 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Completion: Probing Cumulative State Tracking to Predict LLM Agent Performance
Mar 28, 2026Task-completion rate is the standard proxy for LLM agent capability, but models with identical completion scores can differ substantially in their ability to track intermediate state. We introduce Working Memory Fidelity-Active Manipulation (WMF-AM), a calibrated no-scratchpad probe of cumulative arithmetic state tracking, and evaluate it on 20 open-weight models (0.5B-35B, 13 families) against a released deterministic 10-task agent battery. In a pre-specified, Bonferroni-corrected analysis, WMF-AM predicts agent performance with Kendall's tau = 0.612 (p < 0.001, 95% CI [0.360, 0.814]); exploratory partial-tau analyses suggest this signal persists after controlling for completion score and model scale. Three construct-isolation ablations (K = 1 control, non-arithmetic ceiling, yoked cancellation) support the interpretation that cumulative state tracking under load, rather than single-step arithmetic or entity tracking alone, is the primary difficulty source. K-calibration keeps the probe in a discriminative range where prior fixed-depth benchmarks become non-discriminative; generalization beyond this open-weight sample remains open.
Constitutive Components for Human-Like Autonomous Artificial Intelligence
Jun 15, 2025This study is the first to clearly identify the functions required to construct artificial entities capable of behaving autonomously like humans, and organizes them into a three-layer functional hierarchy. Specifically, it defines three levels: Core Functions, which enable interaction with the external world; the Integrative Evaluation Function, which selects actions based on perception and memory; and the Self Modification Function, which dynamically reconfigures behavioral principles and internal components. Based on this structure, the study proposes a stepwise model of autonomy comprising reactive, weak autonomous, and strong autonomous levels, and discusses its underlying design principles and developmental aspects. It also explores the relationship between these functions and existing artificial intelligence design methods, addressing their potential as a foundation for general intelligence and considering future applications and ethical implications. By offering a theoretical framework that is independent of specific technical methods, this work contributes to a deeper understanding of autonomy and provides a foundation for designing future artificial entities with strong autonomy.
A Language Anchor-Guided Method for Robust Noisy Domain Generalization
Mar 21, 2025Real-world machine learning applications often struggle with two major challenges: distribution shift and label noise. Models tend to overfit by focusing on redundant and uninformative features in the training data, which makes it hard for them to generalize to the target domain. Noisy data worsens this problem by causing further overfitting to the noise, meaning that existing methods often fail to tell the difference between true, invariant features and misleading, spurious ones. To tackle these issues, we introduce Anchor Alignment and Adaptive Weighting (A3W). This new algorithm uses sample reweighting guided by natural language processing (NLP) anchors to extract more representative features. In simple terms, A3W leverages semantic representations from natural language models as a source of domain-invariant prior knowledge. Additionally, it employs a weighted loss function that adjusts each sample's contribution based on its similarity to the corresponding NLP anchor. This adjustment makes the model more robust to noisy labels. Extensive experiments on standard benchmark datasets show that A3W consistently outperforms state-of-the-art domain generalization methods, offering significant improvements in both accuracy and robustness across different datasets and noise levels.
