 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaDA2.0: Scaling Up Diffusion Language Models to 100B
Dec 24, 2025This paper presents LLaDA2.0 -- a tuple of discrete diffusion large language models (dLLM) scaling up to 100B total parameters through systematic conversion from auto-regressive (AR) models -- establishing a new paradigm for frontier-scale deployment. Instead of costly training from scratch, LLaDA2.0 upholds knowledge inheritance, progressive adaption and efficiency-aware design principle, and seamless converts a pre-trained AR model into dLLM with a novel 3-phase block-level WSD based training scheme: progressive increasing block-size in block diffusion (warm-up), large-scale full-sequence diffusion (stable) and reverting back to compact-size block diffusion (decay). Along with post-training alignment with SFT and DPO, we obtain LLaDA2.0-mini (16B) and LLaDA2.0-flash (100B), two instruction-tuned Mixture-of-Experts (MoE) variants optimized for practical deployment. By preserving the advantages of parallel decoding, these models deliver superior performance and efficiency at the frontier scale. Both models were open-sourced.
From Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
Jul 09, 2025



Reinforcement learning with verifiable rewards (RLVR) has recently advanced the reasoning capabilities of large language models (LLMs). While prior work has emphasized algorithmic design, data curation, and reward shaping, we investigate RLVR from a sample-centric perspective and introduce LPPO (Learning-Progress and Prefix-guided Optimization), a framework of progressive optimization techniques. Our work addresses a critical question: how to best leverage a small set of trusted, high-quality demonstrations, rather than simply scaling up data volume. First, motivated by how hints aid human problem-solving, we propose prefix-guided sampling, an online data augmentation method that incorporates partial solution prefixes from expert demonstrations to guide the policy, particularly for challenging instances. Second, inspired by how humans focus on important questions aligned with their current capabilities, we introduce learning-progress weighting, a dynamic strategy that adjusts each training sample's influence based on model progression. We estimate sample-level learning progress via an exponential moving average of per-sample pass rates, promoting samples that foster learning and de-emphasizing stagnant ones. Experiments on mathematical-reasoning benchmarks demonstrate that our methods outperform strong baselines, yielding faster convergence and a higher performance ceiling.
Efficient and Adaptive Simultaneous Speech Translation with Fully Unidirectional Architecture
Apr 16, 2025



