 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVTRec: Radio Interferometric Reconstruction through Visual and Textual Modality Enrichment
Jan 10, 2026Radio astronomy is an indispensable discipline for observing distant celestial objects. Measurements of wave signals from radio telescopes, called visibility, need to be transformed into images for astronomical observations. These dirty images blend information from real sources and artifacts. Therefore, astronomers usually perform reconstruction before imaging to obtain cleaner images. Existing methods consider only a single modality of sparse visibility data, resulting in images with remaining artifacts and insufficient modeling of correlation. To enhance the extraction of visibility information and emphasize output quality in the image domain, we propose VVTRec, a multimodal radio interferometric data reconstruction method with visibility-guided visual and textual modality enrichment. In our VVTRec, sparse visibility is transformed into image-form and text-form features to obtain enhancements in terms of spatial and semantic information, improving the structural integrity and accuracy of images. Also, we leverage Vision-Language Models (VLMs) to achieve additional training-free performance improvements. VVTRec enables sparse visibility, as a foreign modality unseen by VLMs, to accurately extract pre-trained knowledge as a supplement. Our experiments demonstrate that VVTRec effectively enhances imaging results by exploiting multimodal information without introducing excessive computational overhead.
Graph-Weighted Contrastive Learning for Semi-Supervised Hyperspectral Image Classification
Mar 19, 2025Most existing graph-based semi-supervised hyperspectral image classification methods rely on superpixel partitioning techniques. However, they suffer from misclassification of certain pixels due to inaccuracies in superpixel boundaries, \ie, the initial inaccuracies in superpixel partitioning limit overall classification performance. In this paper, we propose a novel graph-weighted contrastive learning approach that avoids the use of superpixel partitioning and directly employs neural networks to learn hyperspectral image representation. Furthermore, while many approaches require all graph nodes to be available during training, our approach supports mini-batch training by processing only a subset of nodes at a time, reducing computational complexity and improving generalization to unseen nodes. Experimental results on three widely-used datasets demonstrate the effectiveness of the proposed approach compared to baselines relying on superpixel partitioning.
