 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAct As a Real Researcher: A Suite of Benchmarks Evaluating Frontier LLMs and Agentic Harnesses in Research Lifecycle
Jun 05, 2026As foundation models advance and agent scaffolding becomes increasingly sophisticated, agents have demonstrated remarkable proficiency in complex, long-horizon coding tasks and even autonomous experiment execution. Despite their evolution from research assistants into autonomous research agents, these systems still exhibit significant limitations in field sensitivity, research ethics, and nuanced scientific judgment. Consequently, frontier agents remain unable to fully replace human researchers. To bridge this gap, we conceptualize the AARR (Act As a Real Researcher) benchmark series. Unlike existing benchmarks that primarily assess macro-level execution capabilities, AARR focuses on whether agents can emulate the professionalism, thoroughness, and nuanced reasoning that characterize human researchers in granular research scenarios. In this work, we propose AARRI-Bench (Act As a Real Research Intern), the first benchmark in this series. We conduct extensive experiments across frontier models and agentic systems, revealing that even the best-performing configuration (Mini-SWE-Agent with Claude Opus 4.7) achieves only 68.3\% success rate, frequently overlooking subtle yet critical details that are obvious to real human researchers. Our results indicate that developing researcher-like AI requires further exploration of research behavior, rather than merely complex scaffolding. Our data is released at https://github.com/AARR-bench/AARRI-bench.
The Second Challenge on Cross-Domain Few-Shot Object Detection at NTIRE 2026: Methods and Results
Apr 13, 2026Cross-domain few-shot object detection (CD-FSOD) remains a challenging problem for existing object detectors and few-shot learning approaches, particularly when generalizing across distinct domains. As part of NTIRE 2026, we hosted the second CD-FSOD Challenge to systematically evaluate and promote progress in detecting objects in unseen target domains under limited annotation conditions. The challenge received strong community interest, with 128 registered participants and a total of 696 submissions. Among them, 31 teams actively participated, and 19 teams submitted valid final results. Participants explored a wide range of strategies, introducing innovative methods that push the performance frontier under both open-source and closed-source tracks. This report presents a detailed overview of the NTIRE 2026 CD-FSOD Challenge, including a summary of the submitted approaches and an analysis of the final results across all participating teams. Challenge Codes: https://github.com/ohMargin/NTIRE2026_CDFSOD.
ZoomEarth: Active Perception for Ultra-High-Resolution Geospatial Vision-Language Tasks
Nov 15, 2025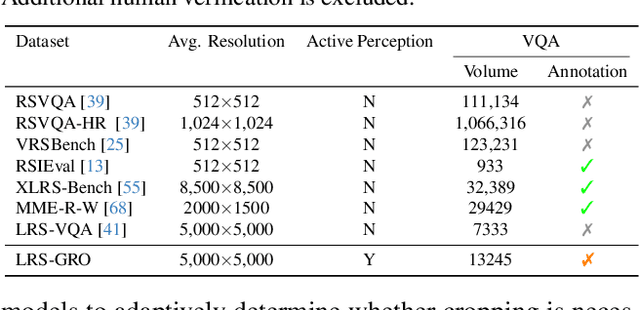
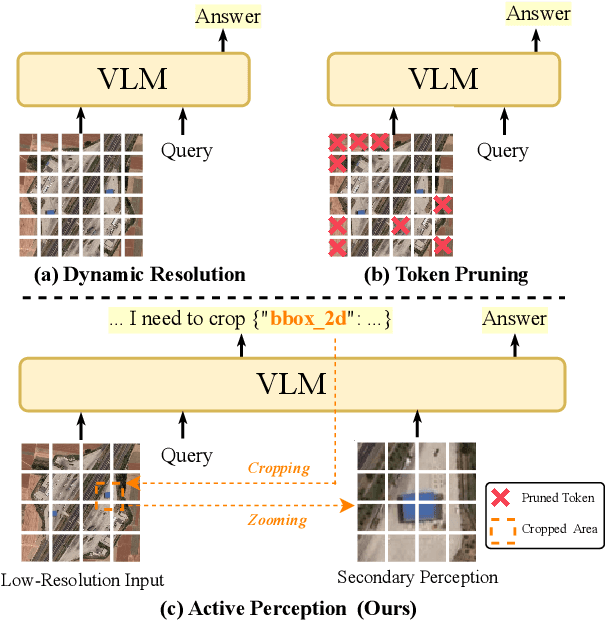
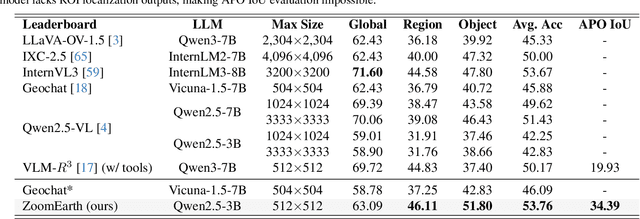
