 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Dec 03, 2024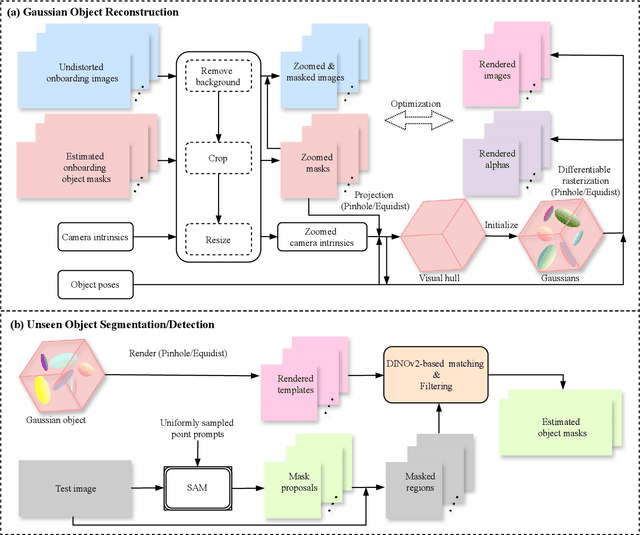

In this report, we provide the technical details of the submitted method GFreeDet, which exploits Gaussian splatting and vision Foundation models for the model-free unseen object Detection track in the BOP 2024 Challenge.
HACD: Hand-Aware Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Nov 23, 2023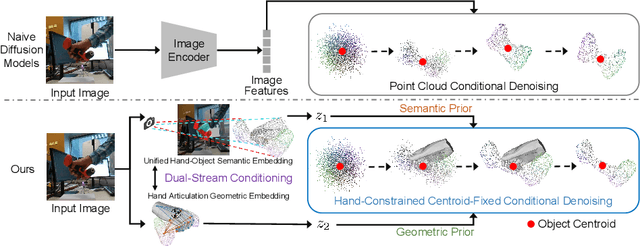
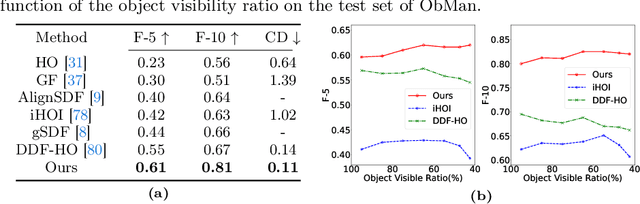
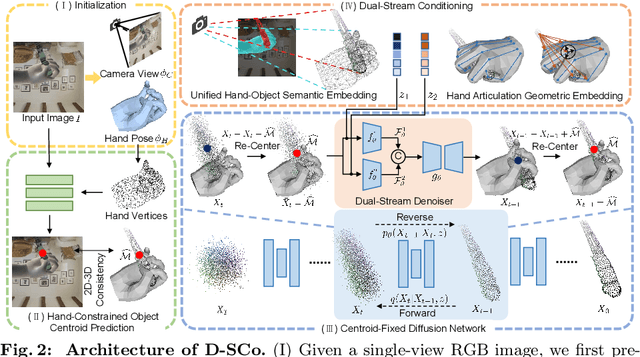
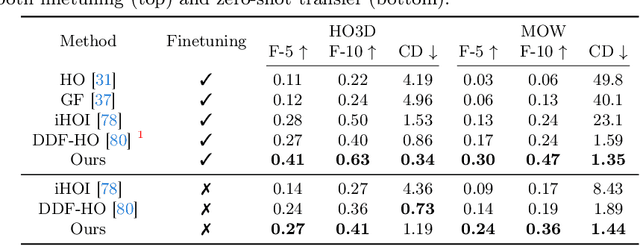
Reconstructing hand-held objects from a single RGB image without known 3D object templates, category prior, or depth information is a vital yet challenging problem in computer vision. In contrast to prior works that utilize deterministic modeling paradigms, which make it hard to account for the uncertainties introduced by hand- and self-occlusion, we employ a probabilistic point cloud denoising diffusion model to tackle the above challenge. In this work, we present Hand-Aware Conditional Diffusion for monocular hand-held object reconstruction (HACD), modeling the hand-object interaction in two aspects. First, we introduce hand-aware conditioning to model hand-object interaction from both semantic and geometric perspectives. Specifically, a unified hand-object semantic embedding compensates for the 2D local feature deficiency induced by hand occlusion, and a hand articulation embedding further encodes the relationship between object vertices and hand joints. Second, we propose a hand-constrained centroid fixing scheme, which utilizes hand vertices priors to restrict the centroid deviation of partially denoised point cloud during diffusion and reverse process. Removing the centroid bias interference allows the diffusion models to focus on the reconstruction of shape, thus enhancing the stability and precision of local feature projection. Experiments on the synthetic ObMan dataset and two real-world datasets, HO3D and MOW, demonstrate our approach surpasses all existing methods by a large margin.
