 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM$\times$MapReduce-V2: Entropy-Driven Convolutional Test-Time Scaling for Generating Long-Form Articles from Extremely Long Resources
Apr 08, 2025Long-form generation is crucial for a wide range of practical applications, typically categorized into short-to-long and long-to-long generation. While short-to-long generations have received considerable attention, generating long texts from extremely long resources remains relatively underexplored. The primary challenge in long-to-long generation lies in effectively integrating and analyzing relevant information from extensive inputs, which remains difficult for current large language models (LLMs). In this paper, we propose LLM$\times$MapReduce-V2, a novel test-time scaling strategy designed to enhance the ability of LLMs to process extremely long inputs. Drawing inspiration from convolutional neural networks, which iteratively integrate local features into higher-level global representations, LLM$\times$MapReduce-V2 utilizes stacked convolutional scaling layers to progressively expand the understanding of input materials. Both quantitative and qualitative experimental results demonstrate that our approach substantially enhances the ability of LLMs to process long inputs and generate coherent, informative long-form articles, outperforming several representative baselines.
LLM$\times$MapReduce: Simplified Long-Sequence Processing using Large Language Models
Oct 12, 2024



Enlarging the context window of large language models (LLMs) has become a crucial research area, particularly for applications involving extremely long texts. In this work, we propose a novel training-free framework for processing long texts, utilizing a divide-and-conquer strategy to achieve comprehensive document understanding. The proposed LLM$\times$MapReduce framework splits the entire document into several chunks for LLMs to read and then aggregates the intermediate answers to produce the final output. The main challenge