 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSayNext-Bench: Why Do LLMs Struggle with Next-Utterance Prediction?
Jan 30, 2026We explore the use of large language models (LLMs) for next-utterance prediction in human dialogue. Despite recent advances in LLMs demonstrating their ability to engage in natural conversations with users, we show that even leading models surprisingly struggle to predict a human speaker's next utterance. Instead, humans can readily anticipate forthcoming utterances based on multimodal cues, such as gestures, gaze, and emotional tone, from the context. To systematically examine whether LLMs can reproduce this ability, we propose SayNext-Bench, a benchmark that evaluates LLMs and Multimodal LLMs (MLLMs) on anticipating context-conditioned responses from multimodal cues spanning a variety of real-world scenarios. To support this benchmark, we build SayNext-PC, a novel large-scale dataset containing dialogues with rich multimodal cues. Building on this, we further develop a dual-route prediction MLLM, SayNext-Chat, that incorporates cognitively inspired design to emulate predictive processing in conversation. Experimental results demonstrate that our model outperforms state-of-the-art MLLMs in terms of lexical overlap, semantic similarity, and emotion consistency. Our results prove the feasibility of next-utterance prediction with LLMs from multimodal cues and emphasize the (i) indispensable role of multimodal cues and (ii) actively predictive processing as the foundation of natural human interaction, which is missing in current MLLMs. We hope that this exploration offers a new research entry toward more human-like, context-sensitive AI interaction for human-centered AI. Our benchmark and model can be accessed at https://saynext.github.io/.
ReGuLaR: Variational Latent Reasoning Guided by Rendered Chain-of-Thought
Jan 30, 2026While Chain-of-Thought (CoT) significantly enhances the performance of Large Language Models (LLMs), explicit reasoning chains introduce substantial computational redundancy. Recent latent reasoning methods attempt to mitigate this by compressing reasoning processes into latent space, but often suffer from severe performance degradation due to the lack of appropriate compression guidance. In this study, we propose Rendered CoT-Guided variational Latent Reasoning (ReGuLaR), a simple yet novel latent learning paradigm resolving this issue. Fundamentally, we formulate latent reasoning within the Variational Auto-Encoding (VAE) framework, sampling the current latent reasoning state from the posterior distribution conditioned on previous ones. Specifically, when learning this variational latent reasoning model, we render explicit reasoning chains as images, from which we extract dense visual-semantic representations to regularize the posterior distribution, thereby achieving efficient compression with minimal information loss. Extensive experiments demonstrate that ReGuLaR significantly outperforms existing latent reasoning methods across both computational efficiency and reasoning effectiveness, and even surpasses CoT through multi-modal reasoning, providing a new and insightful solution to latent reasoning. Code: https://github.com/FanmengWang/ReGuLaR.
Integrated Sensing, Communication and Control enabled Agile UAV Swarm
Jan 21, 2026Uncrewed aerial vehicle (UAV) swarms are pivotal in the applications such as disaster relief, aerial base station (BS) and logistics transportation. These scenarios require the capabilities in accurate sensing, efficient communication and flexible control for real-time and reliable task execution. However, sensing, communication and control are studied independently in traditional research, which limits the overall performance of UAV swarms. To overcome this disadvantage, we propose a deeply coupled scheme of integrated sensing, communication and control (ISCC) for UAV swarms, which is a systemic paradigm that transcends traditional isolated designs of sensing, communication and control by establishing a tightly-coupled closed-loop through the co-optimization of sensing, communication and control. In this article, we firstly analyze the requirements of scenarios and key performance metrics. Subsequently, the enabling technologies are proposed, including communication-and-control-enhanced sensing, sensing-and-control-enhanced communication, and sensing-and-communication-enhanced control. Simulation results validate the performance of the proposed ISCC framework, demonstrating its application potential in the future.
Beyond Target-Level: ISAC-Enabled Event-Level Sensing for Behavioral Intention Prediction
Jan 17, 2026Integrated Sensing and Communication (ISAC) holds great promise for enabling event-level sensing, such as behavioral intention prediction (BIP) in autonomous driving, particularly under non-line-of-sight (NLoS) or adverse weather conditions where conventional sensors degrade. However, as a key instance of event-level sensing, ISAC-based BIP remains unexplored. To address this gap, we propose an ISAC-enabled BIP framework and validate its feasibility and effectiveness through extensive simulations. Our framework achieves robust performance in safety-critical scenarios, improving the F1-score by 11.4% over sensor-based baselines in adverse weather, thereby demonstrating ISAC's potential for intelligent event-level sensing.