Simultaneous speech translation (SimulST) produces translations incrementally while processing partial speech input. Although large language models (LLMs) have showcased strong capabilities in offline translation tasks, applying them to SimulST poses notable challenges. Existing LLM-based SimulST approaches either incur significant computational overhead due to repeated encoding of bidirectional speech encoder, or they depend on a fixed read/write policy, limiting the efficiency and performance. In this work, we introduce Efficient and Adaptive Simultaneous Speech Translation (EASiST) with fully unidirectional architecture, including both speech encoder and LLM. EASiST includes a multi-latency data curation strategy to generate semantically aligned SimulST training samples and redefines SimulST as an interleaved generation task with explicit read/write tokens. To facilitate adaptive inference, we incorporate a lightweight policy head that dynamically predicts read/write actions. Additionally, we employ a multi-stage training strategy to align speech-text modalities and optimize both translation and policy behavior. Experiments on the MuST-C En$\rightarrow$De and En$\rightarrow$Es datasets demonstrate that EASiST offers superior latency-quality trade-offs compared to several strong baselines.
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline
Apr 13, 2025
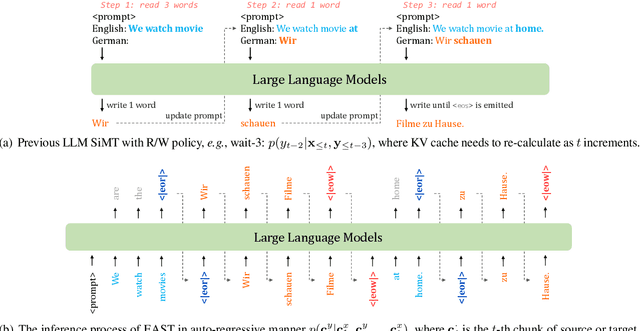
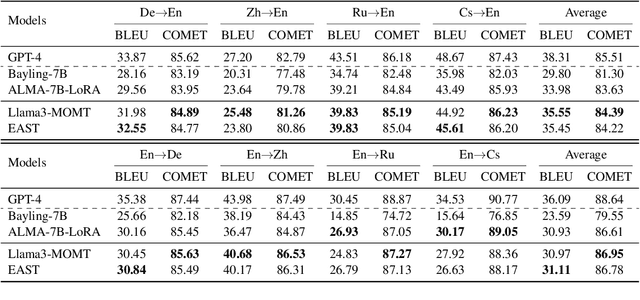
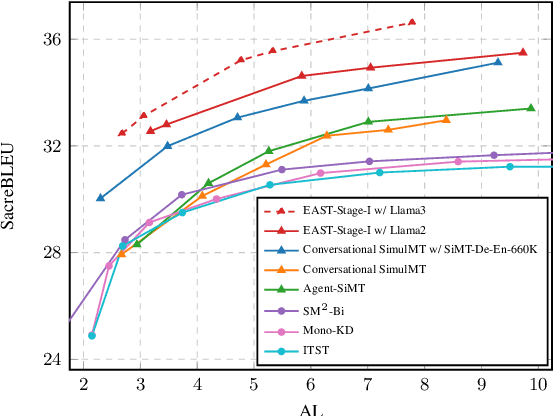
When the complete source sentence is provided, Large Language Models (LLMs) perform excellently in offline machine translation even with a simple prompt "Translate the following sentence from [src lang] into [tgt lang]:". However, in many real scenarios, the source tokens arrive in a streaming manner and simultaneous machine translation (SiMT) is required, then the efficiency and performance of decoder-only LLMs are significantly limited by their auto-regressive nature. To enable LLMs to achieve high-quality SiMT as efficiently as offline translation, we propose a novel paradigm that includes constructing supervised fine-tuning (SFT) data for SiMT, along with new training and inference strategies. To replicate the token input/output stream in SiMT, the source and target tokens are rearranged into an interleaved sequence, separated by special tokens according to varying latency requirements. This enables powerful LLMs to learn read and write operations adaptively, based on varying latency prompts, while still maintaining efficient auto-regressive decoding. Experimental results show that, even with limited SFT data, our approach achieves state-of-the-art performance across various SiMT benchmarks, and preserves the original abilities of offline translation. Moreover, our approach generalizes well to document-level SiMT setting without requiring specific fine-tuning, even beyond the offline translation model.
The Curse of CoT: On the Limitations of Chain-of-Thought in In-Context Learning
Apr 07, 2025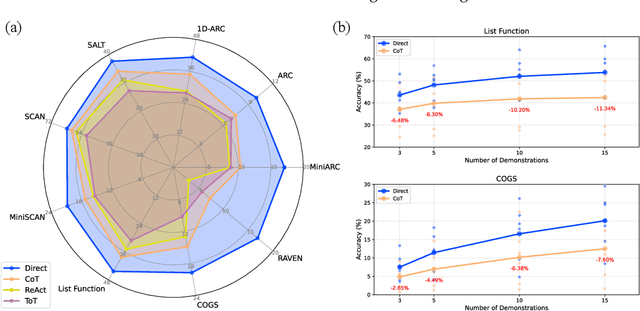
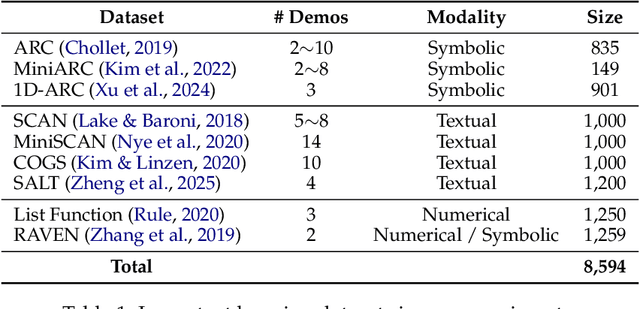
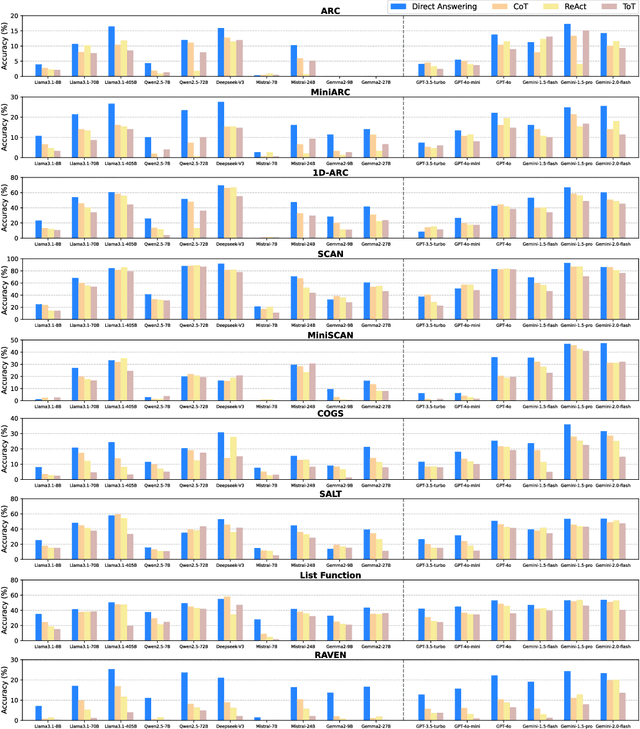
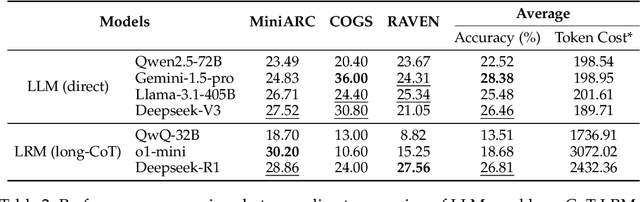
Chain-of-Thought (CoT) prompting has been widely recognized for its ability to enhance reasoning capabilities in large language models (LLMs) through the generation of explicit explanatory rationales. However, our study reveals a surprising contradiction to this prevailing perspective. Through extensive experiments involving 16 state-of-the-art LLMs and nine diverse pattern-based in-context learning (ICL) datasets, we demonstrate that CoT and its reasoning variants consistently underperform direct answering across varying model scales and benchmark complexities. To systematically investigate this unexpected phenomenon, we designed extensive experiments to validate several hypothetical explanations. Our analysis uncovers a fundamental explicit-implicit duality driving CoT's performance in pattern-based ICL: while explicit reasoning falters due to LLMs' struggles to infer underlying patterns from demonstrations, implicit reasoning-disrupted by the increased contextual distance of CoT rationales-often compensates, delivering correct answers despite flawed rationales. This duality explains CoT's relative underperformance, as noise from weak explicit inference undermines the process, even as implicit mechanisms partially salvage outcomes. Notably, even long-CoT reasoning models, which excel in abstract and symbolic reasoning, fail to fully overcome these limitations despite higher computational costs. Our findings challenge existing assumptions regarding the universal efficacy of CoT, yielding novel insights into its limitations and guiding future research toward more nuanced and effective reasoning methodologies for LLMs.
Street Gaussians without 3D Object Tracker
Dec 07, 2024



