 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMEM: Unified Memory Extraction and Management Framework for Generalizable Memory
Feb 11, 2026Self-evolving memory serves as the trainable parameters for Large Language Models (LLMs)-based agents, where extraction (distilling insights from experience) and management (updating the memory bank) must be tightly coordinated. Existing methods predominately optimize memory management while treating memory extraction as a static process, resulting in poor generalization, where agents accumulate instance-specific noise rather than robust memories. To address this, we propose Unified Memory Extraction and Management (UMEM), a self-evolving agent framework that jointly optimizes a Large Language Model to simultaneous extract and manage memories. To mitigate overfitting to specific instances, we introduce Semantic Neighborhood Modeling and optimize the model with a neighborhood-level marginal utility reward via GRPO. This approach ensures memory generalizability by evaluating memory utility across clusters of semantically related queries. Extensive experiments across five benchmarks demonstrate that UMEM significantly outperforms highly competitive baselines, achieving up to a 10.67% improvement in multi-turn interactive tasks. Futhermore, UMEM maintains a monotonic growth curve during continuous evolution. Codes and models will be publicly released.
DARL: Encouraging Diverse Answers for General Reasoning without Verifiers
Jan 21, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has demonstrated promising gains in enhancing the reasoning capabilities of large language models. However, its dependence on domain-specific verifiers significantly restricts its applicability to open and general domains. Recent efforts such as RLPR have extended RLVR to general domains, enabling training on broader datasets and achieving improvements over RLVR. However, a notable limitation of these methods is their tendency to overfit to reference answers, which constrains the model's ability to generate diverse outputs. This limitation is particularly pronounced in open-ended tasks such as writing, where multiple plausible answers exist. To address this, we propose DARL, a simple yet effective reinforcement learning framework that encourages the generation of diverse answers within a controlled deviation range from the reference while preserving alignment with it. Our framework is fully compatible with existing general reinforcement learning methods and can be seamlessly integrated without additional verifiers. Extensive experiments on thirteen benchmarks demonstrate consistent improvements in reasoning performance. Notably, DARL surpasses RLPR, achieving average gains of 1.3 points on six reasoning benchmarks and 9.5 points on seven general benchmarks, highlighting its effectiveness in improving both reasoning accuracy and output diversity.
How Well Do Large Reasoning Models Translate? A Comprehensive Evaluation for Multi-Domain Machine Translation
May 26, 2025Large language models (LLMs) have demonstrated strong performance in general-purpose machine translation, but their effectiveness in complex, domain-sensitive translation tasks remains underexplored. Recent advancements in Large Reasoning Models (LRMs), raise the question of whether structured reasoning can enhance translation quality across diverse domains. In this work, we compare the performance of LRMs with traditional LLMs across 15 representative domains and four translation directions. Our evaluation considers various factors, including task difficulty, input length, and terminology density. We use a combination of automatic metrics and an enhanced MQM-based evaluation hierarchy to assess translation quality. Our findings show that LRMs consistently outperform traditional LLMs in semantically complex domains, especially in long-text and high-difficulty translation scenarios. Moreover, domain-adaptive prompting strategies further improve performance by better leveraging the reasoning capabilities of LRMs. These results highlight the potential of structured reasoning in MDMT tasks and provide valuable insights for optimizing translation systems in domain-sensitive contexts.
Efficient and Adaptive Simultaneous Speech Translation with Fully Unidirectional Architecture
Apr 16, 2025



Simultaneous speech translation (SimulST) produces translations incrementally while processing partial speech input. Although large language models (LLMs) have showcased strong capabilities in offline translation tasks, applying them to SimulST poses notable challenges. Existing LLM-based SimulST approaches either incur significant computational overhead due to repeated encoding of bidirectional speech encoder, or they depend on a fixed read/write policy, limiting the efficiency and performance. In this work, we introduce Efficient and Adaptive Simultaneous Speech Translation (EASiST) with fully unidirectional architecture, including both speech encoder and LLM. EASiST includes a multi-latency data curation strategy to generate semantically aligned SimulST training samples and redefines SimulST as an interleaved generation task with explicit read/write tokens. To facilitate adaptive inference, we incorporate a lightweight policy head that dynamically predicts read/write actions. Additionally, we employ a multi-stage training strategy to align speech-text modalities and optimize both translation and policy behavior. Experiments on the MuST-C En$\rightarrow$De and En$\rightarrow$Es datasets demonstrate that EASiST offers superior latency-quality trade-offs compared to several strong baselines.