Hyperbolic Chamfer Distance for Point Cloud Completion and Beyond
Dec 23, 2024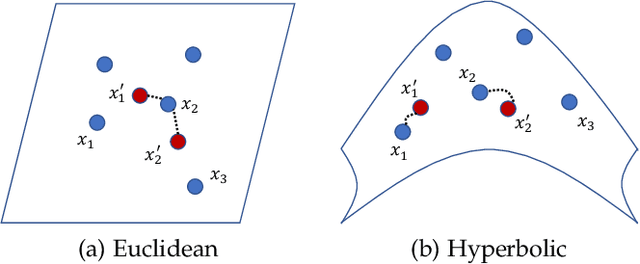
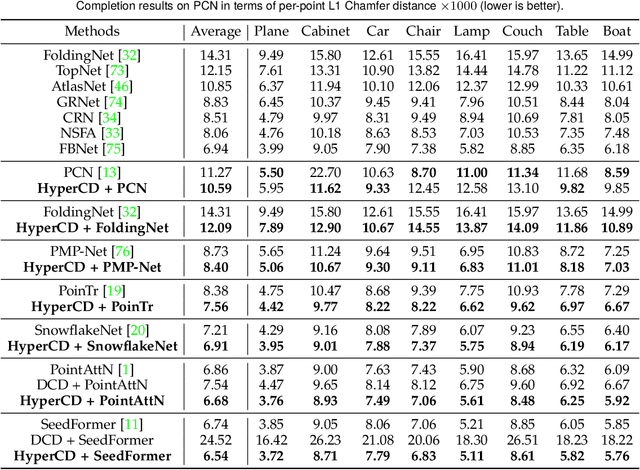
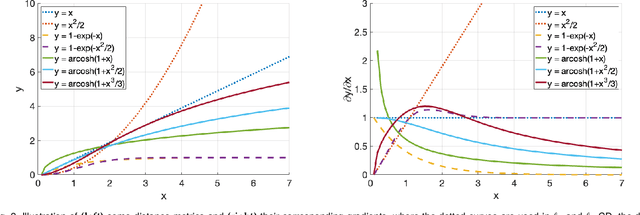
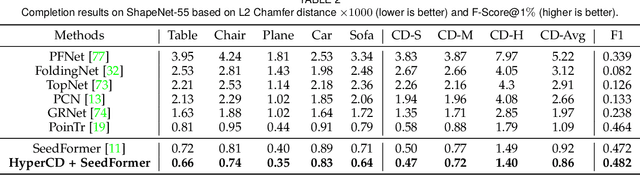
Chamfer Distance (CD) is widely used as a metric to quantify difference between two point clouds. In point cloud completion, Chamfer Distance (CD) is typically used as a loss function in deep learning frameworks. However, it is generally acknowledged within the field that Chamfer Distance (CD) is vulnerable to the presence of outliers, which can consequently lead to the convergence on suboptimal models. In divergence from the existing literature, which largely concentrates on resolving such concerns in the realm of Euclidean space, we put forth a notably uncomplicated yet potent metric specifically designed for point cloud completion tasks: {Hyperbolic Chamfer Distance (HyperCD)}. This metric conducts Chamfer Distance computations within the parameters of hyperbolic space. During the backpropagation process, HyperCD systematically allocates greater weight to matched point pairs exhibiting reduced Euclidean distances. This mechanism facilitates the preservation of accurate point pair matches while permitting the incremental adjustment of suboptimal matches, thereby contributing to enhanced point cloud completion outcomes. Moreover, measure the shape dissimilarity is not solely work for point cloud completion task, we further explore its applications in other generative related tasks, including single image reconstruction from point cloud, and upsampling. We demonstrate state-of-the-art performance on the point cloud completion benchmark datasets, PCN, ShapeNet-55, and ShapeNet-34, and show from visualization that HyperCD can significantly improve the surface smoothness, we also provide the provide experimental results beyond completion task.