One Request, Multiple Experts: LLM Orchestrates Domain Specific Models via Adaptive Task Routing
Nov 16, 2025With the integration of massive distributed energy resources and the widespread participation of novel market entities, the operation of active distribution networks (ADNs) is progressively evolving into a complex multi-scenario, multi-objective problem. Although expert engineers have developed numerous domain specific models (DSMs) to address distinct technical problems, mastering, integrating, and orchestrating these heterogeneous DSMs still entail considerable overhead for ADN operators. Therefore, an intelligent approach is urgently required to unify these DSMs and enable efficient coordination. To address this challenge, this paper proposes the ADN-Agent architecture, which leverages a general large language model (LLM) to coordinate multiple DSMs, enabling adaptive intent recognition, task decomposition, and DSM invocation. Within the ADN-Agent, we design a novel communication mechanism that provides a unified and flexible interface for diverse heterogeneous DSMs. Finally, for some language-intensive subtasks, we propose an automated training pipeline for fine-tuning small language models, thereby effectively enhancing the overall problem-solving capability of the system. Comprehensive comparisons and ablation experiments validate the efficacy of the proposed method and demonstrate that the ADN-Agent architecture outperforms existing LLM application paradigms.
Multipath Component-Enhanced Signal Processing for Integrated Sensing and Communication Systems
Jun 09, 2025Integrated sensing and communication (ISAC) has gained traction in academia and industry. Recently, multipath components (MPCs), as a type of spatial resource, have the potential to improve the sensing performance in ISAC systems, especially in richly scattering environments. In this paper, we propose to leverage MPC and Khatri-Rao space-time (KRST) code within a single ISAC system to realize high-accuracy sensing for multiple dynamic targets and multi-user communication. Specifically, we propose a novel MPC-enhanced sensing processing scheme with symbol-level fusion, referred to as the "SL-MPS" scheme, to achieve high-accuracy localization of multiple dynamic targets and empower the single ISAC system with a new capability of absolute velocity estimation for multiple targets with a single sensing attempt. Furthermore, the KRST code is applied to flexibly balance communication and sensing performance in richly scattering environments. To evaluate the contribution of MPCs, the closed-form Cram\'er-Rao lower bounds (CRLBs) of location and absolute velocity estimation are derived. Simulation results illustrate that the proposed SL-MPS scheme is more robust and accurate in localization and absolute velocity estimation compared with the existing state-of-the-art schemes.
DTRT: Enhancing Human Intent Estimation and Role Allocation for Physical Human-Robot Collaboration
May 26, 2025In physical Human-Robot Collaboration (pHRC), accurate human intent estimation and rational human-robot role allocation are crucial for safe and efficient assistance. Existing methods that rely on short-term motion data for intention estimation lack multi-step prediction capabilities, hindering their ability to sense intent changes and adjust human-robot assignments autonomously, resulting in potential discrepancies. To address these issues, we propose a Dual Transformer-based Robot Trajectron (DTRT) featuring a hierarchical architecture, which harnesses human-guided motion and force data to rapidly capture human intent changes, enabling accurate trajectory predictions and dynamic robot behavior adjustments for effective collaboration. Specifically, human intent estimation in DTRT uses two Transformer-based Conditional Variational Autoencoders (CVAEs), incorporating robot motion data in obstacle-free case with human-guided trajectory and force for obstacle avoidance. Additionally, Differential Cooperative Game Theory (DCGT) is employed to synthesize predictions based on human-applied forces, ensuring robot behavior align with human intention. Compared to state-of-the-art (SOTA) methods, DTRT incorporates human dynamics into long-term prediction, providing an accurate understanding of intention and enabling rational role allocation, achieving robot autonomy and maneuverability. Experiments demonstrate DTRT's accurate intent estimation and superior collaboration performance.
OpenNIRScap: An Open-Source, Low-Cost Wearable Near-Infrared Spectroscopy-based Brain Interfacing Cap
May 26, 2025Functional Near-Infrared Spectroscopy (fNIRS) is a non-invasive, real-time method for monitoring brain activity by measuring hemodynamic responses in the cerebral cortex. However, existing systems are expensive, bulky, and limited to clinical or research environments. This paper introduces OpenNIRScap, an open-source, low-cost, and wearable fNIRS system designed to make real-time brain monitoring more accessible in everyday environments. The device features 24 custom-designed sensor boards with dual-wavelength light emitters and photodiode detectors, a central electrical control unit (ECU) with analog multiplexing, and a real-time data processing pipeline. Bench validation and pilot tests on volunteers have confirmed the ability of the system to capture cognitively evoked hemodynamic responses, supporting its potential as an affordable tool for cognitive monitoring and portable neurotechnology applications. The hardware, software, and graphical user interface have all been open-sourced and made publicly available at the following link: https://github.com/tonykim07/fNIRS.