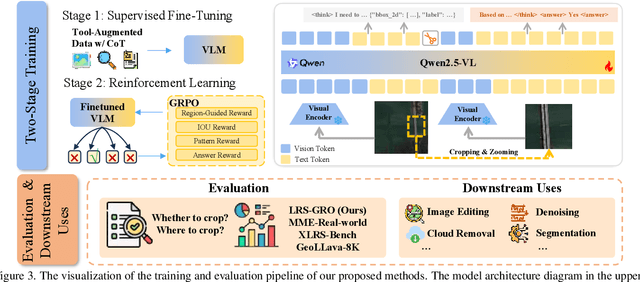
Ultra-high-resolution (UHR) remote sensing (RS) images offer rich fine-grained information but also present challenges in effective processing. Existing dynamic resolution and token pruning methods are constrained by a passive perception paradigm, suffering from increased redundancy when obtaining finer visual inputs. In this work, we explore a new active perception paradigm that enables models to revisit information-rich regions. First, we present LRS-GRO, a large-scale benchmark dataset tailored for active perception in UHR RS processing, encompassing 17 question types across global, region, and object levels, annotated via a semi-automatic pipeline. Building on LRS-GRO, we propose ZoomEarth, an adaptive cropping-zooming framework with a novel Region-Guided reward that provides fine-grained guidance. Trained via supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO), ZoomEarth achieves state-of-the-art performance on LRS-GRO and, in the zero-shot setting, on three public UHR remote sensing benchmarks. Furthermore, ZoomEarth can be seamlessly integrated with downstream models for tasks such as cloud removal, denoising, segmentation, and image editing through simple tool interfaces, demonstrating strong versatility and extensibility.
HACD: Hand-Aware Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Nov 23, 2023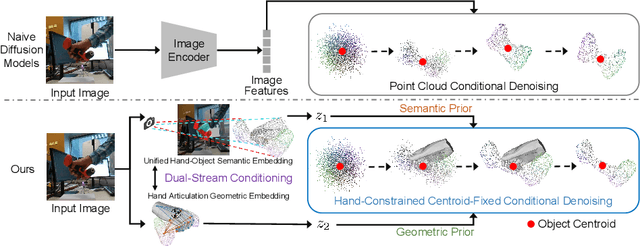
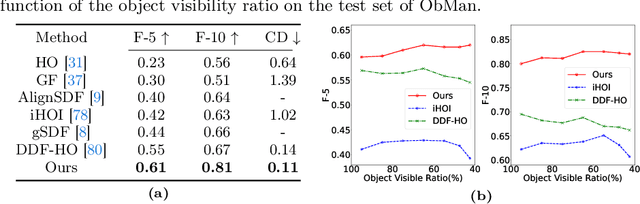
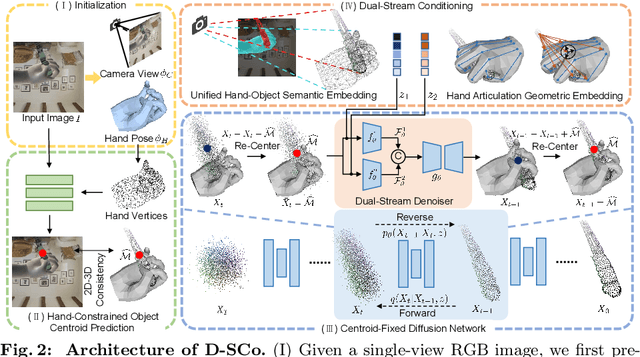
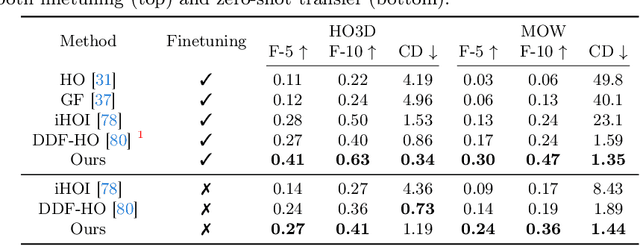
Reconstructing hand-held objects from a single RGB image without known 3D object templates, category prior, or depth information is a vital yet challenging problem in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, which make it hard to account for the uncertainties introduced by hand- and self-occlusion, we employ a probabilistic point cloud denoising diffusion model to tackle the above challenge. In this work, we present Hand-Aware Conditional Diffusion for monocular hand-held object reconstruction (HACD), modeling the hand-object interaction in two aspects. First, we introduce hand-aware conditioning to model hand-object interaction from both semantic and geometric perspectives. Specifically, a unified hand-object semantic embedding compensates for the 2D local feature deficiency induced by hand occlusion, and a hand articulation embedding further encodes the relationship between object vertices and hand joints. Second, we propose a hand-constrained centroid fixing scheme, which utilizes hand vertices priors to restrict the centroid deviation of partially denoised point cloud during diffusion and reverse process. Removing the centroid bias interference allows the diffusion models to focus on the reconstruction of shape, thus enhancing the stability and precision of local feature projection. Experiments on the synthetic ObMan dataset and two real-world datasets, HO3D and MOW, demonstrate our approach surpasses all existing methods by a large margin.