Loss Distillation via Gradient Matching for Point Cloud Completion with Weighted Chamfer Distance
Sep 10, 2024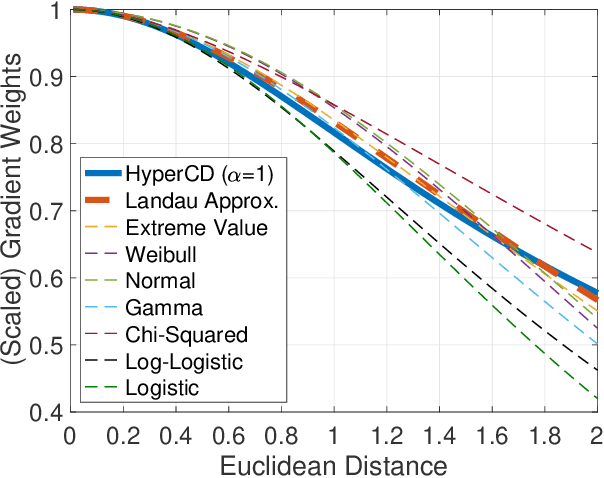
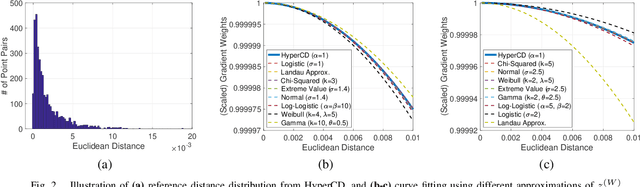


3D point clouds enhanced the robot's ability to perceive the geometrical information of the environments, making it possible for many downstream tasks such as grasp pose detection and scene understanding. The performance of these tasks, though, heavily relies on the quality of data input, as incomplete can lead to poor results and failure cases. Recent training loss functions designed for deep learning-based point cloud completion, such as Chamfer distance (CD) and its variants (\eg HyperCD ), imply a good gradient weighting scheme can significantly boost performance. However, these CD-based loss functions usually require data-related parameter tuning, which can be time-consuming for data-extensive tasks. To address this issue, we aim to find a family of weighted training losses ({\em weighted CD}) that requires no parameter tuning. To this end, we propose a search scheme, {\em Loss Distillation via Gradient Matching}, to find good candidate loss functions by mimicking the learning behavior in backpropagation between HyperCD and weighted CD. Once this is done, we propose a novel bilevel optimization formula to train the backbone network based on the weighted CD loss. We observe that: (1) with proper weighted functions, the weighted CD can always achieve similar performance to HyperCD, and (2) the Landau weighted CD, namely {\em Landau CD}, can outperform HyperCD for point cloud completion and lead to new state-of-the-art results on several benchmark datasets. {\it Our demo code is available at \url{https://github.com/Zhang-VISLab/IROS2024-LossDistillationWeightedCD}.}
Learning Random Numbers to Realize Appendable Memory System for Artificial Intelligence to Acquire New Knowledge after Deployment
Jul 29, 2024In this study, we developed a learning method for constructing a neural network system capable of memorizing data and recalling it without parameter updates. The system we built using this method is called the Appendable Memory system. The Appendable Memory system enables an artificial intelligence (AI) to acquire new knowledge even after deployment. It consists of two AIs: the Memorizer and the Recaller. This system is a key-value store built using neural networks. The Memorizer receives data and stores it in the Appendable Memory vector, which is dynamically updated when the AI acquires new knowledge. Meanwhile, the Recaller retrieves information from the Appendable Memory vector. What we want to teach AI in this study are the operations of memorizing and recalling information. However, traditional machine learning methods make AI learn features inherent in the learning dataset. We demonstrate that the systems we intend to create cannot be realized by current machine learning methods, that is, by merely repeating the input and output learning sequences with AI. Instead, we propose a method to teach AI to learn operations, by completely removing the features contained in the learning dataset. Specifically, we probabilized all the data involved in learning. This measure prevented AI from learning the features of the data. The learning method proposed in the study differs from traditional machine learning methods and provides fundamental approaches for building an AI system that can store information in a finite memory and recall it at a later date.
Procedural Content Generation via Generative Artificial Intelligence
Jul 12, 2024The attempt to utilize machine learning in PCG has been made in the past. In this survey paper, we investigate how generative artificial intelligence (AI), which saw a significant increase in interest in the mid-2010s, is being used for PCG. We review applications of generative AI for the creation of various types of content, including terrains, items, and even storylines. While generative AI is effective for PCG, one significant issues it faces is that building high-performance generative AI requires vast amounts of training data. Because content generally highly customized, domain-specific training data is scarce, and straightforward approaches to generative AI models may not work well. For PCG research to advance further, issues related to limited training data must be overcome. Thus, we also give special consideration to research that addresses the challenges posed by limited training data.
