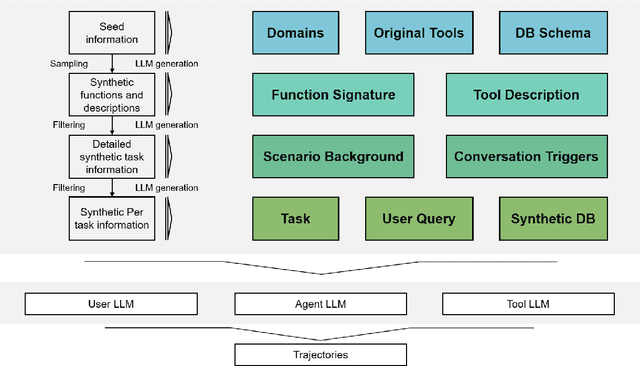
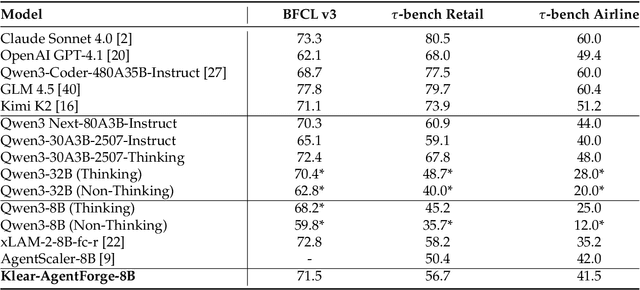
Despite the proliferation of powerful agentic models, the lack of critical post-training details hinders the development of strong counterparts in the open-source community. In this study, we present a comprehensive and fully open-source pipeline for training a high-performance agentic model for interacting with external tools and environments, named Klear-Qwen3-AgentForge, starting from the Qwen3-8B base model. We design effective supervised fine-tuning (SFT) with synthetic data followed by multi-turn reinforcement learning (RL) to unlock the potential for multiple diverse agentic tasks. We perform exclusive experiments on various agentic benchmarks in both tool use and coding domains. Klear-Qwen3-AgentForge-8B achieves state-of-the-art performance among LLMs of similar size and remains competitive with significantly larger models.
Exploring Hallucination of Large Multimodal Models in Video Understanding: Benchmark, Analysis and Mitigation
Mar 25, 2025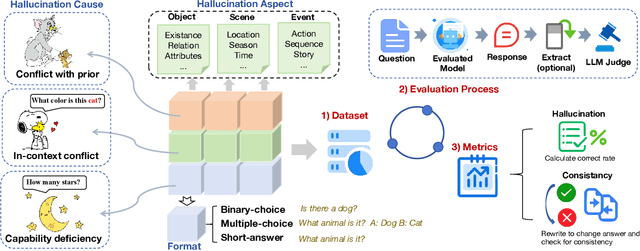
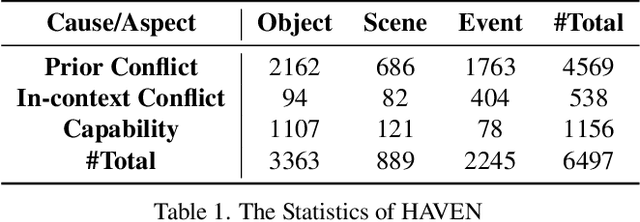
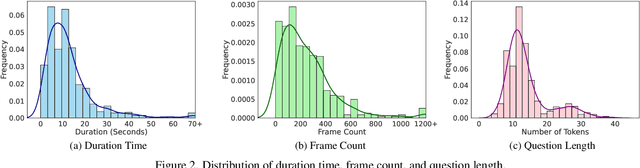
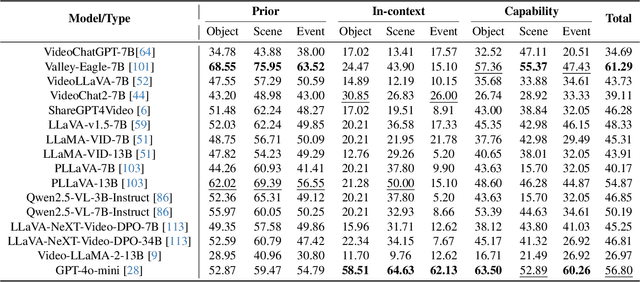
The hallucination of large multimodal models (LMMs), providing responses that appear correct but are actually incorrect, limits their reliability and applicability. This paper aims to study the hallucination problem of LMMs in video modality, which is dynamic and more challenging compared to static modalities like images and text. From this motivation, we first present a comprehensive benchmark termed HAVEN for evaluating hallucinations of LMMs in video understanding tasks. It is built upon three dimensions, i.e., hallucination causes, hallucination aspects, and question formats, resulting in 6K questions. Then, we quantitatively study 7 influential factors on hallucinations, e.g., duration time of videos, model sizes, and model reasoning, via experiments of 16 LMMs on the presented benchmark. In addition, inspired by recent thinking models like OpenAI o1, we propose a video-thinking model to mitigate the hallucinations of LMMs via supervised reasoning fine-tuning (SRFT) and direct preference optimization (TDPO)-- where SRFT enhances reasoning capabilities while TDPO reduces hallucinations in the thinking process. Extensive experiments and analyses demonstrate the effectiveness. Remarkably, it improves the baseline by 7.65% in accuracy on hallucination evaluation and reduces the bias score by 4.5%. The code and data are public at https://github.com/Hongcheng-Gao/HAVEN.