for divide-and-conquer long text processing frameworks lies in the risk of losing essential long-range information when splitting the document, which can lead the model to produce incomplete or incorrect answers based on the segmented texts. Disrupted long-range information can be classified into two categories: inter-chunk dependency and inter-chunk conflict. We design a structured information protocol to better cope with inter-chunk dependency and an in-context confidence calibration mechanism to resolve inter-chunk conflicts. Experimental results demonstrate that LLM$\times$MapReduce can outperform representative open-source and commercial long-context LLMs, and is applicable to several different models.
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Apr 17, 2024



Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
SimFair: Physics-Guided Fairness-Aware Learning with Simulation Models
Feb 05, 2024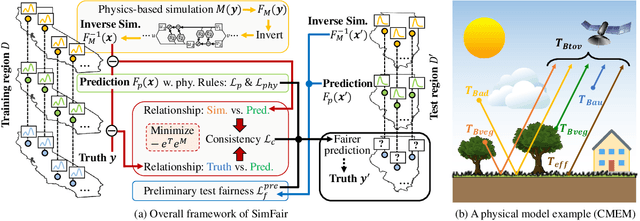
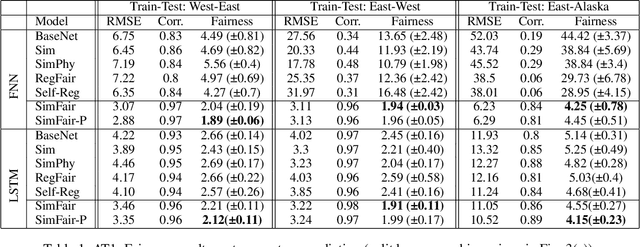
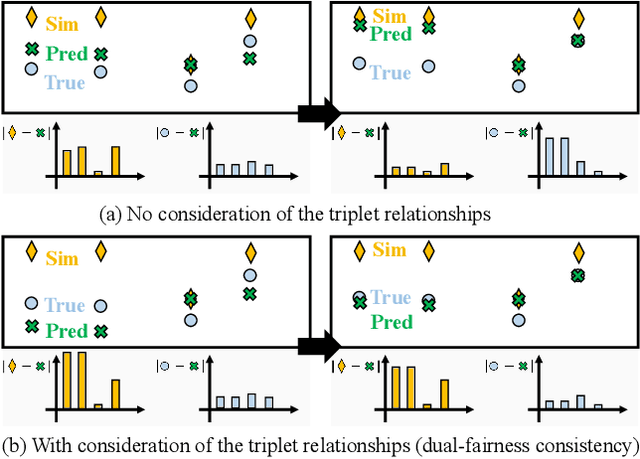
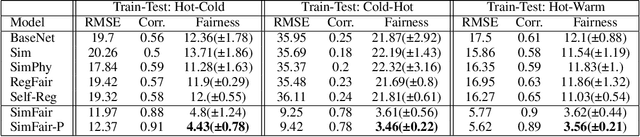
Fairness-awareness has emerged as an essential building block for the responsible use of artificial intelligence in real applications. In many cases, inequity in performance is due to the change in distribution over different regions. While techniques have been developed to improve the transferability of fairness, a solution to the problem is not always feasible with no samples from the new regions, which is a bottleneck for pure data-driven attempts. Fortunately, physics-based mechanistic models have been studied for many problems with major social impacts. We propose SimFair, a physics-guided fairness-aware learning framework, which bridges the data limitation by integrating physical-rule-based simulation and inverse modeling into the training design. Using temperature prediction as an example, we demonstrate the effectiveness of the proposed SimFair in fairness preservation.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Contrastive Learning for Mitochondria Segmentation
