 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHINT: Hierarchical Interaction Modeling for Autoregressive Multi-Human Motion Generation
Jan 28, 2026Text-driven multi-human motion generation with complex interactions remains a challenging problem. Despite progress in performance, existing offline methods that generate fixed-length motions with a fixed number of agents, are inherently limited in handling long or variable text, and varying agent counts. These limitations naturally encourage autoregressive formulations, which predict future motions step by step conditioned on all past trajectories and current text guidance. In this work, we introduce HINT, the first autoregressive framework for multi-human motion generation with Hierarchical INTeraction modeling in diffusion. First, HINT leverages a disentangled motion representation within a canonicalized latent space, decoupling local motion semantics from inter-person interactions. This design facilitates direct adaptation to varying numbers of human participants without requiring additional refinement. Second, HINT adopts a sliding-window strategy for efficient online generation, and aggregates local within-window and global cross-window conditions to capture past human history, inter-person dependencies, and align with text guidance. This strategy not only enables fine-grained interaction modeling within each window but also preserves long-horizon coherence across all the long sequence. Extensive experiments on public benchmarks demonstrate that HINT matches the performance of strong offline models and surpasses autoregressive baselines. Notably, on InterHuman, HINT achieves an FID of 3.100, significantly improving over the previous state-of-the-art score of 5.154.
Continuous Policy and Value Iteration for Stochastic Control Problems and Its Convergence
Jun 09, 2025We introduce a continuous policy-value iteration algorithm where the approximations of the value function of a stochastic control problem and the optimal control are simultaneously updated through Langevin-type dynamics. This framework applies to both the entropy-regularized relaxed control problems and the classical control problems, with infinite horizon. We establish policy improvement and demonstrate convergence to the optimal control under the monotonicity condition of the Hamiltonian. By utilizing Langevin-type stochastic differential equations for continuous updates along the policy iteration direction, our approach enables the use of distribution sampling and non-convex learning techniques in machine learning to optimize the value function and identify the optimal control simultaneously.
GIVEPose: Gradual Intra-class Variation Elimination for RGB-based Category-Level Object Pose Estimation
Mar 20, 2025



Recent advances in RGBD-based category-level object pose estimation have been limited by their reliance on precise depth information, restricting their broader applicability. In response, RGB-based methods have been developed. Among these methods, geometry-guided pose regression that originated from instance-level tasks has demonstrated strong performance. However, we argue that the NOCS map is an inadequate intermediate representation for geometry-guided pose regression method, as its many-to-one correspondence with category-level pose introduces redundant instance-specific information, resulting in suboptimal results. This paper identifies the intra-class variation problem inherent in pose regression based solely on the NOCS map and proposes the Intra-class Variation-Free Consensus (IVFC) map, a novel coordinate representation generated from the category-level consensus model. By leveraging the complementary strengths of the NOCS map and the IVFC map, we introduce GIVEPose, a framework that implements Gradual Intra-class Variation Elimination for category-level object pose estimation. Extensive evaluations on both synthetic and real-world datasets demonstrate that GIVEPose significantly outperforms existing state-of-the-art RGB-based approaches, achieving substantial improvements in category-level object pose estimation. Our code is available at https://github.com/ziqin-h/GIVEPose.
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Dec 03, 2024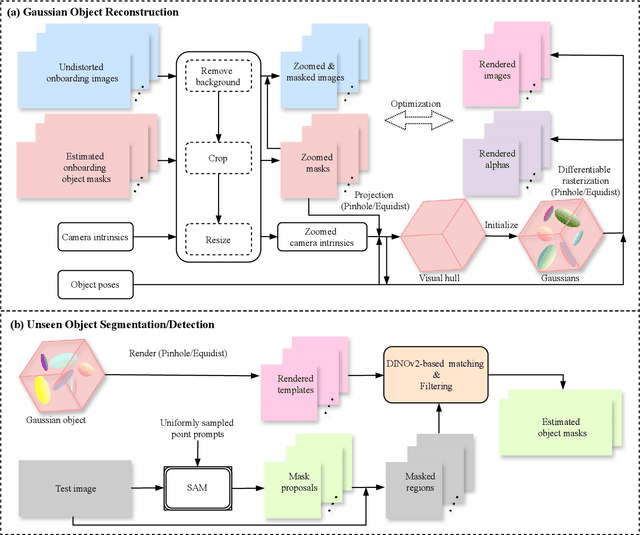

In this report, we provide the technical details of the submitted method GFreeDet, which exploits Gaussian splatting and vision Foundation models for the model-free unseen object Detection track in the BOP 2024 Challenge.