A Universal Framework for Compressing Embeddings in CTR Prediction
Feb 21, 2025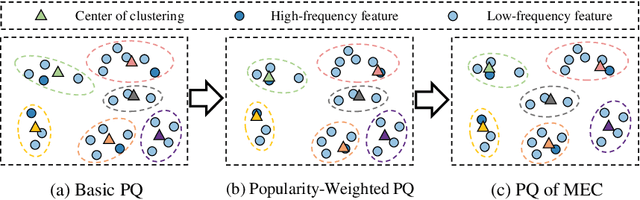
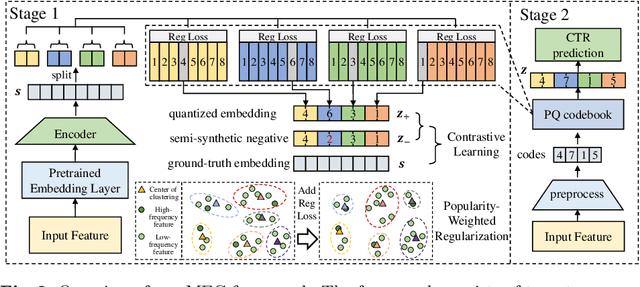
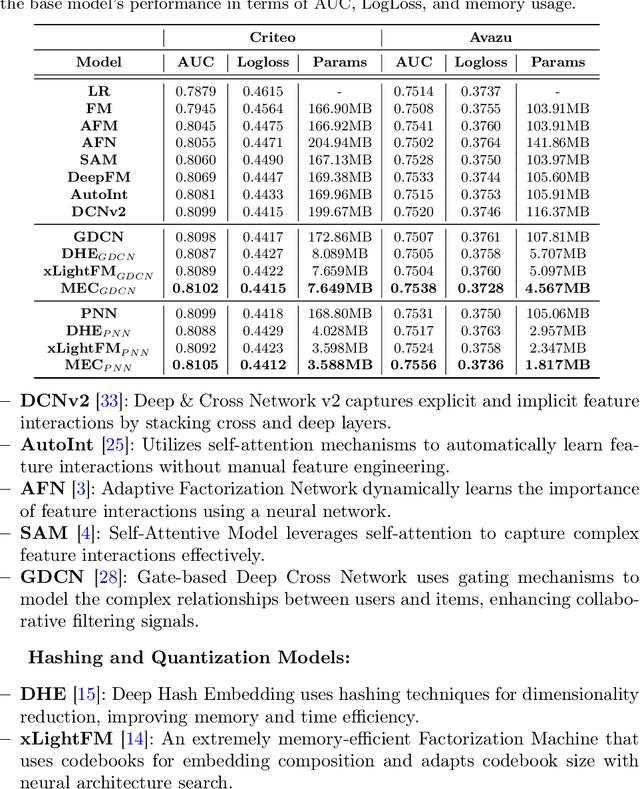
Accurate click-through rate (CTR) prediction is vital for online advertising and recommendation systems. Recent deep learning advancements have improved the ability to capture feature interactions and understand user interests. However, optimizing the embedding layer often remains overlooked. Embedding tables, which represent categorical and sequential features, can become excessively large, surpassing GPU memory limits and necessitating storage in CPU memory. This results in high memory consumption and increased latency due to frequent GPU-CPU data transfers. To tackle these challenges, we introduce a Model-agnostic Embedding Compression (MEC) framework that compresses embedding tables by quantizing pre-trained embeddings, without sacrificing recommendation quality. Our approach consists of two stages: first, we apply popularity-weighted regularization to balance code distribution between high- and low-frequency features. Then, we integrate a contrastive learning mechanism to ensure a uniform distribution of quantized codes, enhancing the distinctiveness of embeddings. Experiments on three datasets reveal that our method reduces memory usage by over 50x while maintaining or improving recommendation performance compared to existing models. The implementation code is accessible in our project repository https://github.com/USTC-StarTeam/MEC.
ResGS: Residual Densification of 3D Gaussian for Efficient Detail Recovery
Dec 10, 2024



Recently, 3D Gaussian Splatting (3D-GS) has prevailed in novel view synthesis, achieving high fidelity and efficiency. However, it often struggles to capture rich details and complete geometry. Our analysis highlights a key limitation of 3D-GS caused by the fixed threshold in densification, which balances geometry coverage against detail recovery as the threshold varies. To address this, we introduce a novel densification method, residual