Sep 25, 2021



Mitochondria segmentation in electron microscopy images is essential in neuroscience. However, due to the image degradation during the imaging process, the large variety of mitochondrial structures, as well as the presence of noise, artifacts and other sub-cellular structures, mitochondria segmentation is very challenging. In this paper, we propose a novel and effective contrastive learning framework to learn a better feature representation from hard examples to improve segmentation. Specifically, we adopt a point sampling strategy to pick out representative pixels from hard examples in the training phase. Based on these sampled pixels, we introduce a pixel-wise label-based contrastive loss which consists of a similarity loss term and a consistency loss term. The similarity term can increase the similarity of pixels from the same class and the separability of pixels from different classes in feature space, while the consistency term is able to enhance the sensitivity of the 3D model to changes in image content from frame to frame. We demonstrate the effectiveness of our method on MitoEM dataset as well as FIB-SEM dataset and show better or on par with state-of-the-art results.
Building change detection based on multi-scale filtering and grid partition
Aug 22, 2019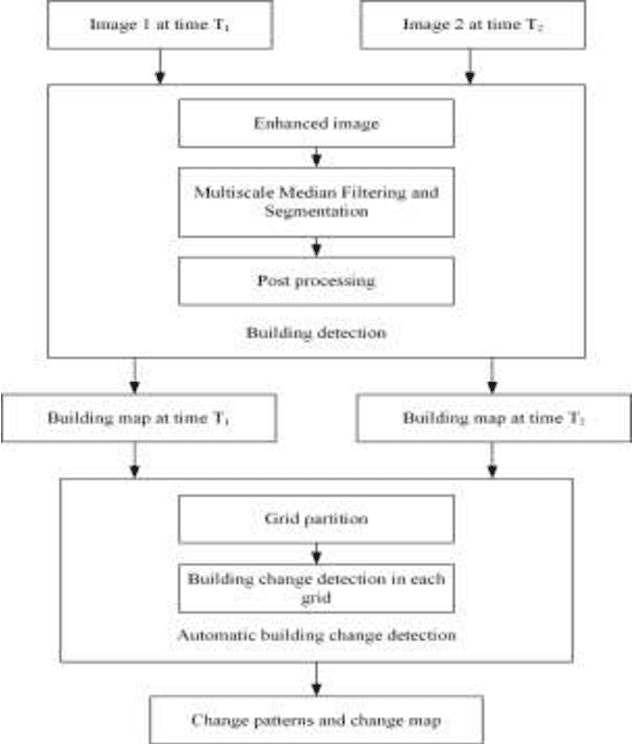


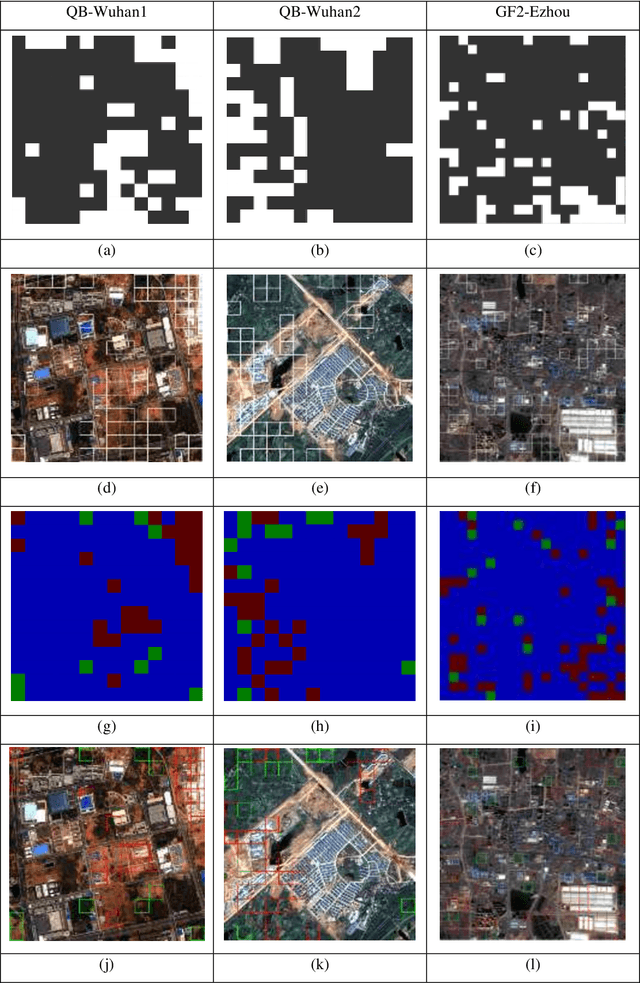
Building change detection is of great significance in high resolution remote sensing applications. Multi-index learning, one of the state-of-the-art building change detection methods, still has drawbacks like incapability to find change types directly and heavy computation consumption of MBI. In this paper, a two-stage building change detection method is proposed to address these problems. In the first stage, a multi-scale filtering building index (MFBI) is calculated to detect building areas in each temporal with fast speed and moderate accuracy. In the second stage, images