 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped Exploration
Sep 11, 2025Hand-object motion-capture (MoCap) repositories offer large-scale, contact-rich demonstrations and hold promise for scaling dexterous robotic manipulation. Yet demonstration inaccuracies and embodiment gaps between human and robot hands limit the straightforward use of these data. Existing methods adopt a three-stage workflow, including retargeting, tracking, and residual correction, which often leaves demonstrations underused and compound errors across stages. We introduce Dexplore, a unified single-loop optimization that jointly performs retargeting and tracking to learn robot control policies directly from MoCap at scale. Rather than treating demonstrations as ground truth, we use them as soft guidance. From raw trajectories, we derive adaptive spatial scopes, and train with reinforcement learning to keep the policy in-scope while minimizing control effort and accomplishing the task. This unified formulation preserves demonstration intent, enables robot-specific strategies to emerge, improves robustness to noise, and scales to large demonstration corpora. We distill the scaled tracking policy into a vision-based, skill-conditioned generative controller that encodes diverse manipulation skills in a rich latent representation, supporting generalization across objects and real-world deployment. Taken together, these contributions position Dexplore as a principled bridge that transforms imperfect demonstrations into effective training signals for dexterous manipulation.
InterAct: Advancing Large-Scale Versatile 3D Human-Object Interaction Generation
Sep 11, 2025While large-scale human motion capture datasets have advanced human motion generation, modeling and generating dynamic 3D human-object interactions (HOIs) remain challenging due to dataset limitations. Existing datasets often lack extensive, high-quality motion and annotation and exhibit artifacts such as contact penetration, floating, and incorrect hand motions. To address these issues, we introduce InterAct, a large-scale 3D HOI benchmark featuring dataset and methodological advancements. First, we consolidate and standardize 21.81 hours of HOI data from diverse sources, enriching it with detailed textual annotations. Second, we propose a unified optimization framework to enhance data quality by reducing artifacts and correcting hand motions. Leveraging the principle of contact invariance, we maintain human-object relationships while introducing motion variations, expanding the dataset to 30.70 hours. Third, we define six benchmarking tasks and develop a unified HOI generative modeling perspective, achieving state-of-the-art performance. Extensive experiments validate the utility of our dataset as a foundational resource for advancing 3D human-object interaction generation. To support continued research in this area, the dataset is publicly available at https://github.com/wzyabcas/InterAct, and will be actively maintained.
Refer to Anything with Vision-Language Prompts
Jun 05, 2025Recent image segmentation models have advanced to segment images into high-quality masks for visual entities, and yet they cannot provide comprehensive semantic understanding for complex queries based on both language and vision. This limitation reduces their effectiveness in applications that require user-friendly interactions driven by vision-language prompts. To bridge this gap, we introduce a novel task of omnimodal referring expression segmentation (ORES). In this task, a model produces a group of masks based on arbitrary prompts specified by text only or text plus reference visual entities. To address this new challenge, we propose a novel framework to "Refer to Any Segmentation Mask Group" (RAS), which augments segmentation models with complex multimodal interactions and comprehension via a mask-centric large multimodal model. For training and benchmarking ORES models, we create datasets MaskGroups-2M and MaskGroups-HQ to include diverse mask groups specified by text and reference entities. Through extensive evaluation, we demonstrate superior performance of RAS on our new ORES task, as well as classic referring expression segmentation (RES) and generalized referring expression segmentation (GRES) tasks. Project page: https://Ref2Any.github.io.