AlayaDB: The Data Foundation for Efficient and Effective Long-context LLM Inference
Apr 14, 2025AlayaDB is a cutting-edge vector database system natively architected for efficient and effective long-context inference for Large Language Models (LLMs) at AlayaDB AI. Specifically, it decouples the KV cache and attention computation from the LLM inference systems, and encapsulates them into a novel vector database system. For the Model as a Service providers (MaaS), AlayaDB consumes fewer hardware resources and offers higher generation quality for various workloads with different kinds of Service Level Objectives (SLOs), when comparing with the existing alternative solutions (e.g., KV cache disaggregation, retrieval-based sparse attention). The crux of AlayaDB is that it abstracts the attention computation and cache management for LLM inference into a query processing procedure, and optimizes the performance via a native query optimizer. In this work, we demonstrate the effectiveness of AlayaDB via (i) three use cases from our industry partners, and (ii) extensive experimental results on LLM inference benchmarks.
Multipath Component-Aided Signal Processing for Integrated Sensing and Communication Systems
Dec 31, 2024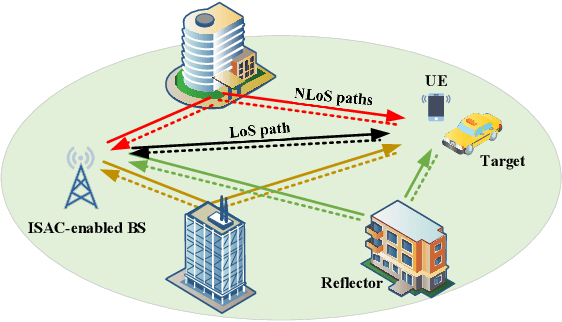
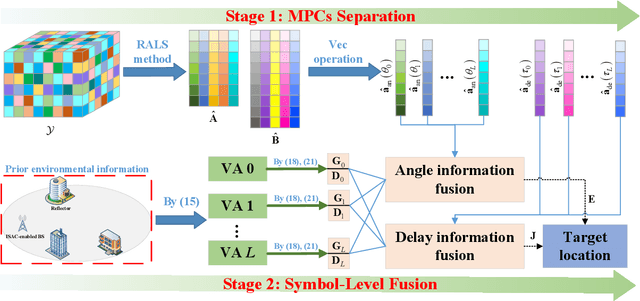
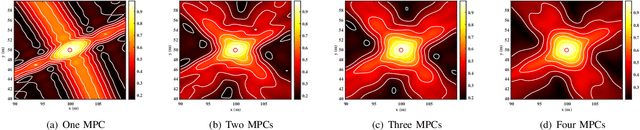
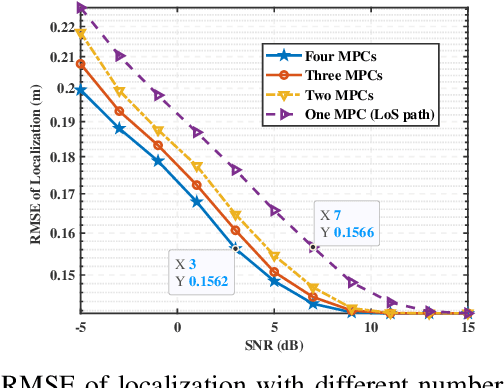
Integrated sensing and communication (ISAC) has emerged as a pivotal enabling technology for sixth-generation (6G) mobile communication system. The ISAC research in dense urban areas has been plaguing by severe multipath interference, propelling the thorough research of ISAC multipath interference elimination. However, transforming the multipath component (MPC) from enemy into friend is a viable and mutually beneficial option. In this paper, we preliminarily explore the MPC-aided ISAC signal processing and apply a space-time code to improve the ISAC performance. Specifically, we propose a symbol-level fusion for MPC-aided localization (SFMC) scheme to achieve robust and high-accuracy localization, and apply a Khatri-Rao space-time (KRST) code to improve the communication and sensing performance in rich multipath environment. Simulation results demonstrate that the proposed SFMC scheme has more robust localization performance with higher accuracy, compared with the existing state-of-the-art schemes. The proposed SFMC would benefit highly reliable communication and sub-meter level localization in rich multipath scenarios.