split, which adds a downscaled Gaussian as a residual. Our approach is capable of adaptively retrieving details and complementing missing geometry while enabling progressive refinement. To further support this method, we propose a pipeline named ResGS. Specifically, we integrate a Gaussian image pyramid for progressive supervision and implement a selection scheme that prioritizes the densification of coarse Gaussians over time. Extensive experiments demonstrate that our method achieves SOTA rendering quality. Consistent performance improvements can be achieved by applying our residual split on various 3D-GS variants, underscoring its versatility and potential for broader application in 3D-GS-based applications.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
EfficientEQA: An Efficient Approach for Open Vocabulary Embodied Question Answering
Oct 26, 2024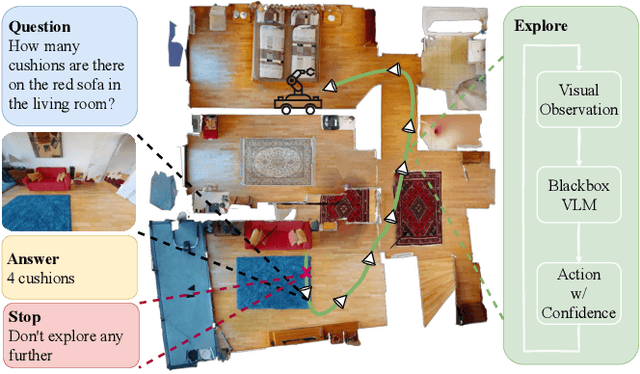
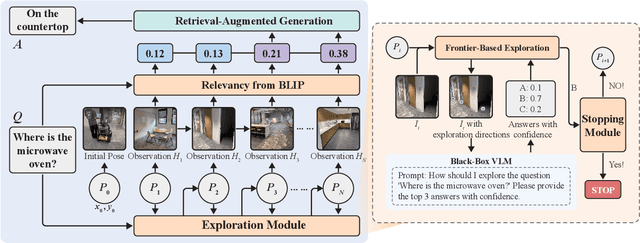
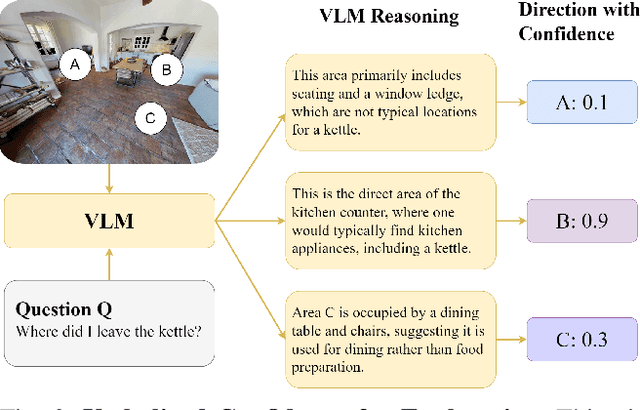
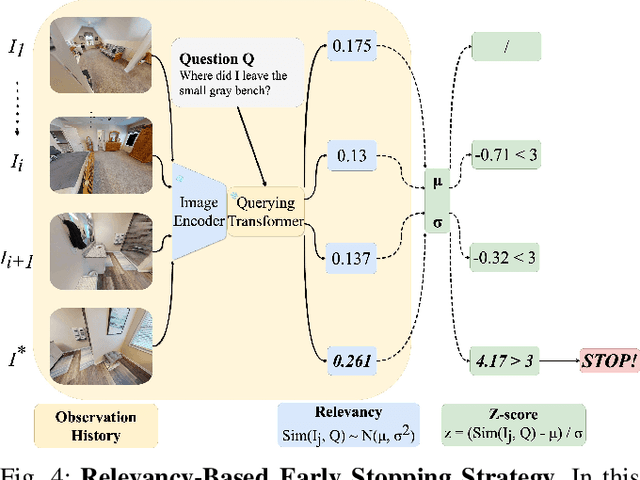
Embodied Question Answering (EQA) is an essential yet challenging task for robotic home assistants. Recent studies have shown that large vision-language models (VLMs) can be effectively utilized for EQA, but existing works either focus on video-based question answering without embodied exploration or rely on closed-form choice sets. In real-world scenarios, a robotic agent must efficiently explore and accurately answer questions in open-vocabulary settings. To address these challenges, we propose a novel framework called EfficientEQA for open-vocabulary EQA, which enables efficient exploration and accurate answering. In EfficientEQA, the robot actively explores unknown environments using Semantic-Value-Weighted Frontier Exploration, a strategy that prioritizes exploration based on semantic importance provided by calibrated confidence from black-box VLMs to quickly gather relevant information. To generate accurate answers, we employ Retrieval-Augmented Generation (RAG), which utilizes BLIP to retrieve useful images from accumulated observations and VLM reasoning to produce responses without relying on predefined answer choices. Additionally, we detect observations that are highly relevant to the question as outliers, allowing the robot to determine when it has sufficient information to stop exploring and provide an answer. Experimental results demonstrate the effectiveness of our approach, showing an improvement in answering accuracy by over 15% and efficiency, measured in running steps, by over 20% compared to state-of-the-art methods.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024