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought
May 29, 2025Recent advances in multimodal large language models (MLLMs) have demonstrated remarkable capabilities in vision-language tasks, yet they often struggle with vision-centric scenarios where precise visual focus is needed for accurate reasoning. In this paper, we introduce Argus to address these limitations with a new visual attention grounding mechanism. Our approach employs object-centric grounding as visual chain-of-thought signals, enabling more effective goal-conditioned visual attention during multimodal reasoning tasks. Evaluations on diverse benchmarks demonstrate that Argus excels in both multimodal reasoning tasks and referring object grounding tasks. Extensive analysis further validates various design choices of Argus, and reveals the effectiveness of explicit language-guided visual region-of-interest engagement in MLLMs, highlighting the importance of advancing multimodal intelligence from a visual-centric perspective. Project page: https://yunzeman.github.io/argus/
InterMimic: Towards Universal Whole-Body Control for Physics-Based Human-Object Interactions
Feb 27, 2025Achieving realistic simulations of humans interacting with a wide range of objects has long been a fundamental goal. Extending physics-based motion imitation to complex human-object interactions (HOIs) is challenging due to intricate human-object coupling, variability in object geometries, and artifacts in motion capture data, such as inaccurate contacts and limited hand detail. We introduce InterMimic, a framework that enables a single policy to robustly learn from hours of imperfect MoCap data covering diverse full-body interactions with dynamic and varied objects. Our key insight is to employ a curriculum strategy -- perfect first, then scale up. We first train subject-specific teacher policies to mimic, retarget, and refine motion capture data. Next, we distill these teachers into a student policy, with the teachers acting as online experts providing direct supervision, as well as high-quality references. Notably, we incorporate RL fine-tuning on the student policy to surpass mere demonstration replication and achieve higher-quality solutions. Our experiments demonstrate that InterMimic produces realistic and diverse interactions across multiple HOI datasets. The learned policy generalizes in a zero-shot manner and seamlessly integrates with kinematic generators, elevating the framework from mere imitation to generative modeling of complex human-object interactions.
Emerging Pixel Grounding in Large Multimodal Models Without Grounding Supervision
Oct 10, 2024



Current large multimodal models (LMMs) face challenges in grounding, which requires the model to relate language components to visual entities. Contrary to the common practice that fine-tunes LMMs with additional grounding supervision, we find that the grounding ability can in fact emerge in LMMs trained without explicit grounding supervision. To reveal this emerging grounding, we introduce an "attend-and-segment" method which leverages attention maps from standard LMMs to perform pixel-level segmentation. Furthermore, to enhance the grounding ability, we propose DIFFLMM, an LMM utilizing a diffusion-based visual encoder, as opposed to the standard CLIP visual encoder, and trained with the same weak supervision. Without being constrained by the biases and limited scale of grounding-specific supervision data, our approach is more generalizable and scalable. We achieve competitive performance on both grounding-specific and general visual question answering benchmarks, compared with grounding LMMs and generalist LMMs, respectively. Notably, we achieve a 44.2 grounding mask recall on grounded conversation generation without any grounding supervision, outperforming the extensively supervised model GLaMM. Project page: https://groundLMM.github.io.