and the corresponding building maps are partitioned into grids. In each grid, the ratio of building areas in time T2 and time T1 is calculated. Each grid is classified into one of the three change patterns, i.e., significantly increase, significantly decrease and approximately unchanged. Exhaustive experiments indicate that the proposed method can detect building change types directly and outperform the current multi-index learning method.
* 8 pages, 6 figures, conference paper
Multiple instance dense connected convolution neural network for aerial image scene classification
Aug 22, 2019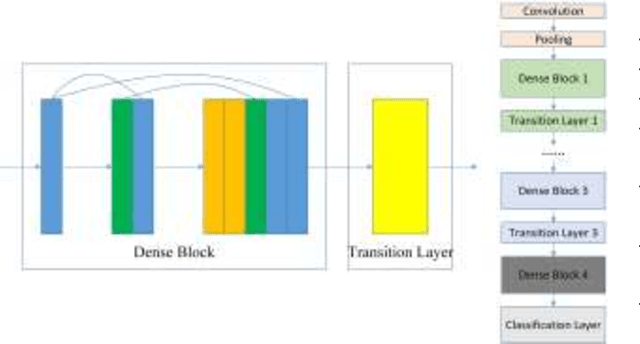
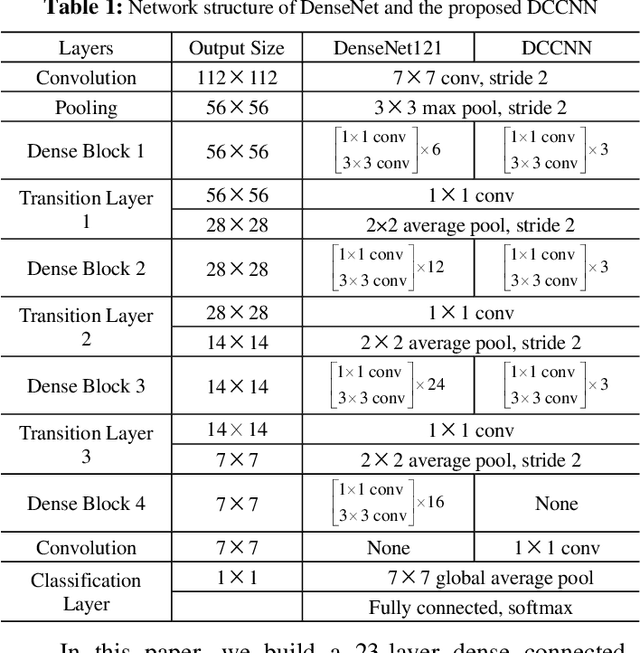
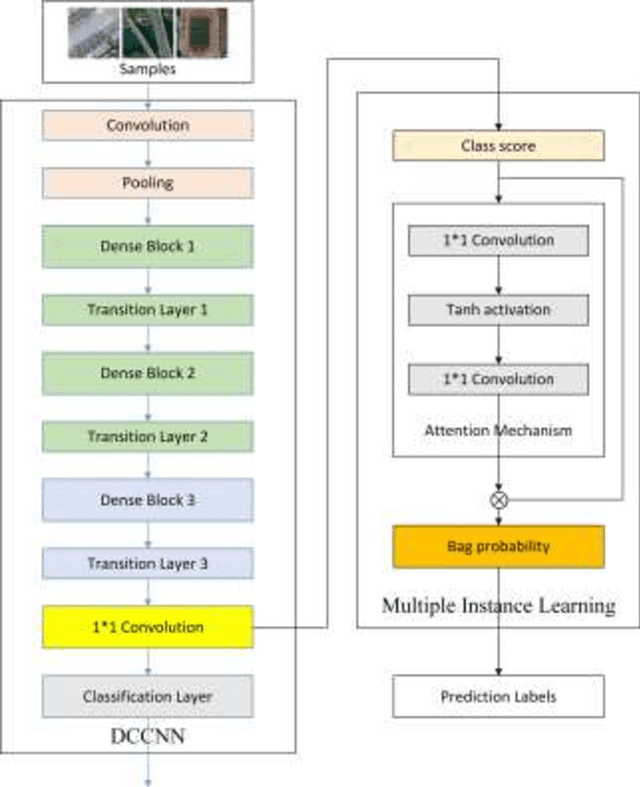
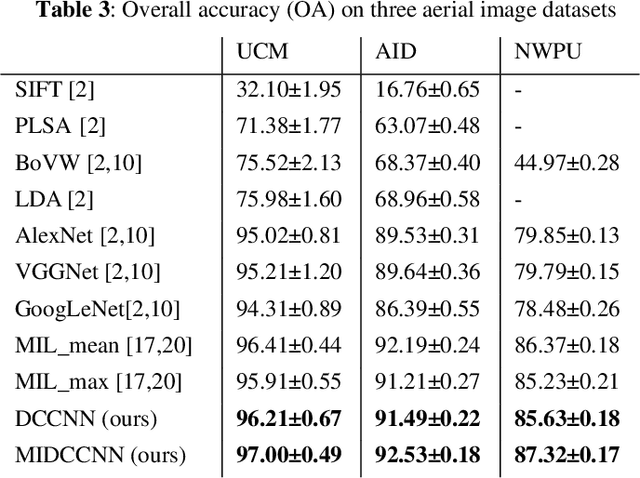
With the development of deep learning, many state-of-the-art natural image scene classification methods have demonstrated impressive performance. While the current convolution neural network tends to extract global features and global semantic information in a scene, the geo-spatial objects can be located at anywhere in an aerial image scene and their spatial arrangement tends to be more complicated. One possible solution is to preserve more local semantic information and enhance feature propagation. In this paper, an end to end multiple instance dense connected convolution neural network (MIDCCNN) is proposed for aerial image scene classification. First, a 23 layer dense connected convolution neural network (DCCNN) is built and served as a backbone to extract convolution features. It is capable of preserving middle and low level convolution features. Then, an attention based multiple instance pooling is proposed to highlight the local semantics in an aerial image scene. Finally, we minimize the loss between the bag-level predictions and the ground truth labels so that the whole framework can be trained directly. Experiments on three aerial image datasets demonstrate that our proposed methods can outperform current baselines by a large margin.