ShapeMaker: Self-Supervised Joint Shape Canonicalization, Segmentation, Retrieval and Deformation
Nov 18, 2023In this paper, we present ShapeMaker, a unified self-supervised learning framework for joint shape canonicalization, segmentation, retrieval and deformation. Given a partially-observed object in an arbitrary pose, we first canonicalize the object by extracting point-wise affine-invariant features, disentangling inherent structure of the object with its pose and size. These learned features are then leveraged to predict semantically consistent part segmentation and corresponding part centers. Next, our lightweight retrieval module aggregates the features within each part as its retrieval token and compare all the tokens with source shapes from a pre-established database to identify the most geometrically similar shape. Finally, we deform the retrieved shape in the deformation module to tightly fit the input object by harnessing part center guided neural cage deformation. The key insight of ShapeMaker is the simultaneous training of the four highly-associated processes: canonicalization, segmentation, retrieval, and deformation, leveraging cross-task consistency losses for mutual supervision. Extensive experiments on synthetic datasets PartNet, ComplementMe, and real-world dataset Scan2CAD demonstrate that ShapeMaker surpasses competitors by a large margin. Codes will be released soon.
LanPose: Language-Instructed 6D Object Pose Estimation for Robotic Assembly
Oct 20, 2023
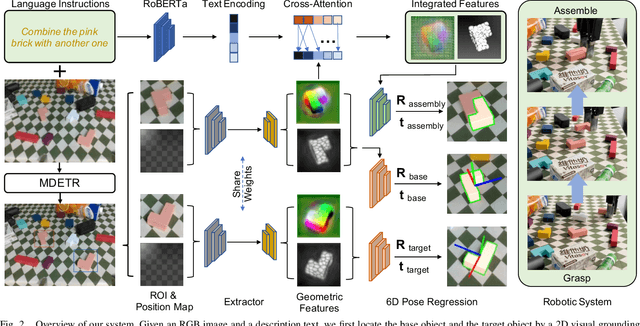


Comprehending natural language instructions is a critical skill for robots to cooperate effectively with humans. In this paper, we aim to learn 6D poses for roboticassembly by natural language instructions. For this purpose, Language-Instructed 6D Pose Regression Network (LanPose) is proposed to jointly predict the 6D poses of the observed object and the corresponding assembly position. Our proposed approach is based on the fusion of geometric and linguistic features, which allows us to finely integrate multi-modality input and map it to the 6D pose in SE(3) space by the cross-attention mechanism and the language-integrated 6D pose mapping module, respectively. To validate the effectiveness of our approach, an integrated robotic system is established to precisely and robustly perceive, grasp, manipulate and assemble blocks by language commands. 98.09 and 93.55 in ADD(-S)-0.1d are derived for the prediction of 6D object pose and 6D assembly pose, respectively. Both quantitative and qualitative results demonstrate the effectiveness of our proposed language-instructed 6D pose estimation methodology and its potential to enable robots to better understand and execute natural language instructions.