LLMs Can Achieve High-quality Simultaneous Machine Translation as Efficiently as Offline
Apr 13, 2025
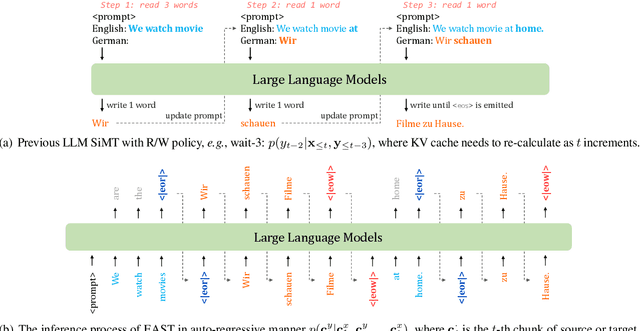
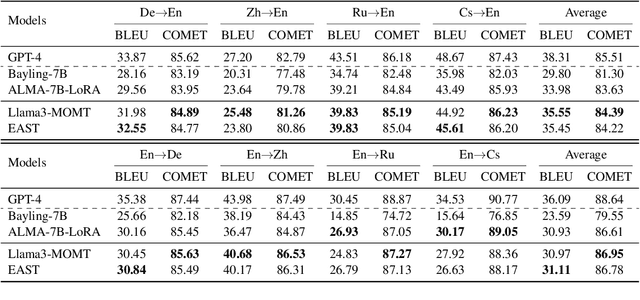
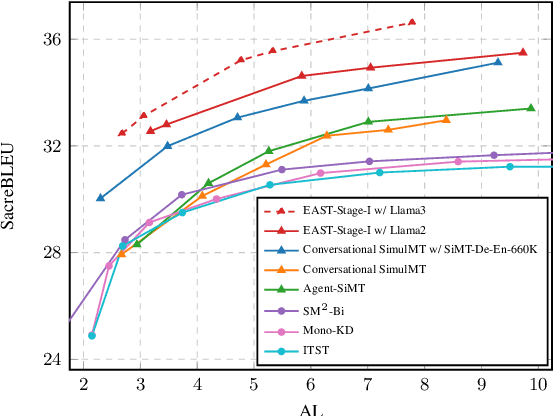
When the complete source sentence is provided, Large Language Models (LLMs) perform excellently in offline machine translation even with a simple prompt "Translate the following sentence from [src lang] into [tgt lang]:". However, in many real scenarios, the source tokens arrive in a streaming manner and simultaneous machine translation (SiMT) is required, then the efficiency and performance of decoder-only LLMs are significantly limited by their auto-regressive nature. To enable LLMs to achieve high-quality SiMT as efficiently as offline translation, we propose a novel paradigm that includes constructing supervised fine-tuning (SFT) data for SiMT, along with new training and inference strategies. To replicate the token input/output stream in SiMT, the source and target tokens are rearranged into an interleaved sequence, separated by special tokens according to varying latency requirements. This enables powerful LLMs to learn read and write operations adaptively, based on varying latency prompts, while still maintaining efficient auto-regressive decoding. Experimental results show that, even with limited SFT data, our approach achieves state-of-the-art performance across various SiMT benchmarks, and preserves the original abilities of offline translation. Moreover, our approach generalizes well to document-level SiMT setting without requiring specific fine-tuning, even beyond the offline translation model.
Representation Purification for End-to-End Speech Translation
Dec 05, 2024



Speech-to-text translation (ST) is a cross-modal task that involves converting spoken language into text in a different language. Previous research primarily focused on enhancing speech translation by facilitating knowledge transfer from machine translation, exploring various methods to bridge the gap between speech and text modalities. Despite substantial progress made, factors in speech that are not relevant to translation content, such as timbre and rhythm, often limit the efficiency of knowledge transfer. In this paper, we conceptualize speech representation as a combination of content-agnostic and content-relevant factors. We examine the impact of content-agnostic factors on translation performance through preliminary experiments and observe a significant performance deterioration when content-agnostic perturbations are introduced to speech signals. To address this issue, we propose a \textbf{S}peech \textbf{R}epresentation \textbf{P}urification with \textbf{S}upervision \textbf{E}nhancement (SRPSE) framework, which excludes the content-agnostic components within speech representations to mitigate their negative impact on ST. Experiments on MuST-C and CoVoST-2 datasets demonstrate that SRPSE significantly improves translation performance across all translation directions in three settings and achieves preeminent performance under a \textit{transcript-free} setting.