UNOPose: Unseen Object Pose Estimation with an Unposed RGB-D Reference Image
Nov 25, 2024



Unseen object pose estimation methods often rely on CAD models or multiple reference views, making the onboarding stage costly. To simplify reference acquisition, we aim to estimate the unseen object's pose through a single unposed RGB-D reference image. While previous works leverage reference images as pose anchors to limit the range of relative pose, our scenario presents significant challenges since the relative transformation could vary across the entire SE(3) space. Moreover, factors like occlusion, sensor noise, and extreme geometry could result in low viewpoint overlap. To address these challenges, we present a novel approach and benchmark, termed UNOPose, for unseen one-reference-based object pose estimation. Building upon a coarse-to-fine paradigm, UNOPose constructs an SE(3)-invariant reference frame to standardize object representation despite pose and size variations. To alleviate small overlap across viewpoints, we recalibrate the weight of each correspondence based on its predicted likelihood of being within the overlapping region. Evaluated on our proposed benchmark based on the BOP Challenge, UNOPose demonstrates superior performance, significantly outperforming traditional and learning-based methods in the one-reference setting and remaining competitive with CAD-model-based methods. The code and dataset will be available.
UW-SDF: Exploiting Hybrid Geometric Priors for Neural SDF Reconstruction from Underwater Multi-view Monocular Images
Oct 10, 2024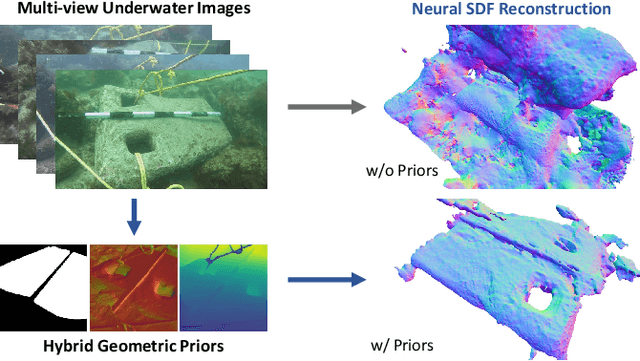
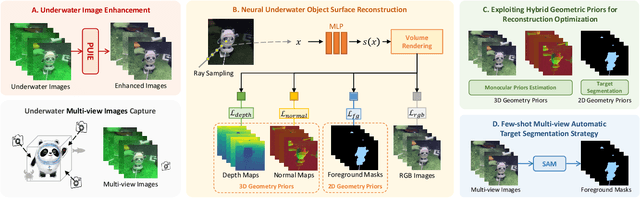
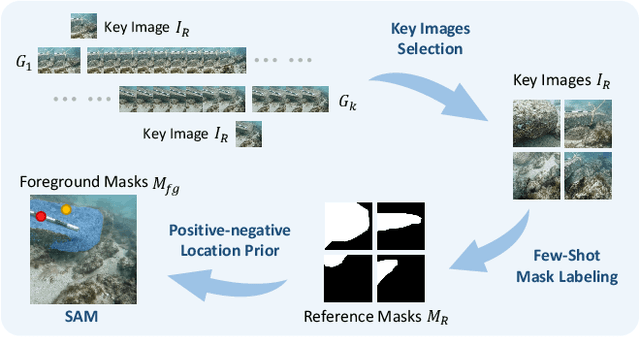
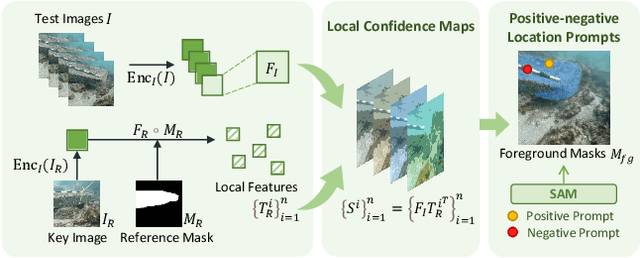
Due to the unique characteristics of underwater environments, accurate 3D reconstruction of underwater objects poses a challenging problem in tasks such as underwater exploration and mapping. Traditional methods that rely on multiple sensor data for 3D reconstruction are time-consuming and face challenges in data acquisition in underwater scenarios. We propose UW-SDF, a framework for reconstructing