 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
MDD: A Dataset for Text-and-Music Conditioned Duet Dance Generation
Aug 23, 2025We introduce Multimodal DuetDance (MDD), a diverse multimodal benchmark dataset designed for text-controlled and music-conditioned 3D duet dance motion generation. Our dataset comprises 620 minutes of high-quality motion capture data performed by professional dancers, synchronized with music, and detailed with over 10K fine-grained natural language descriptions. The annotations capture a rich movement vocabulary, detailing spatial relationships, body movements, and rhythm, making MDD the first dataset to seamlessly integrate human motions, music, and text for duet dance generation. We introduce two novel tasks supported by our dataset: (1) Text-to-Duet, where given music and a textual prompt, both the leader and follower dance motion are generated (2) Text-to-Dance Accompaniment, where given music, textual prompt, and the leader's motion, the follower's motion is generated in a cohesive, text-aligned manner. We include baseline evaluations on both tasks to support future research.
EfficientEQA: An Efficient Approach for Open Vocabulary Embodied Question Answering
Oct 26, 2024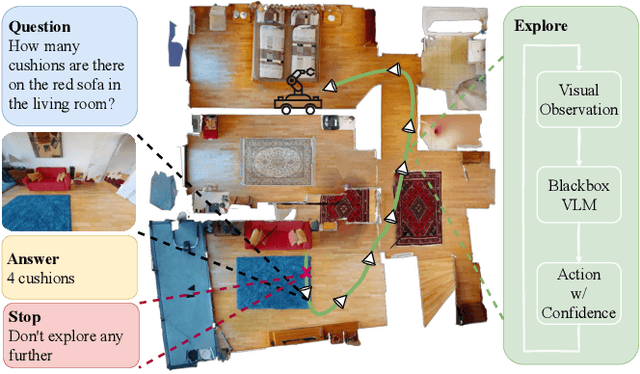
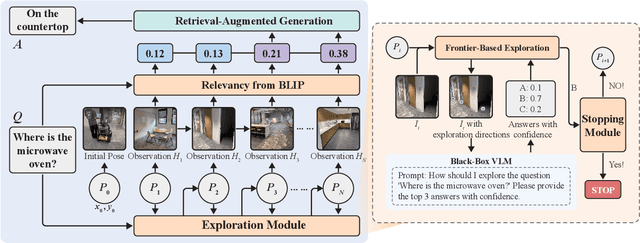
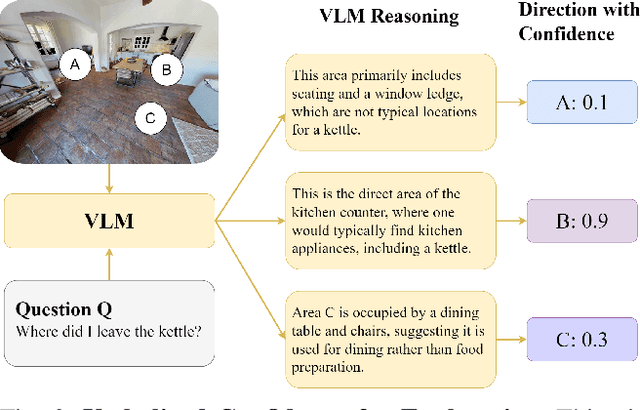
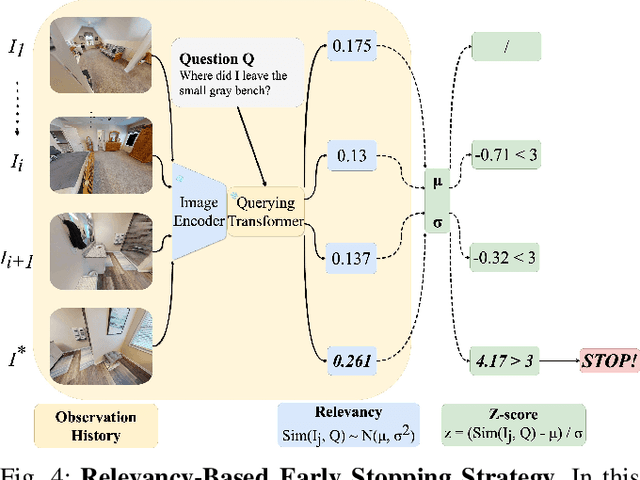
Embodied Question Answering (EQA) is an essential yet challenging task for robotic home assistants. Recent studies have shown that large vision-language models (VLMs) can be effectively utilized for EQA, but existing works either focus on video-based question answering without embodied exploration or rely on closed-form choice sets. In real-world scenarios, a robotic agent must efficiently explore and accurately answer questions in open-vocabulary settings. To address these challenges, we propose a novel framework called EfficientEQA for open-vocabulary EQA, which enables efficient exploration and accurate answering. In EfficientEQA, the robot actively explores unknown environments using Semantic-Value-Weighted Frontier Exploration, a strategy that prioritizes exploration based on semantic importance provided by calibrated confidence from black-box VLMs to quickly gather relevant information. To generate accurate answers, we employ Retrieval-Augmented Generation (RAG), which utilizes BLIP to retrieve useful images from accumulated observations and VLM reasoning to produce responses without relying on predefined answer choices. Additionally, we detect observations that are highly relevant to the question as outliers, allowing the robot to determine when it has sufficient information to stop exploring and provide an answer. Experimental results demonstrate the effectiveness of our approach, showing an improvement in answering accuracy by over 15% and efficiency, measured in running steps, by over 20% compared to state-of-the-art methods.
Practical Region-level Attack against Segment Anything Models
Apr 12, 2024



Segment Anything Models (SAM) have made significant advancements in image segmentation, allowing users to segment target portions of an image with a single click (i.e., user prompt). Given its broad applications, the robustness of SAM against adversarial attacks is a critical concern. While recent works have explored adversarial attacks against a pre-defined prompt/click, their threat model is not yet realistic: (1) they often assume the user-click position is known to the attacker (point-based attack), and (2) they often operate under a white-box setting with limited transferability. In this paper, we propose a more practical region-level attack where attackers do not need to know the precise user prompt. The attack remains effective as the user clicks on any point on the target object in the image, hiding the object from SAM. Also, by adapting a spectrum transformation method, we make the attack more transferable under a black-box setting. Both control experiments and testing against real-world SAM services confirm its effectiveness.
InterDiff: Generating 3D Human-Object Interactions with Physics-Informed Diffusion
Aug 31, 2023This paper addresses a novel task of anticipating 3D human-object interactions (HOIs). Most existing research on HOI synthesis lacks comprehensive whole-body interactions with dynamic objects, e.g., often limited to manipulating small or static objects. Our task is significantly more challenging, as it requires modeling dynamic objects with various shapes, capturing whole-body motion, and ensuring physically valid interactions. To this end, we propose InterDiff, a framework comprising two key steps: (i) interaction diffusion, where we leverage a diffusion model to encode the distribution of future human-object interactions; (ii) interaction correction, where we introduce a physics-informed predictor to correct denoised HOIs in a diffusion step. Our key insight is to inject prior knowledge that the interactions under reference with respect to contact points follow a simple pattern and are easily predictable. Experiments on multiple human-object interaction datasets demonstrate the effectiveness of our method for this task, capable of producing realistic, vivid, and remarkably long-term 3D HOI predictions.