Lexicon3D: Probing Visual Foundation Models for Complex 3D Scene Understanding
Sep 05, 2024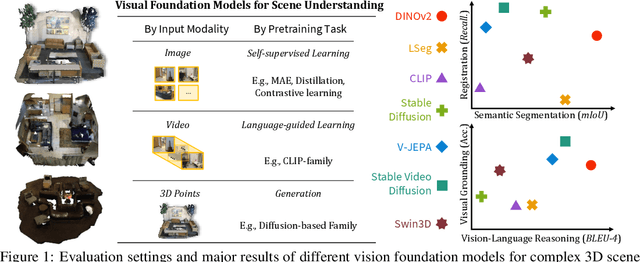
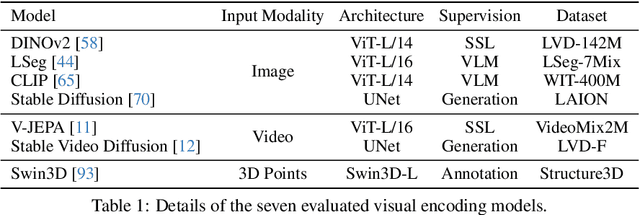
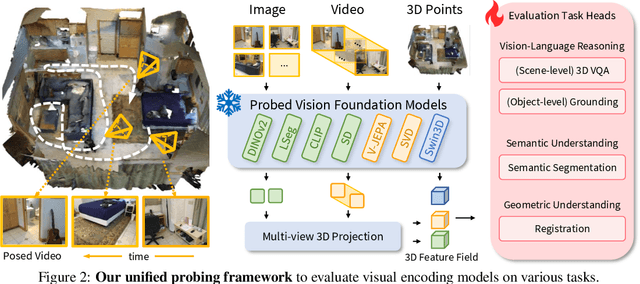
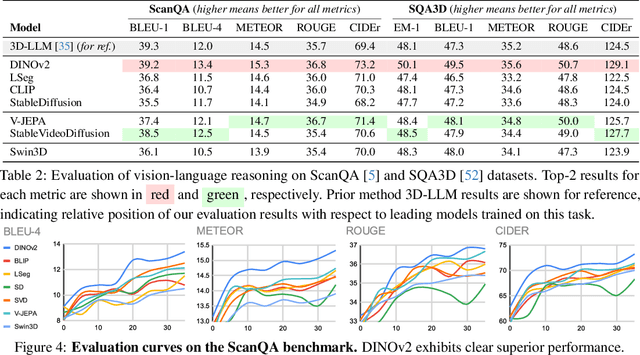
Complex 3D scene understanding has gained increasing attention, with scene encoding strategies playing a crucial role in this success. However, the optimal scene encoding strategies for various scenarios remain unclear, particularly compared to their image-based counterparts. To address this issue, we present a comprehensive study that probes various visual encoding models for 3D scene understanding, identifying the strengths and limitations of each model across different scenarios. Our evaluation spans seven vision foundation encoders, including image-based, video-based, and 3D foundation models. We evaluate these models in four tasks: Vision-Language Scene Reasoning, Visual Grounding, Segmentation, and Registration, each focusing on different aspects of scene understanding. Our evaluations yield key findings: DINOv2 demonstrates superior performance, video models excel in object-level tasks, diffusion models benefit geometric tasks, and language-pretrained models show unexpected limitations in language-related tasks. These insights challenge some conventional understandings, provide novel perspectives on leveraging visual foundation models, and highlight the need for more flexible encoder selection in future vision-language and scene-understanding tasks.
Floating No More: Object-Ground Reconstruction from a Single Image
Jul 26, 2024Recent advancements in 3D object reconstruction from single images have primarily focused on improving the accuracy of object shapes. Yet, these techniques often fail to accurately capture the inter-relation between the object, ground, and camera. As a result, the reconstructed objects often appear floating or tilted when placed on flat surfaces. This limitation significantly affects 3D-aware image editing applications like shadow rendering and object pose manipulation. To address this issue, we introduce ORG (Object Reconstruction with Ground), a novel task aimed at reconstructing 3D object geometry in conjunction with the ground surface. Our method uses two compact pixel-level representations to depict the relationship between camera, object, and ground. Experiments show that the proposed ORG model can effectively reconstruct object-ground geometry on unseen data, significantly enhancing the quality of shadow generation and pose manipulation compared to conventional single-image 3D reconstruction techniques.
Situational Awareness Matters in 3D Vision Language Reasoning
Jun 11, 2024



Being able to carry out complicated vision language reasoning tasks in 3D space represents a significant milestone in developing household robots and human-centered embodied AI. In this work, we demonstrate that a critical and distinct challenge in 3D vision language reasoning is situational awareness, which incorporates two key components: (1) The autonomous agent grounds its self-location based on a language prompt. (2) The agent answers open-ended questions from the perspective of its calculated position. To address this challenge, we introduce SIG3D, an end-to-end Situation-Grounded model for 3D vision language reasoning. We tokenize the 3D scene into sparse voxel representation and propose a language-grounded situation estimator, followed by a situated question answering module. Experiments on the SQA3D and ScanQA datasets show that SIG3D outperforms state-of-the-art models in situation estimation and question answering by a large margin (e.g., an enhancement of over 30% on situation estimation accuracy). Subsequent analysis corroborates our architectural design choices, explores the distinct functions of visual and textual tokens, and highlights the importance of situational awareness in the domain of 3D question answering.