Hyperbolic Contrastive Learning
Feb 02, 2023



Learning good image representations that are beneficial to downstream tasks is a challenging task in computer vision. As such, a wide variety of self-supervised learning approaches have been proposed. Among them, contrastive learning has shown competitive performance on several benchmark datasets. The embeddings of contrastive learning are arranged on a hypersphere that results in using the inner (dot) product as a distance measurement in Euclidean space. However, the underlying structure of many scientific fields like social networks, brain imaging, and computer graphics data exhibit highly non-Euclidean latent geometry. We propose a novel contrastive learning framework to learn semantic relationships in the hyperbolic space. Hyperbolic space is a continuous version of trees that naturally owns the ability to model hierarchical structures and is thus beneficial for efficient contrastive representation learning. We also extend the proposed Hyperbolic Contrastive Learning (HCL) to the supervised domain and studied the adversarial robustness of HCL. The comprehensive experiments show that our proposed method achieves better results on self-supervised pretraining, supervised classification, and higher robust accuracy than baseline methods.
Optimizing scoring function of dynamic programming of pairwise profile alignment using derivative free neural network
Sep 08, 2017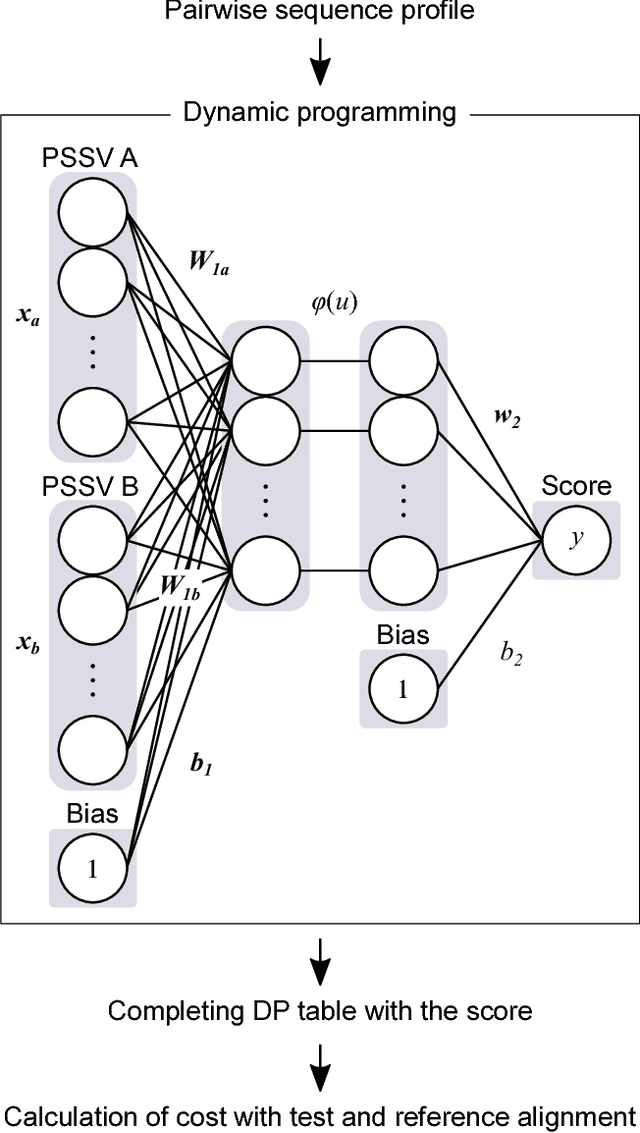
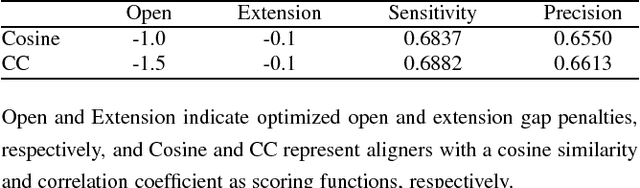