LLM$\times$MapReduce: Simplified Long-Sequence Processing using Large Language Models
Oct 12, 2024



Enlarging the context window of large language models (LLMs) has become a crucial research area, particularly for applications involving extremely long texts. In this work, we propose a novel training-free framework for processing long texts, utilizing a divide-and-conquer strategy to achieve comprehensive document understanding. The proposed LLM$\times$MapReduce framework splits the entire document into several chunks for LLMs to read and then aggregates the intermediate answers to produce the final output. The main challenge for divide-and-conquer long text processing frameworks lies in the risk of losing essential long-range information when splitting the document, which can lead the model to produce incomplete or incorrect answers based on the segmented texts. Disrupted long-range information can be classified into two categories: inter-chunk dependency and inter-chunk conflict. We design a structured information protocol to better cope with inter-chunk dependency and an in-context confidence calibration mechanism to resolve inter-chunk conflicts. Experimental results demonstrate that LLM$\times$MapReduce can outperform representative open-source and commercial long-context LLMs, and is applicable to several different models.
A Cross-Font Image Retrieval Network for Recognizing Undeciphered Oracle Bone Inscriptions
Sep 10, 2024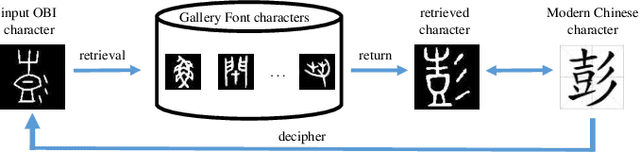
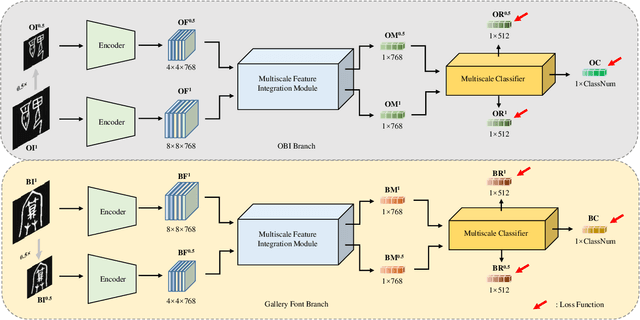
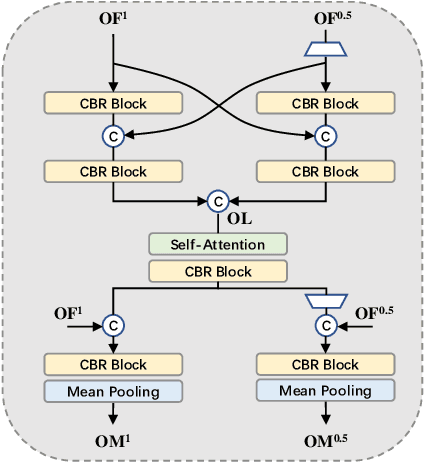

Oracle Bone Inscription (OBI) is the earliest mature writing system known in China to date, which represents a crucial stage in the development of hieroglyphs. Nevertheless, the substantial quantity of undeciphered OBI characters continues to pose a persistent challenge for scholars, while conventional methods of ancient script research are both time-consuming and labor-intensive. In this paper, we propose a cross-font image retrieval network (CFIRN) to decipher OBI characters by establishing associations between OBI characters and other script forms, simulating the interpretive behavior of paleography scholars. Concretely, our network employs a siamese framework to extract deep features from character images of various fonts, fully exploring structure clues with different resolution by designed multiscale feature integration (MFI) module and multiscale refinement classifier (MRC). Extensive experiments on three challenging cross-font image retrieval datasets demonstrate that, given undeciphered OBI characters, our CFIRN can effectively achieve accurate matches with characters from other gallery fonts.
MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization
Feb 18, 2024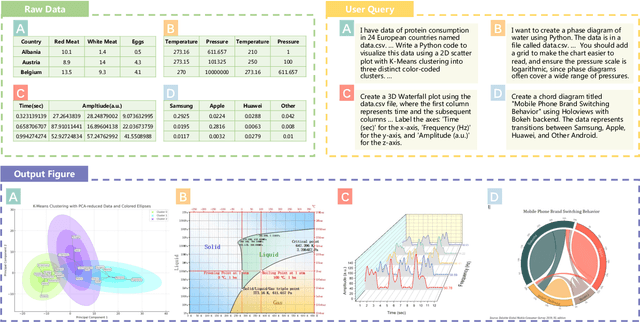
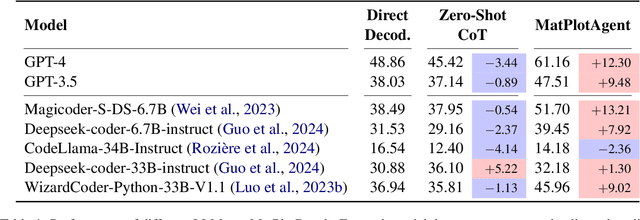
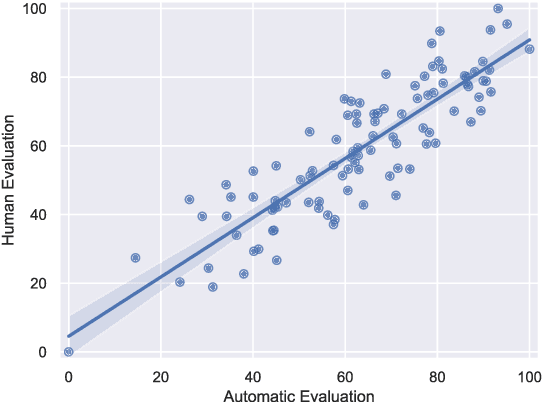
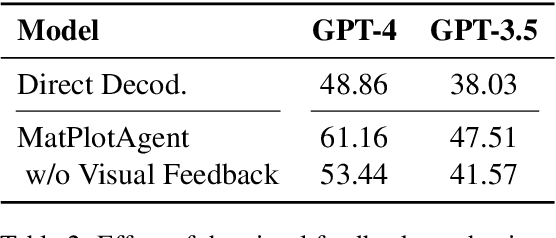
Scientific data visualization plays a crucial role in research by enabling the direct display of complex information and assisting researchers in identifying implicit patterns. Despite its importance, the use of Large Language Models (LLMs) for scientific data visualization remains rather unexplored. In this study, we introduce MatPlotAgent, an efficient model-agnostic LLM agent framework designed to automate scientific data visualization tasks. Leveraging the capabilities of both code LLMs and multi-modal LLMs, MatPlotAgent consists of three core modules: query understanding, code generation with iterative debugging, and a visual feedback mechanism for error correction. To address the lack of benchmarks in this field, we present MatPlotBench, a high-quality benchmark consisting of 100 human-verified test cases. Additionally, we introduce a scoring approach that utilizes GPT-4V for automatic evaluation. Experimental results demonstrate that MatPlotAgent can improve the performance of various LLMs, including both commercial and open-source models. Furthermore, the proposed evaluation method shows a strong correlation with human-annotated scores.
UniMem: Towards a Unified View of Long-Context Large Language Models
Feb 05, 2024



Long-context processing is a critical ability that constrains the applicability of large language models. Although there exist various methods devoted to enhancing the long-context processing ability of large language models (LLMs), they are developed in an isolated manner and lack systematic analysis and integration of their strengths, hindering further developments. In this paper, we introduce UniMem, a unified framework that reformulates existing long-context methods from the view of memory augmentation of LLMs. UniMem is characterized by four key dimensions: Memory Management, Memory Writing, Memory Reading, and Memory Injection, providing a systematic theory for understanding various long-context methods. We reformulate 16 existing methods based on UniMem and analyze four representative methods: Transformer-XL, Memorizing Transformer, RMT, and Longformer into equivalent UniMem forms to reveal their design principles and strengths. Based on these analyses, we propose UniMix, an innovative approach that integrates the strengths of these algorithms. Experimental results show that UniMix achieves superior performance in handling long contexts with significantly lower perplexity than baselines.