 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunRec: Reconstructing Functional 3D Scenes from Egocentric Interaction Videos
Apr 07, 2026We present FunRec, a method for reconstructing functional 3D digital twins of indoor scenes directly from egocentric RGB-D interaction videos. Unlike existing methods on articulated reconstruction, which rely on controlled setups, multi-state captures, or CAD priors, FunRec operates directly on in-the-wild human interaction sequences to recover interactable 3D scenes. It automatically discovers articulated parts, estimates their kinematic parameters, tracks their 3D motion, and reconstructs static and moving geometry in canonical space, yielding simulation-compatible meshes. Across new real and simulated benchmarks, FunRec surpasses prior work by a large margin, achieving up to +50 mIoU improvement in part segmentation, 5-10 times lower articulation and pose errors, and significantly higher reconstruction accuracy. We further demonstrate applications on URDF/USD export for simulation, hand-guided affordance mapping and robot-scene interaction.
Controllable Egocentric Video Generation via Occlusion-Aware Sparse 3D Hand Joints
Mar 12, 2026Motion-controllable video generation is crucial for egocentric applications in virtual reality and embodied AI. However, existing methods often struggle to achieve 3D-consistent fine-grained hand articulation. By adopting on 2D trajectories or implicit poses, they collapse 3D geometry into spatially ambiguous signals or over rely on human-centric priors. Under severe egocentric occlusions, this causes motion inconsistencies and hallucinated artifacts, as well as preventing cross-embodiment generalization to robotic hands. To address these limitations, we propose a novel framework that generates egocentric videos from a single reference frame, leveraging sparse 3D hand joints as embodiment-agnostic control signals with clear semantic and geometric structures. We introduce an efficient control module that resolves occlusion ambiguities while fully preserving 3D information. Specifically, it extracts occlusion-aware features from the source reference frame by penalizing unreliable visual signals from hidden joints, and employs a 3D-based weighting mechanism to robustly handle dynamically occluded target joints during motion propagation. Concurrently, the module directly injects 3D geometric embeddings into the latent space to strictly enforce structural consistency. To facilitate robust training and evaluation, we develop an automated annotation pipeline that yields over one million high-quality egocentric video clips paired with precise hand trajectories. Additionally, we register humanoid kinematic and camera data to construct a cross-embodiment benchmark. Extensive experiments demonstrate that our approach significantly outperforms state-of-the-art baselines, generating high-fidelity egocentric videos with realistic interactions and exhibiting exceptional cross-embodiment generalization to robotic hands.
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025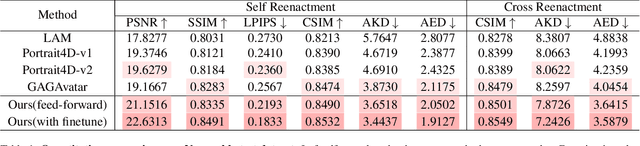
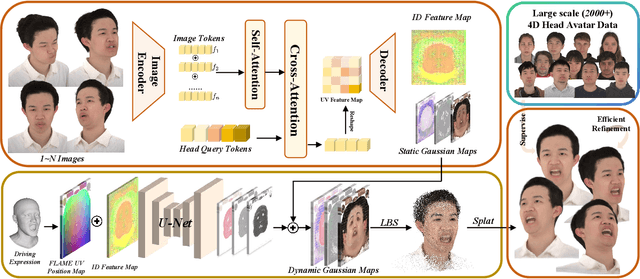
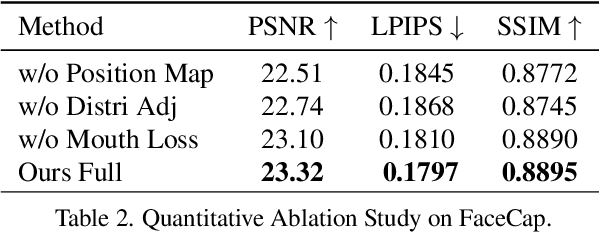

We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
Interaction-Aware 4D Gaussian Splatting for Dynamic Hand-Object Interaction Reconstruction
Nov 18, 2025This paper focuses on a challenging setting of simultaneously modeling geometry and appearance of hand-object interaction scenes without any object priors. We follow the trend of dynamic 3D Gaussian Splatting based methods, and address several significant challenges. To model complex hand-object interaction with mutual occlusion and edge blur, we present interaction-aware hand-object Gaussians with newly introduced optimizable parameters aiming to adopt piecewise linear hypothesis for clearer structural representation. Moreover, considering the complementarity and tightness of hand shape and object shape during interaction dynamics, we incorporate hand information into object deformation field, constructing interaction-aware dynamic fields to model flexible motions. To further address difficulties in the optimization process, we propose a progressive strategy that handles dynamic regions and static background step by step. Correspondingly, explicit regularizations are designed to stabilize the hand-object representations for smooth motion transition, physical interaction reality, and coherent lighting. Experiments show that our approach surpasses existing dynamic 3D-GS-based methods and achieves state-of-the-art performance in reconstructing dynamic hand-object interaction.
Open-Vocabulary Functional 3D Scene Graphs for Real-World Indoor Spaces
Mar 24, 2025



