 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepwise Think-Critique: A Unified Framework for Robust and Interpretable LLM Reasoning
Dec 17, 2025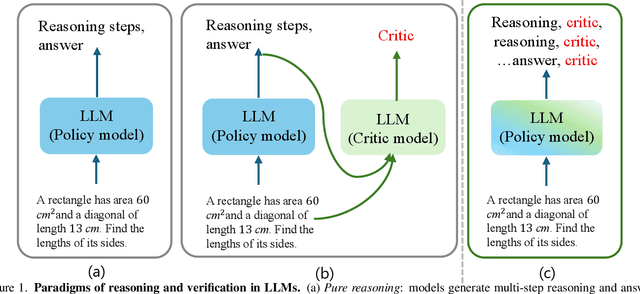


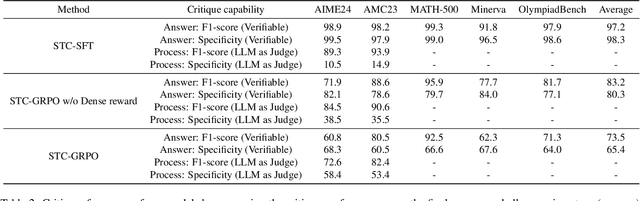
Human beings solve complex problems through critical thinking, where reasoning and evaluation are intertwined to converge toward correct solutions. However, most existing large language models (LLMs) decouple reasoning from verification: they either generate reasoning without explicit self-checking or rely on external verifiers to detect errors post hoc. The former lacks immediate feedback, while the latter increases system complexity and hinders synchronized learning. Motivated by human critical thinking, we propose Stepwise Think-Critique (STC), a unified framework that interleaves reasoning and self-critique at each step within a single model. STC is trained with a hybrid reinforcement learning objective combining reasoning rewards and critique-consistency rewards to jointly optimize reasoning quality and self-evaluation. Experiments on mathematical reasoning benchmarks show that STC demonstrates strong critic-thinking capabilities and produces more interpretable reasoning traces, representing a step toward LLMs with built-in critical thinking.
LTM3D: Bridging Token Spaces for Conditional 3D Generation with Auto-Regressive Diffusion Framework
May 30, 2025We present LTM3D, a Latent Token space Modeling framework for conditional 3D shape generation that integrates the strengths of diffusion and auto-regressive (AR) models. While diffusion-based methods effectively model continuous latent spaces and AR models excel at capturing inter-token dependencies, combining these paradigms for 3D shape generation remains a challenge. To address this, LTM3D features a Conditional Distribution Modeling backbone, leveraging a masked autoencoder and a diffusion model to enhance token dependency learning. Additionally, we introduce Prefix Learning, which aligns condition tokens with shape latent tokens during generation, improving flexibility across modalities. We further propose a Latent Token Reconstruction module with Reconstruction-Guided Sampling to reduce uncertainty and enhance structural fidelity in generated shapes. Our approach operates in token space, enabling support for multiple 3D representations, including signed distance fields, point clouds, meshes, and 3D Gaussian Splatting. Extensive experiments on image- and text-conditioned shape generation tasks demonstrate that LTM3D outperforms existing methods in prompt fidelity and structural accuracy while offering a generalizable framework for multi-modal, multi-representation 3D generation.
ResGS: Residual Densification of 3D Gaussian for Efficient Detail Recovery
Dec 10, 2024



Recently, 3D Gaussian Splatting (3D-GS) has prevailed in novel view synthesis, achieving high fidelity and efficiency. However, it often struggles to capture rich details and complete geometry. Our analysis highlights a key limitation of 3D-GS caused by the fixed threshold in densification, which balances geometry coverage against detail recovery as the threshold varies. To address this, we introduce a novel densification method, residual split, which adds a downscaled Gaussian as a residual. Our approach is capable of adaptively retrieving details and complementing missing geometry while enabling progressive refinement. To further support this method, we propose a pipeline named ResGS. Specifically, we integrate a Gaussian image pyramid for progressive supervision and implement a selection scheme that prioritizes the densification of coarse Gaussians over time. Extensive experiments demonstrate that our method achieves SOTA rendering quality. Consistent performance improvements can be achieved by applying our residual split on various 3D-GS variants, underscoring its versatility and potential for broader application in 3D-GS-based applications.
Dual Attribute-Spatial Relation Alignment for 3D Visual Grounding
Jun 13, 2024



3D visual grounding is an emerging research area dedicated to making connections between the 3D physical world and natural language, which is crucial for achieving embodied intelligence. In this paper, we propose DASANet, a Dual Attribute-Spatial relation Alignment Network that separately models and aligns object attributes and spatial relation features between language and 3D vision modalities. We decompose both the language and 3D point cloud input into two separate parts and design a dual-branch attention module to separately model the decomposed inputs while preserving global context in attribute-spatial feature fusion by cross attentions. Our DASANet achieves the highest grounding accuracy 65.1% on the Nr3D dataset, 1.3% higher than the best competitor. Besides, the visualization of the two branches proves that our method is efficient and highly interpretable.
GaussianPro: 3D Gaussian Splatting with Progressive Propagation
Feb 22, 2024