UW-SDF: Exploiting Hybrid Geometric Priors for Neural SDF Reconstruction from Underwater Multi-view Monocular Images
Oct 10, 2024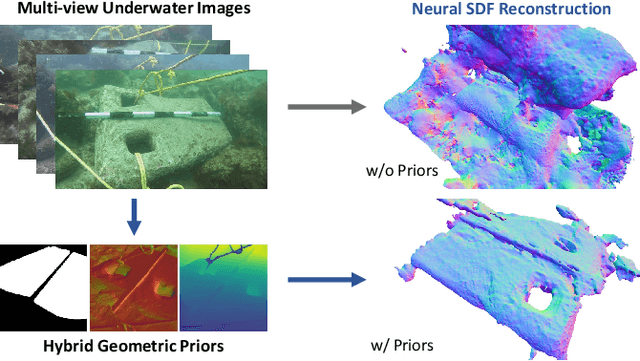
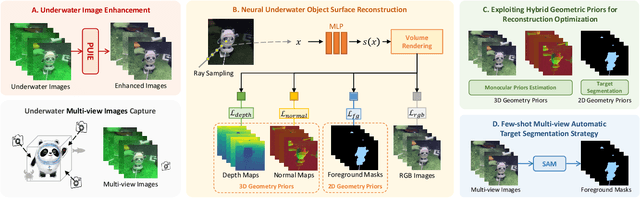
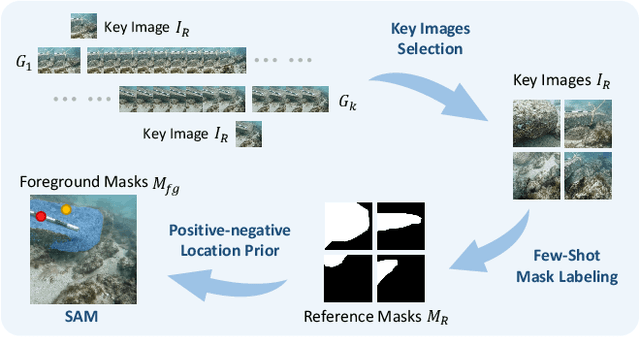
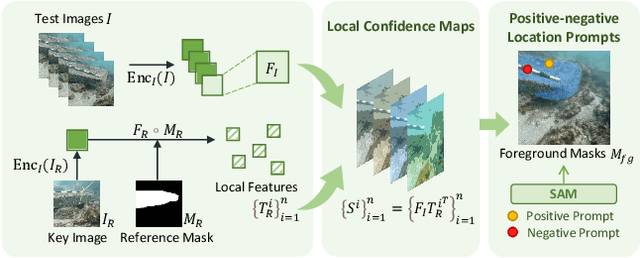
Due to the unique characteristics of underwater environments, accurate 3D reconstruction of underwater objects poses a challenging problem in tasks such as underwater exploration and mapping. Traditional methods that rely on multiple sensor data for 3D reconstruction are time-consuming and face challenges in data acquisition in underwater scenarios. We propose UW-SDF, a framework for reconstructing target objects from multi-view underwater images based on neural SDF. We introduce hybrid geometric priors to optimize the reconstruction process, markedly enhancing the quality and efficiency of neural SDF reconstruction. Additionally, to address the challenge of segmentation consistency in multi-view images, we propose a novel few-shot multi-view target segmentation strategy using the general-purpose segmentation model (SAM), enabling rapid automatic segmentation of unseen objects. Through extensive qualitative and quantitative experiments on diverse datasets, we demonstrate that our proposed method outperforms the traditional underwater 3D reconstruction method and other neural rendering approaches in the field of underwater 3D reconstruction.
FAFA: Frequency-Aware Flow-Aided Self-Supervision for Underwater Object Pose Estimation
Sep 25, 2024
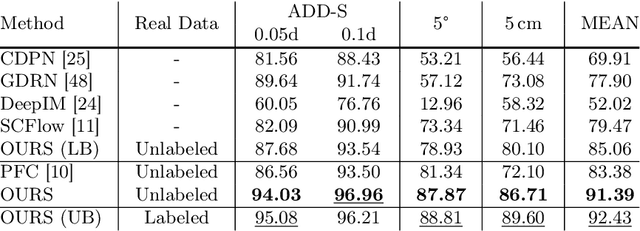


Although methods for estimating the pose of objects in indoor scenes have achieved great success, the pose estimation of underwater objects remains challenging due to difficulties brought by the complex underwater environment, such as degraded illumination, blurring, and the substantial cost of obtaining real annotations. In response, we introduce FAFA, a Frequency-Aware Flow-Aided self-supervised framework for 6D pose estimation of unmanned underwater vehicles (UUVs). Essentially, we first train a frequency-aware flow-based pose estimator on synthetic data, where an FFT-based augmentation approach is proposed to facilitate the network in capturing domain-invariant features and target domain styles from a frequency perspective. Further, we perform self-supervised training by enforcing flow-aided multi-level consistencies to adapt it to the real-world underwater environment. Our framework relies solely on the 3D model and RGB images, alleviating the need for any real pose annotations or other-modality data like depths. We evaluate the effectiveness of FAFA on common underwater object pose benchmarks and showcase significant performance improvements compared to state-of-the-art methods. Code is available at github.com/tjy0703/FAFA.