target objects from multi-view underwater images based on neural SDF. We introduce hybrid geometric priors to optimize the reconstruction process, markedly enhancing the quality and efficiency of neural SDF reconstruction. Additionally, to address the challenge of segmentation consistency in multi-view images, we propose a novel few-shot multi-view target segmentation strategy using the general-purpose segmentation model (SAM), enabling rapid automatic segmentation of unseen objects. Through extensive qualitative and quantitative experiments on diverse datasets, we demonstrate that our proposed method outperforms the traditional underwater 3D reconstruction method and other neural rendering approaches in the field of underwater 3D reconstruction.
FAFA: Frequency-Aware Flow-Aided Self-Supervision for Underwater Object Pose Estimation
Sep 25, 2024
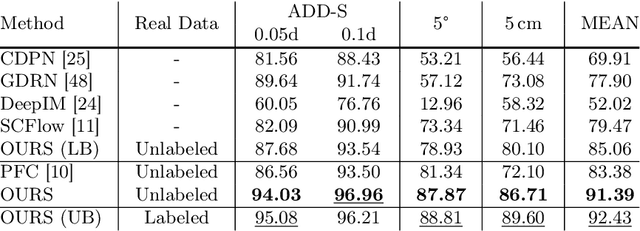


Although methods for estimating the pose of objects in indoor scenes have achieved great success, the pose estimation of underwater objects remains challenging due to difficulties brought by the complex underwater environment, such as degraded illumination, blurring, and the substantial cost of obtaining real annotations. In response, we introduce FAFA, a Frequency-Aware Flow-Aided self-supervised framework for 6D pose estimation of unmanned underwater vehicles (UUVs). Essentially, we first train a frequency-aware flow-based pose estimator on synthetic data, where an FFT-based augmentation approach is proposed to facilitate the network in capturing domain-invariant features and target domain styles from a frequency perspective. Further, we perform self-supervised training by enforcing flow-aided multi-level consistencies to adapt it to the real-world underwater environment. Our framework relies solely on the 3D model and RGB images, alleviating the need for any real pose annotations or other-modality data like depths. We evaluate the effectiveness of FAFA on common underwater object pose benchmarks and showcase significant performance improvements compared to state-of-the-art methods. Code is available at github.com/tjy0703/FAFA.