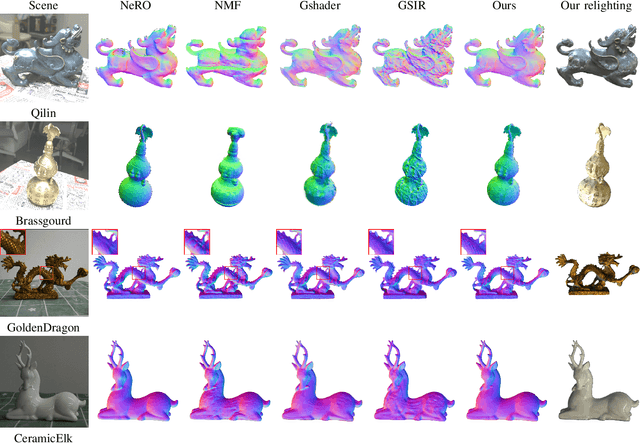
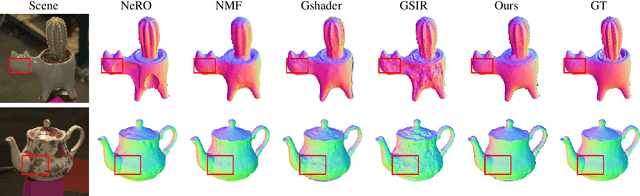
Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
Denoising Pre-Training and Customized Prompt Learning for Efficient Multi-Behavior Sequential Recommendation
Aug 21, 2024

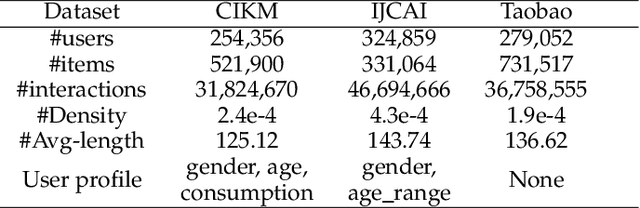
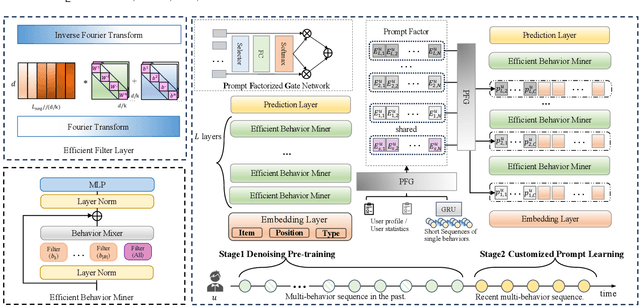
In the realm of recommendation systems, users exhibit a diverse array of behaviors when interacting with items. This phenomenon has spurred research into learning the implicit semantic relationships between these behaviors to enhance recommendation performance. However, these methods often entail high computational complexity. To address concerns regarding efficiency, pre-training presents a viable solution. Its objective is to extract knowledge from extensive pre-training data and fine-tune the model for downstream tasks. Nevertheless, previous pre-training methods have primarily focused on single-behavior data, while multi-behavior data contains significant noise. Additionally, the fully fine-tuning strategy adopted by these methods still imposes a considerable computational burden. In response to this challenge, we propose DPCPL, the first pre-training and prompt-tuning paradigm tailored for Multi-Behavior Sequential Recommendation. Specifically, in the pre-training stage, we commence by proposing a novel Efficient Behavior Miner (EBM) to filter out the noise at multiple time scales, thereby facilitating the comprehension of the contextual semantics of multi-behavior sequences. Subsequently, we propose to tune the pre-trained model in a highly efficient manner with the proposed Customized Prompt Learning (CPL) module, which generates personalized, progressive, and diverse prompts to fully exploit the potential of the pre-trained model effectively. Extensive experiments on three real-world datasets have unequivocally demonstrated that DPCPL not only exhibits high efficiency and effectiveness, requiring minimal parameter adjustments but also surpasses the state-of-the-art performance across a diverse range of downstream tasks.