MOHO: Learning Single-view Hand-held Object Reconstruction with Multi-view Occlusion-Aware Supervision
Oct 18, 2023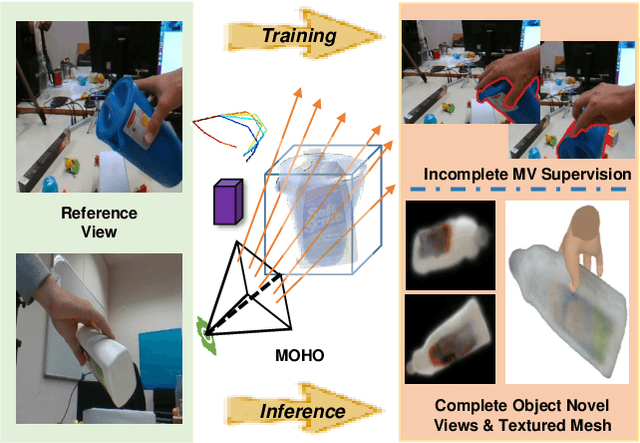
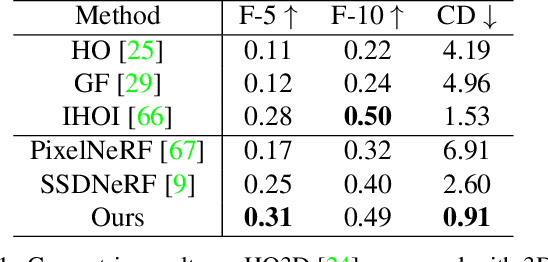
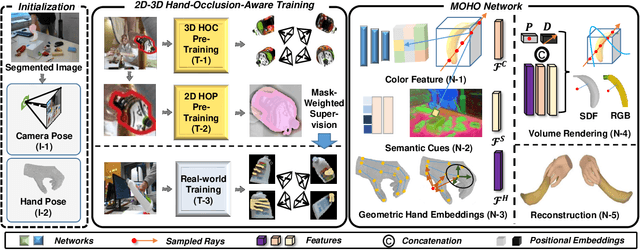
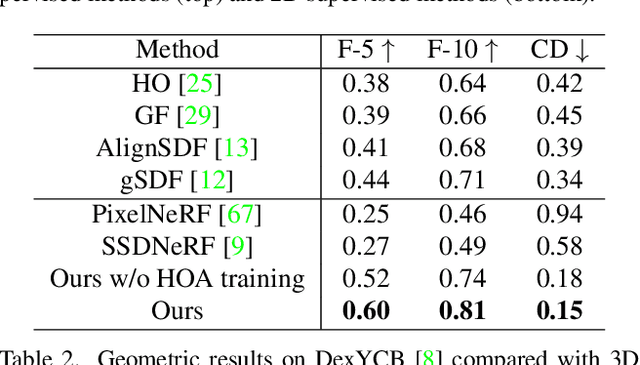
Previous works concerning single-view hand-held object reconstruction typically utilize supervision from 3D ground truth models, which are hard to collect in real world. In contrast, abundant videos depicting hand-object interactions can be accessed easily with low cost, although they only give partial object observations with complex occlusion. In this paper, we present MOHO to reconstruct hand-held object from a single image with multi-view supervision from hand-object videos, tackling two predominant challenges including object's self-occlusion and hand-induced occlusion. MOHO inputs semantic features indicating visible object parts and geometric embeddings provided by hand articulations as partial-to-full cues to resist object's self-occlusion, so as to recover full shape of the object. Meanwhile, a novel 2D-3D hand-occlusion-aware training scheme following the synthetic-to-real paradigm is proposed to release hand-induced occlusion. In the synthetic pre-training stage, 2D-3D hand-object correlations are constructed by supervising MOHO with rendered images to complete the hand-concealed regions of the object in both 2D and 3D space. Subsequently, MOHO is finetuned in real world by the mask-weighted volume rendering supervision adopting hand-object correlations obtained during pre-training. Extensive experiments on HO3D and DexYCB datasets demonstrate that 2D-supervised MOHO gains superior results against 3D-supervised methods by a large margin. Codes and key assets will be released soon.