RaSim: A Range-aware High-fidelity RGB-D Data Simulation Pipeline for Real-world Applications
Apr 05, 2024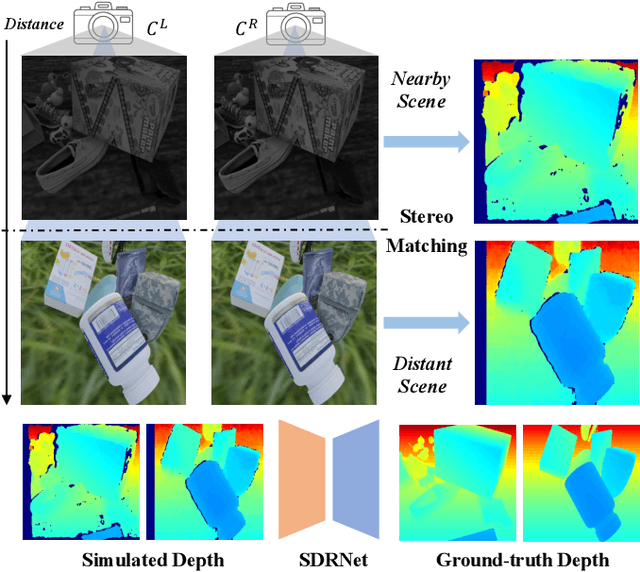
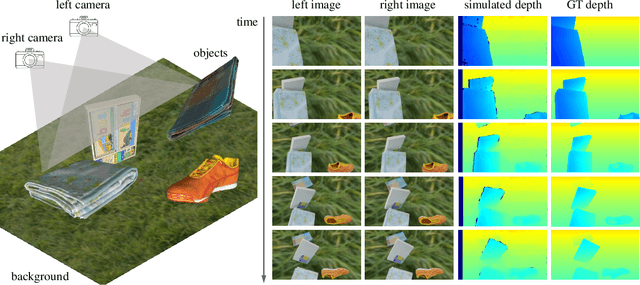
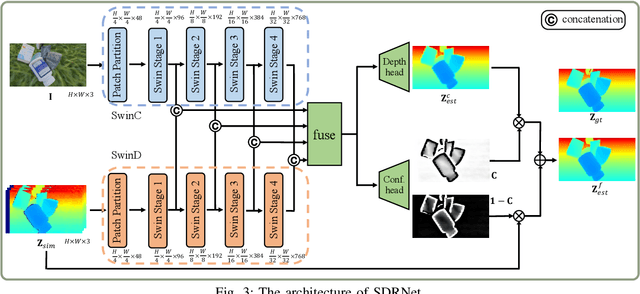
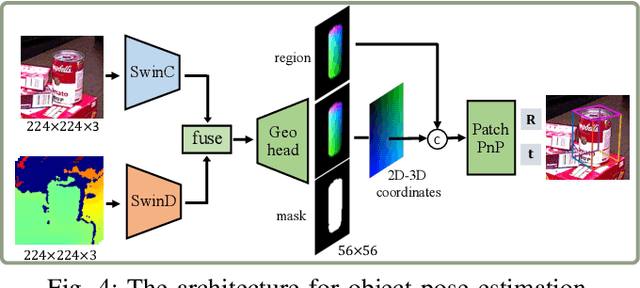
In robotic vision, a de-facto paradigm is to learn in simulated environments and then transfer to real-world applications, which poses an essential challenge in bridging the sim-to-real domain gap. While mainstream works tackle this problem in the RGB domain, we focus on depth data synthesis and develop a range-aware RGB-D data simulation pipeline (RaSim). In particular, high-fidelity depth data is generated by imitating the imaging principle of real-world sensors. A range-aware rendering strategy is further introduced to enrich data diversity. Extensive experiments show that models trained with RaSim can be directly applied to real-world scenarios without any finetuning and excel at downstream RGB-D perception tasks.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
Mar 14, 2024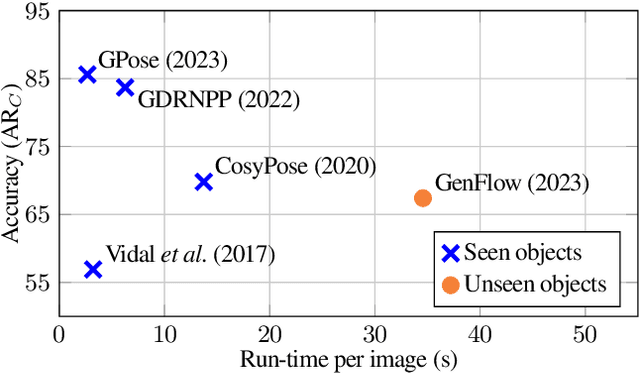


We present the evaluation methodology, datasets and results of the BOP Challenge 2023, the fifth in a series of public competitions organized to capture the state of the art in model-based 6D object pose estimation from an RGB/RGB-D image and related tasks. Besides the three tasks from 2022 (model-based 2D detection, 2D segmentation, and 6D localization of objects seen during training), the 2023 challenge introduced new variants of these tasks focused on objects unseen during training. In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models. The best 2023 method for 6D localization of unseen objects (GenFlow) notably reached the accuracy of the best 2020 method for seen objects (CosyPose), although being noticeably slower. The best 2023 method for seen objects (GPose) achieved a moderate accuracy improvement but a significant 43% run-time improvement compared to the best 2022 counterpart (GDRNPP). Since 2017, the accuracy of 6D localization of seen objects has improved by more than 50% (from 56.9 to 85.6 AR_C). The online evaluation system stays open and is available at: http://bop.felk.cvut.cz/.