Realistic scene reconstruction in driving scenarios poses significant challenges due to fast-moving objects. Most existing methods rely on labor-intensive manual labeling of object poses to reconstruct dynamic objects in canonical space and move them based on these poses during rendering. While some approaches attempt to use 3D object trackers to replace manual annotations, the limited generalization of 3D trackers -- caused by the scarcity of large-scale 3D datasets -- results in inferior reconstructions in real-world settings. In contrast, 2D foundation models demonstrate strong generalization capabilities. To eliminate the reliance on 3D trackers and enhance robustness across diverse environments, we propose a stable object tracking module by leveraging associations from 2D deep trackers within a 3D object fusion strategy. We address inevitable tracking errors by further introducing a motion learning strategy in an implicit feature space that autonomously corrects trajectory errors and recovers missed detections. Experimental results on Waymo-NOTR datasets show we achieve state-of-the-art performance. Our code will be made publicly available.
GFreeDet: Exploiting Gaussian Splatting and Foundation Models for Model-free Unseen Object Detection in the BOP Challenge 2024
Dec 03, 2024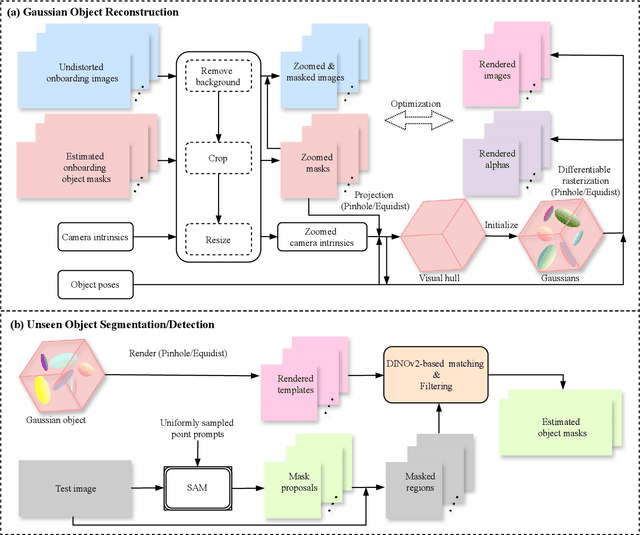

In this report, we provide the technical details of the submitted method GFreeDet, which exploits Gaussian splatting and vision Foundation models for the model-free unseen object Detection track in the BOP 2024 Challenge.
OnlySportsLM: Optimizing Sports-Domain Language Models with SOTA Performance under Billion Parameters
Aug 30, 2024



This paper explores the potential of a small, domain-specific language model trained exclusively on sports-related data. We investigate whether extensive training data with specially designed small model structures can overcome model size constraints. The study introduces the OnlySports collection, comprising OnlySportsLM, OnlySports Dataset, and OnlySports Benchmark. Our approach involves: 1) creating a massive 600 billion tokens OnlySports Dataset from FineWeb, 2) optimizing the RWKV architecture for sports-related tasks, resulting in a 196M parameters model with 20-layer, 640-dimension structure, 3) training the OnlySportsLM on part of OnlySports Dataset, and 4) testing the resultant model on OnlySports Benchmark. OnlySportsLM achieves a 37.62%/34.08% accuracy improvement over previous 135M/360M state-of-the-art models and matches the performance of larger models such as SomlLM 1.7B and Qwen 1.5B in the sports domain. Additionally, the OnlySports collection presents a comprehensive workflow for building high-quality, domain-specific language models, providing a replicable blueprint for efficient AI development across various specialized fields.
Step-level Value Preference Optimization for Mathematical Reasoning
Jun 16, 2024



Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
AlphaMath Almost Zero: process Supervision without process
May 06, 2024



Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.