GaussianRoom: Improving 3D Gaussian Splatting with SDF Guidance and Monocular Cues for Indoor Scene Reconstruction
May 30, 2024



Recently, 3D Gaussian Splatting(3DGS) has revolutionized neural rendering with its high-quality rendering and real-time speed. However, when it comes to indoor scenes with a significant number of textureless areas, 3DGS yields incomplete and noisy reconstruction results due to the poor initialization of the point cloud and under-constrained optimization. Inspired by the continuity of signed distance field (SDF), which naturally has advantages in modeling surfaces, we present a unified optimizing framework integrating neural SDF with 3DGS. This framework incorporates a learnable neural SDF field to guide the densification and pruning of Gaussians, enabling Gaussians to accurately model scenes even with poor initialized point clouds. At the same time, the geometry represented by Gaussians improves the efficiency of the SDF field by piloting its point sampling. Additionally, we regularize the optimization with normal and edge priors to eliminate geometry ambiguity in textureless areas and improve the details. Extensive experiments in ScanNet and ScanNet++ show that our method achieves state-of-the-art performance in both surface reconstruction and novel view synthesis.
DC-Gaussian: Improving 3D Gaussian Splatting for Reflective Dash Cam Videos
May 29, 2024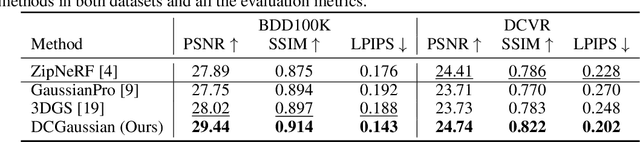

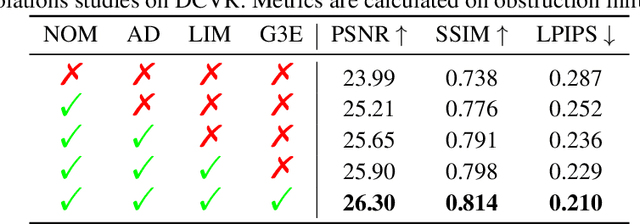
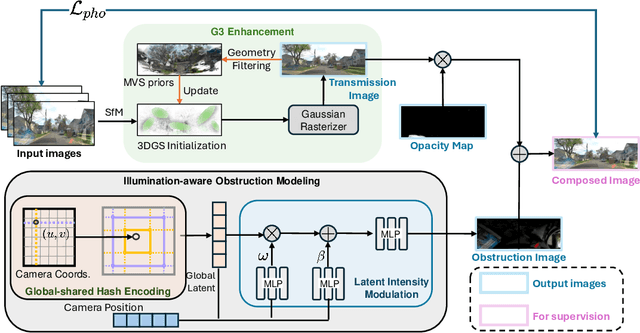
We present DC-Gaussian, a new method for generating novel views from in-vehicle dash cam videos. While neural rendering techniques have made significant strides in driving scenarios, existing methods are primarily designed for videos collected by autonomous vehicles. However, these videos are limited in both quantity and diversity compared to dash cam videos, which are more widely used across various types of vehicles and capture a broader range of scenarios. Dash cam videos often suffer from severe obstructions such as reflections and occlusions on the windshields, which significantly impede the application of neural rendering techniques. To address this challenge, we develop DC-Gaussian based on the recent real-time neural rendering technique 3D Gaussian Splatting (3DGS). Our approach includes an adaptive image decomposition module to model reflections and occlusions in a unified manner. Additionally, we introduce illumination-aware obstruction modeling to manage reflections and occlusions under varying lighting conditions. Lastly, we employ a geometry-guided Gaussian enhancement strategy to improve rendering details by incorporating additional geometry priors. Experiments on self-captured and public dash cam videos show that our method not only achieves state-of-the-art performance in novel view synthesis, but also accurately reconstructing captured scenes getting rid of obstructions.