We introduce the task of predicting functional 3D scene graphs for real-world indoor environments from posed RGB-D images. Unlike traditional 3D scene graphs that focus on spatial relationships of objects, functional 3D scene graphs capture objects, interactive elements, and their functional relationships. Due to the lack of training data, we leverage foundation models, including visual language models (VLMs) and large language models (LLMs), to encode functional knowledge. We evaluate our approach on an extended SceneFun3D dataset and a newly collected dataset, FunGraph3D, both annotated with functional 3D scene graphs. Our method significantly outperforms adapted baselines, including Open3DSG and ConceptGraph, demonstrating its effectiveness in modeling complex scene functionalities. We also demonstrate downstream applications such as 3D question answering and robotic manipulation using functional 3D scene graphs. See our project page at https://openfungraph.github.io
GIVEPose: Gradual Intra-class Variation Elimination for RGB-based Category-Level Object Pose Estimation
Mar 20, 2025



Recent advances in RGBD-based category-level object pose estimation have been limited by their reliance on precise depth information, restricting their broader applicability. In response, RGB-based methods have been developed. Among these methods, geometry-guided pose regression that originated from instance-level tasks has demonstrated strong performance. However, we argue that the NOCS map is an inadequate intermediate representation for geometry-guided pose regression method, as its many-to-one correspondence with category-level pose introduces redundant instance-specific information, resulting in suboptimal results. This paper identifies the intra-class variation problem inherent in pose regression based solely on the NOCS map and proposes the Intra-class Variation-Free Consensus (IVFC) map, a novel coordinate representation generated from the category-level consensus model. By leveraging the complementary strengths of the NOCS map and the IVFC map, we introduce GIVEPose, a framework that implements Gradual Intra-class Variation Elimination for category-level object pose estimation. Extensive evaluations on both synthetic and real-world datasets demonstrate that GIVEPose significantly outperforms existing state-of-the-art RGB-based approaches, achieving substantial improvements in category-level object pose estimation. Our code is available at https://github.com/ziqin-h/GIVEPose.
FA-BARF: Frequency Adapted Bundle-Adjusting Neural Radiance Fields
Mar 15, 2025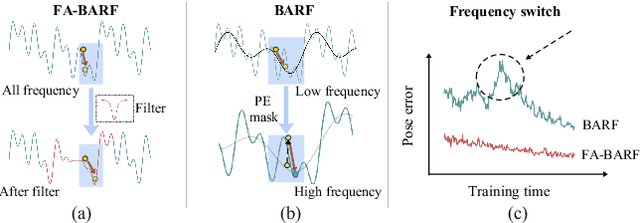
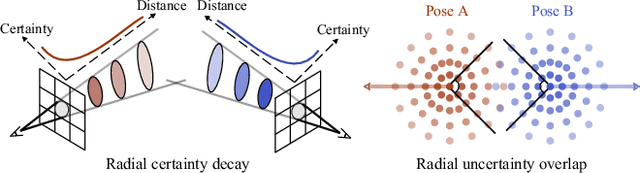
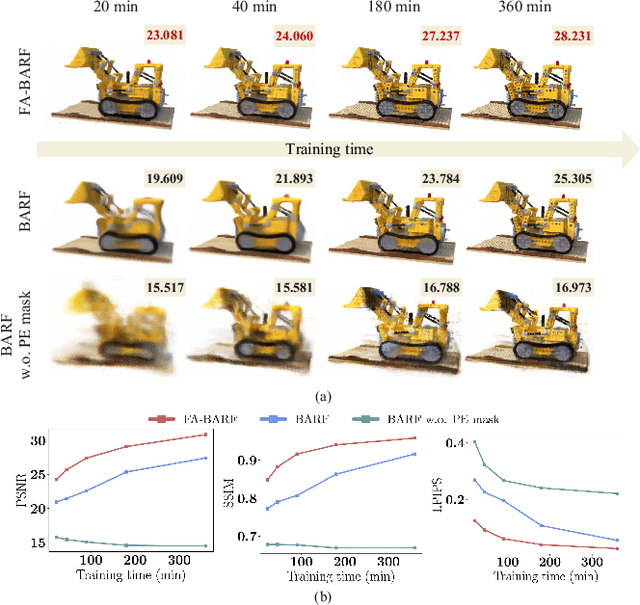
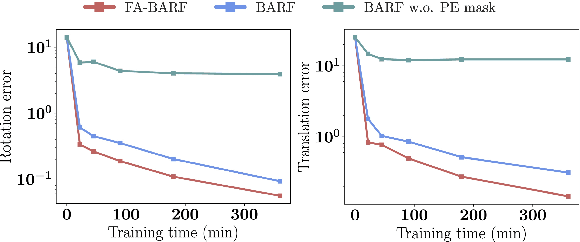
Neural Radiance Fields (NeRF) have exhibited highly effective performance for photorealistic novel view synthesis recently. However, the key limitation it meets is the reliance on a hand-crafted frequency annealing strategy to recover 3D scenes with imperfect camera poses. The strategy exploits a temporal low-pass filter to guarantee convergence while decelerating the joint optimization of implicit scene reconstruction and camera registration. In this work, we introduce the Frequency Adapted Bundle Adjusting Radiance Field (FA-BARF), substituting the temporal low-pass filter for a frequency-adapted spatial low-pass filter to address the decelerating problem. We establish a theoretical framework to interpret the relationship between position encoding of NeRF and camera registration and show that our frequency-adapted filter can mitigate frequency fluctuation caused by the temporal filter. Furthermore, we show that applying a spatial low-pass filter in NeRF can optimize camera poses productively through radial uncertainty overlaps among various views. Extensive experiments show that FA-BARF can accelerate the joint optimization process under little perturbations in object-centric scenes and recover real-world scenes with unknown camera poses. This implies wider possibilities for NeRF applied in dense 3D mapping and reconstruction under real-time requirements. The code will be released upon paper acceptance.
Street Gaussians without 3D Object Tracker
Dec 07, 2024