MOHO: Learning Single-view Hand-held Object Reconstruction with Multi-view Occlusion-Aware Supervision
Oct 18, 2023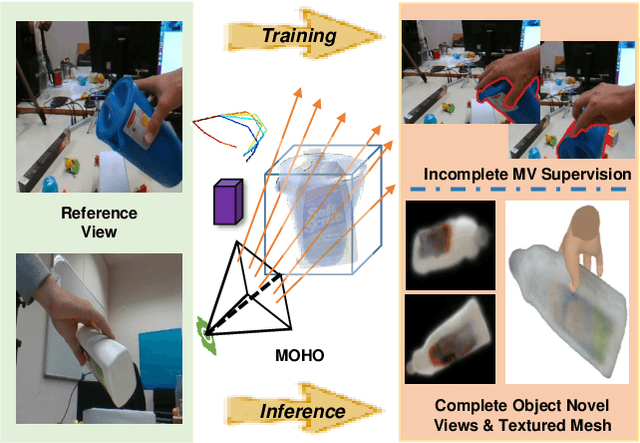
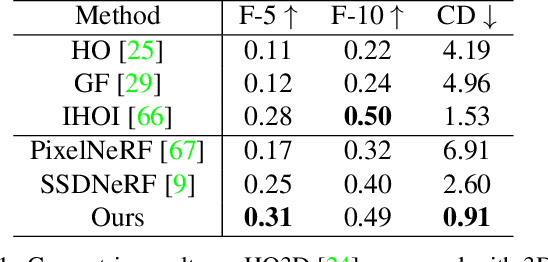
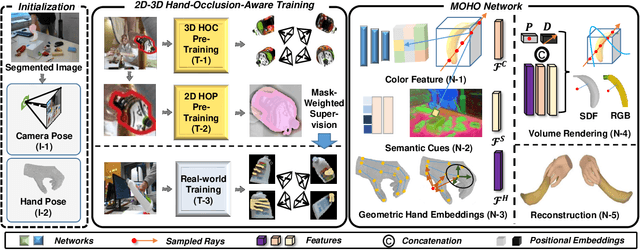
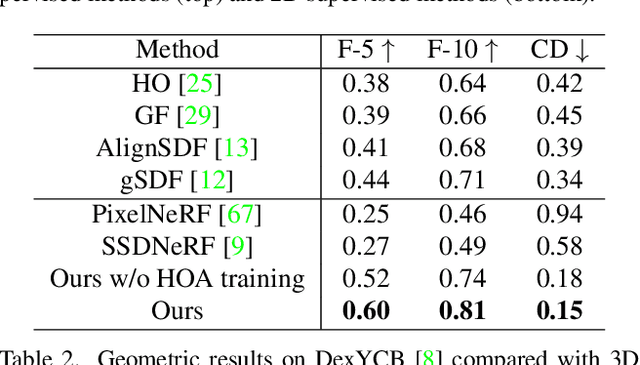
Previous works concerning single-view hand-held object reconstruction typically utilize supervision from 3D ground truth models, which are hard to collect in real world. In contrast, abundant videos depicting hand-object interactions can be accessed easily with low cost, although they only give partial object observations with complex occlusion. In this paper, we present MOHO to reconstruct hand-held object from a single image with multi-view supervision from hand-object videos, tackling two predominant challenges including object's self-occlusion and hand-induced occlusion. MOHO inputs semantic features indicating visible object parts and geometric embeddings provided by hand articulations as partial-to-full cues to resist object's self-occlusion, so as to recover full shape of the object. Meanwhile, a novel 2D-3D hand-occlusion-aware training scheme following the synthetic-to-real paradigm is proposed to release hand-induced occlusion. In the synthetic pre-training stage, 2D-3D hand-object correlations are constructed by supervising MOHO with rendered images to complete the hand-concealed regions of the object in both 2D and 3D space. Subsequently, MOHO is finetuned in real world by the mask-weighted volume rendering supervision adopting hand-object correlations obtained during pre-training. Extensive experiments on HO3D and DexYCB datasets demonstrate that 2D-supervised MOHO gains superior results against 3D-supervised methods by a large margin. Codes and key assets will be released soon.
6D Robotic Assembly Based on RGB-only Object Pose Estimation
Aug 27, 2022
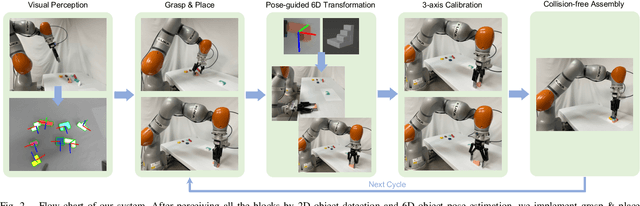
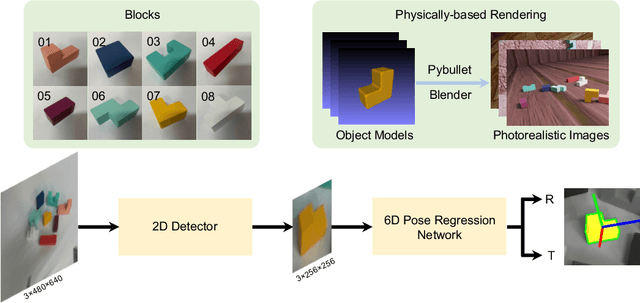

Vision-based robotic assembly is a crucial yet challenging task as the interaction with multiple objects requires high levels of precision. In this paper, we propose an integrated 6D robotic system to perceive, grasp, manipulate and assemble blocks with tight tolerances. Aiming to provide an off-the-shelf RGB-only solution, our system is built upon a monocular 6D object pose estimation network trained solely with synthetic images leveraging physically-based rendering. Subsequently, pose-guided 6D transformation along with collision-free assembly is proposed to construct any designed structure with arbitrary initial poses. Our novel 3-axis calibration operation further enhances the precision and robustness by disentangling 6D pose estimation and robotic assembly. Both quantitative and qualitative results demonstrate the effectiveness of our proposed 6D robotic assembly system.