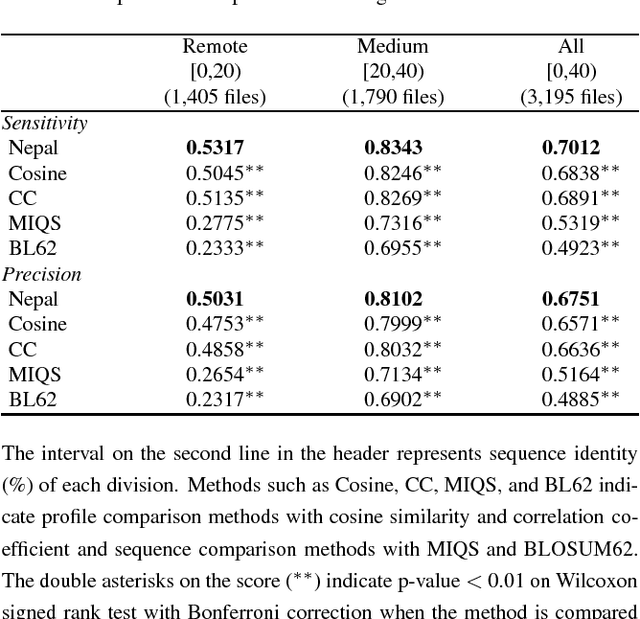
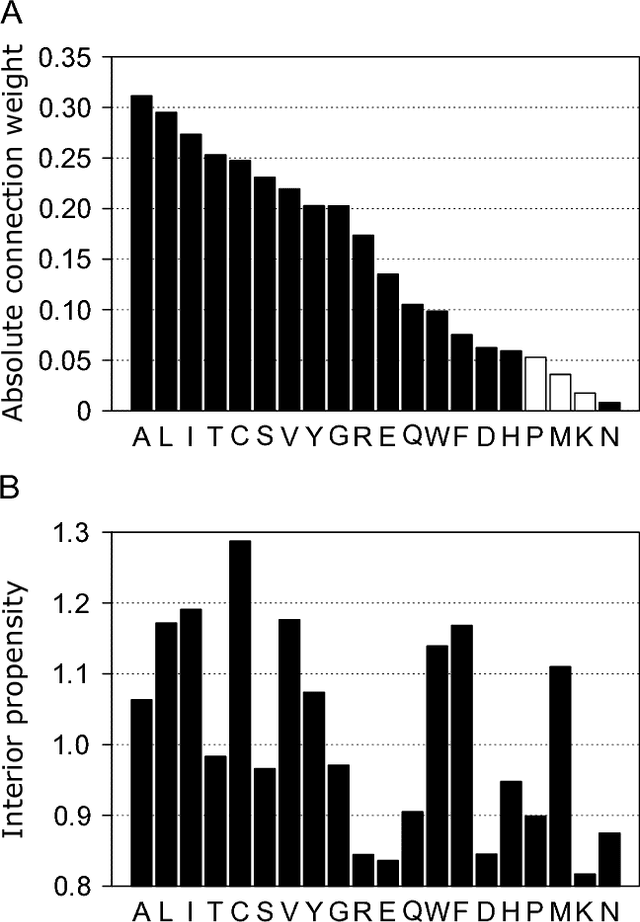
A profile comparison method with position-specific scoring matrix (PSSM) is one of the most accurate alignment methods. Currently, cosine similarity and correlation coefficient are used as scoring functions of dynamic programming to calculate similarity between PSSMs. However, it is unclear that these functions are optimal for profile alignment methods. At least, by definition, these functions cannot capture non-linear relationships between profiles. Therefore, in this study, we attempted to discover a novel scoring function, which was more suitable for the profile comparison method than the existing ones. Firstly we implemented a new derivative free neural network by combining the conventional neural network with evolutionary strategy optimization method. Next, using the framework, the scoring function was optimized for aligning remote sequence pairs. Nepal, the pairwise profile aligner with the novel scoring function significantly improved both alignment sensitivity and precision, compared to aligners with the existing functions. Nepal improved alignment quality because of adaptation to remote sequence alignment and increasing the expressive power of similarity score. The novel scoring function can be realized using a simple matrix operation and easily incorporated into other aligners. With our scoring function, the performance of homology detection and/or multiple sequence alignment for remote homologous sequences would be further improved.