Realistic scene reconstruction in driving scenarios poses significant challenges due to fast-moving objects. Most existing methods rely on labor-intensive manual labeling of object poses to reconstruct dynamic objects in canonical space and move them based on these poses during rendering. While some approaches attempt to use 3D object trackers to replace manual annotations, the limited generalization of 3D trackers -- caused by the scarcity of large-scale 3D datasets -- results in inferior reconstructions in real-world settings. In contrast, 2D foundation models demonstrate strong generalization capabilities. To eliminate the reliance on 3D trackers and enhance robustness across diverse environments, we propose a stable object tracking module by leveraging associations from 2D deep trackers within a 3D object fusion strategy. We address inevitable tracking errors by further introducing a motion learning strategy in an implicit feature space that autonomously corrects trajectory errors and recovers missed detections. Experimental results on Waymo-NOTR datasets show we achieve state-of-the-art performance. Our code will be made publicly available.
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Dec 03, 2024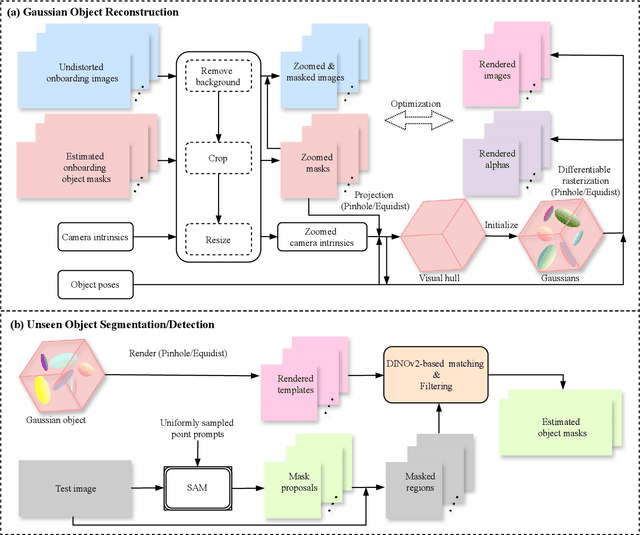

In this report, we provide the technical details of the submitted method GFreeDet, which exploits Gaussian splatting and vision Foundation models for the model-free unseen object Detection track in the BOP 2024 Challenge.
UNOPose: Unseen Object Pose Estimation with an Unposed RGB-D Reference Image
Nov 25, 2024



Unseen object pose estimation methods often rely on CAD models or multiple reference views, making the onboarding stage costly. To simplify reference acquisition, we aim to estimate the unseen object's pose through a single unposed RGB-D reference image. While previous works leverage reference images as pose anchors to limit the range of relative pose, our scenario presents significant challenges since the relative transformation could vary across the entire SE(3) space. Moreover, factors like occlusion, sensor noise, and extreme geometry could result in low viewpoint overlap. To address these challenges, we present a novel approach and benchmark, termed UNOPose, for unseen one-reference-based object pose estimation. Building upon a coarse-to-fine paradigm, UNOPose constructs an SE(3)-invariant reference frame to standardize object representation despite pose and size variations. To alleviate small overlap across viewpoints, we recalibrate the weight of each correspondence based on its predicted likelihood of being within the overlapping region. Evaluated on our proposed benchmark based on the BOP Challenge, UNOPose demonstrates superior performance, significantly outperforming traditional and learning-based methods in the one-reference setting and remaining competitive with CAD-model-based methods. The code and dataset will be available.