The advent of 3D Gaussian Splatting (3DGS) has recently brought about a revolution in the field of neural rendering, facilitating high-quality renderings at real-time speed. However, 3DGS heavily depends on the initialized point cloud produced by Structure-from-Motion (SfM) techniques. When tackling with large-scale scenes that unavoidably contain texture-less surfaces, the SfM techniques always fail to produce enough points in these surfaces and cannot provide good initialization for 3DGS. As a result, 3DGS suffers from difficult optimization and low-quality renderings. In this paper, inspired by classical multi-view stereo (MVS) techniques, we propose GaussianPro, a novel method that applies a progressive propagation strategy to guide the densification of the 3D Gaussians. Compared to the simple split and clone strategies used in 3DGS, our method leverages the priors of the existing reconstructed geometries of the scene and patch matching techniques to produce new Gaussians with accurate positions and orientations. Experiments on both large-scale and small-scale scenes validate the effectiveness of our method, where our method significantly surpasses 3DGS on the Waymo dataset, exhibiting an improvement of 1.15dB in terms of PSNR.
Slot-VLM: SlowFast Slots for Video-Language Modeling
Feb 20, 2024Video-Language Models (VLMs), powered by the advancements in Large Language Models (LLMs), are charting new frontiers in video understanding. A pivotal challenge is the development of an efficient method to encapsulate video content into a set of representative tokens to align with LLMs. In this work, we introduce Slot-VLM, a novel framework designed to generate semantically decomposed video tokens, in terms of object-wise and event-wise visual representations, to facilitate LLM inference. Particularly, we design a SlowFast Slots module, i.e., SF-Slots, that adaptively aggregates the dense video tokens from the CLIP vision encoder to a set of representative slots. In order to take into account both the spatial object details and the varied temporal dynamics, SF-Slots is built with a dual-branch structure. The Slow-Slots branch focuses on extracting object-centric slots from features at high spatial resolution but low (slow) frame sample rate, emphasizing detailed object information. Conversely, Fast-Slots branch is engineered to learn event-centric slots from high temporal sample rate but low spatial resolution features. These complementary slots are combined to form the vision context, serving as the input to the LLM for efficient question answering. Our experimental results demonstrate the effectiveness of our Slot-VLM, which achieves the state-of-the-art performance on video question-answering.
Learning Multimodal Volumetric Features for Large-Scale Neuron Tracing
Jan 05, 2024


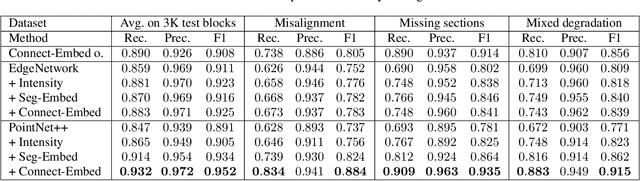
The current neuron reconstruction pipeline for electron microscopy (EM) data usually includes automatic image segmentation followed by extensive human expert proofreading. In this work, we aim to reduce human workload by predicting connectivity between over-segmented neuron pieces, taking both microscopy image and 3D morphology features into account, similar to human proofreading workflow. To this end, we first construct a dataset, named FlyTracing, that contains millions of pairwise connections of segments expanding the whole fly brain, which is three orders of magnitude larger than existing datasets for neuron segment connection. To learn sophisticated biological imaging features from the connectivity annotations, we propose a novel connectivity-aware contrastive learning method to generate dense volumetric EM image embedding. The learned embeddings can be easily incorporated with any point or voxel-based morphological representations for automatic neuron tracing. Extensive comparisons of different combination schemes of image and morphological representation in identifying split errors across the whole fly brain demonstrate the superiority of the proposed approach, especially for the locations that contain severe imaging artifacts, such as section missing and misalignment. The dataset and code are available at https://github.com/Levishery/Flywire-Neuron-Tracing.
Retrieval-based Video Language Model for Efficient Long Video Question Answering
Dec 08, 2023



The remarkable natural language understanding, reasoning, and generation capabilities of large language models (LLMs) have made them attractive for application to video question answering (Video QA) tasks, utilizing video tokens as contextual input. However, employing LLMs for long video understanding presents significant challenges and remains under-explored. The extensive number of video tokens leads to considerable computational costs for LLMs while using aggregated tokens results in loss of vision details. Moreover, the presence of abundant question-irrelevant tokens introduces noise to the video QA process. To address these issues, we introduce a simple yet effective retrieval-based video language model (R-VLM) for efficient and interpretable long video QA. Specifically, given a question (query) and a long video, our model identifies and selects the most relevant $K$ video chunks and uses their associated visual tokens to serve as context for the LLM inference. This effectively reduces the number of video tokens, eliminates noise interference, and enhances system performance. Our experimental results validate the effectiveness of our framework for comprehending long videos. Furthermore, based on the retrieved chunks, our model is interpretable that provides the justifications on where we get the answers.
UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
Nov 28, 2023Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.
DPF-Net: Combining Explicit Shape Priors in Deformable Primitive Field for Unsupervised Structural Reconstruction of 3D Objects
Aug 25, 2023



Unsupervised methods for reconstructing structures face significant challenges in capturing the geometric details with consistent structures among diverse shapes of the same category. To address this issue, we present a novel unsupervised structural reconstruction method, named DPF-Net, based on a new Deformable Primitive Field (DPF) representation, which allows for high-quality shape reconstruction using parameterized geometric primitives. We design a two-stage shape reconstruction pipeline which consists of a primitive generation module and a primitive deformation module to approximate the target shape of each part progressively. The primitive generation module estimates the explicit orientation, position, and size parameters of parameterized geometric primitives, while the primitive deformation module predicts a dense deformation field based on a parameterized primitive field to recover shape details. The strong shape prior encoded in parameterized geometric primitives enables our DPF-Net to extract high-level structures and recover fine-grained shape details consistently. The experimental results on three categories of objects in diverse shapes demonstrate the effectiveness and generalization ability of our DPF-Net on structural reconstruction and shape segmentation.