HACD: Hand-Aware Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Nov 23, 2023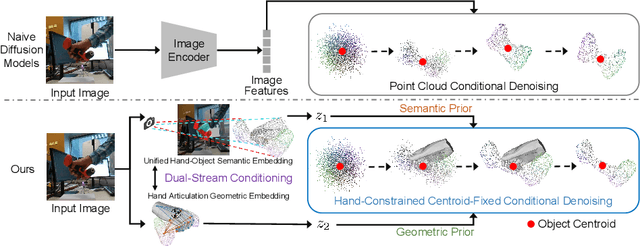
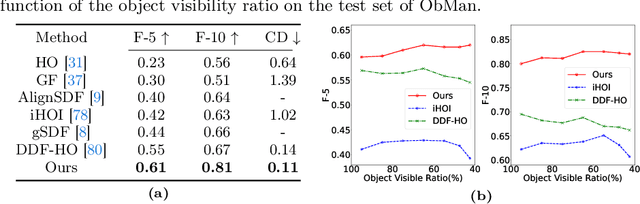
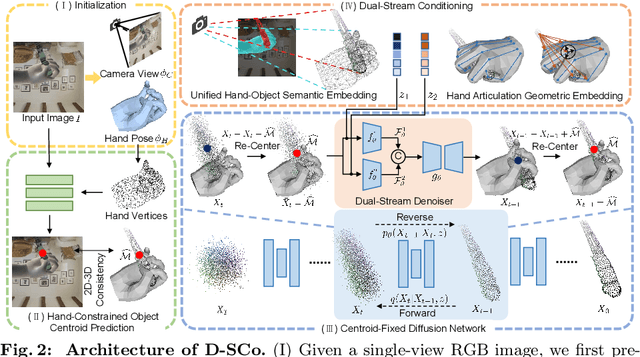
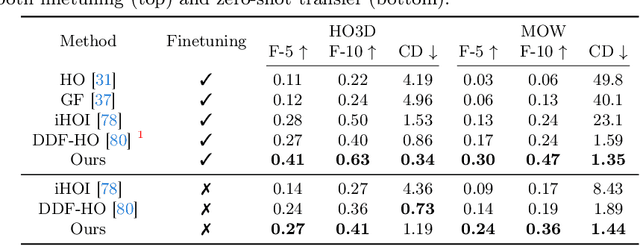
Reconstructing hand-held objects from a single RGB image without known 3D object templates, category prior, or depth information is a vital yet challenging problem in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, which make it hard to account for the uncertainties introduced by hand- and self-occlusion, we employ a probabilistic point cloud denoising diffusion model to tackle the above challenge. In this work, we present Hand-Aware Conditional Diffusion for monocular hand-held object reconstruction (HACD), modeling the hand-object interaction in two aspects. First, we introduce hand-aware conditioning to model hand-object interaction from both semantic and geometric perspectives. Specifically, a unified hand-object semantic embedding compensates for the 2D local feature deficiency induced by hand occlusion, and a hand articulation embedding further encodes the relationship between object vertices and hand joints. Second, we propose a hand-constrained centroid fixing scheme, which utilizes hand vertices priors to restrict the centroid deviation of partially denoised point cloud during diffusion and reverse process. Removing the centroid bias interference allows the diffusion models to focus on the reconstruction of shape, thus enhancing the stability and precision of local feature projection. Experiments on the synthetic ObMan dataset and two real-world datasets, HO3D and MOW, demonstrate our approach surpasses all existing methods by a large margin.