 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Language Anchor-Guided Method for Robust Noisy Domain Generalization
Mar 21, 2025Real-world machine learning applications often struggle with two major challenges: distribution shift and label noise. Models tend to overfit by focusing on redundant and uninformative features in the training data, which makes it hard for them to generalize to the target domain. Noisy data worsens this problem by causing further overfitting to the noise, meaning that existing methods often fail to tell the difference between true, invariant features and misleading, spurious ones. To tackle these issues, we introduce Anchor Alignment and Adaptive Weighting (A3W). This new algorithm uses sample reweighting guided by natural language processing (NLP) anchors to extract more representative features. In simple terms, A3W leverages semantic representations from natural language models as a source of domain-invariant prior knowledge. Additionally, it employs a weighted loss function that adjusts each sample's contribution based on its similarity to the corresponding NLP anchor. This adjustment makes the model more robust to noisy labels. Extensive experiments on standard benchmark datasets show that A3W consistently outperforms state-of-the-art domain generalization methods, offering significant improvements in both accuracy and robustness across different datasets and noise levels.
Advancing Out-of-Distribution Detection through Data Purification and Dynamic Activation Function Design
Mar 06, 2024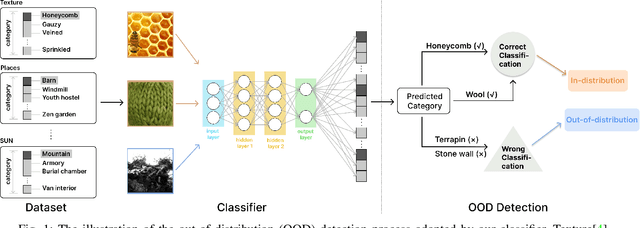
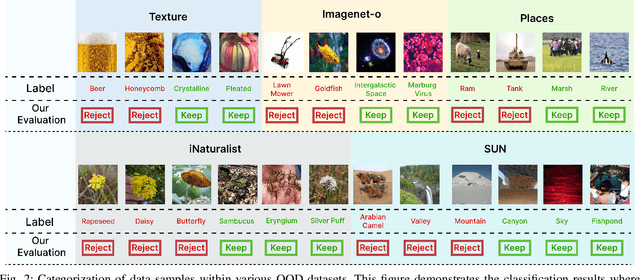
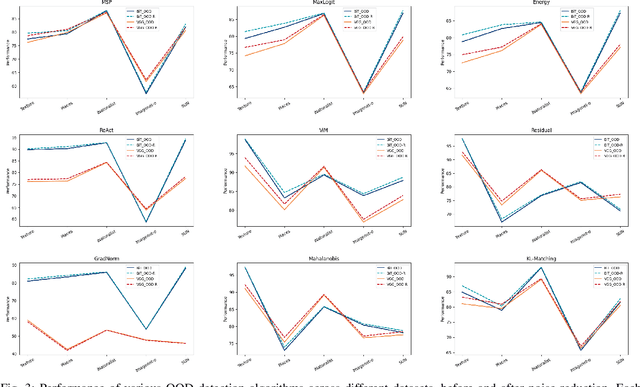
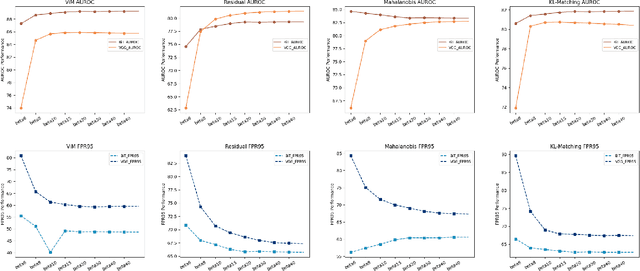
In the dynamic realms of machine learning and deep learning, the robustness and reliability of models are paramount, especially in critical real-world applications. A fundamental challenge in this sphere is managing Out-of-Distribution (OOD) samples, significantly increasing the risks of model misclassification and uncertainty. Our work addresses this challenge by enhancing the detection and management of OOD samples in neural networks. We introduce OOD-R (Out-of-Distribution-Rectified), a meticulously curated collection of open-source datasets with enhanced noise reduction properties. In-Distribution (ID) noise in existing OOD datasets can lead to inaccurate evaluation of detection algorithms. Recognizing this, OOD-R incorporates noise filtering technologies to refine the datasets, ensuring a more accurate and reliable evaluation of OOD detection algorithms. This approach not only improves the overall quality of data but also aids in better distinguishing between OOD and ID samples, resulting in up to a 2.5\% improvement in model accuracy and a minimum 3.2\% reduction in false positives. Furthermore, we present ActFun, an innovative method that fine-tunes the model's response to diverse inputs, thereby improving the stability of feature extraction and minimizing specificity issues. ActFun addresses the common problem of model overconfidence in OOD detection by strategically reducing the influence of hidden units, which enhances the model's capability to estimate OOD uncertainty more accurately. Implementing ActFun in the OOD-R dataset has led to significant performance enhancements, including an 18.42\% increase in AUROC of the GradNorm method and a 16.93\% decrease in FPR95 of the Energy method. Overall, our research not only advances the methodologies in OOD detection but also emphasizes the importance of dataset integrity for accurate algorithm evaluation.
CompdVision: Combining Near-Field 3D Visual and Tactile Sensing Using a Compact Compound-Eye Imaging System
Dec 12, 2023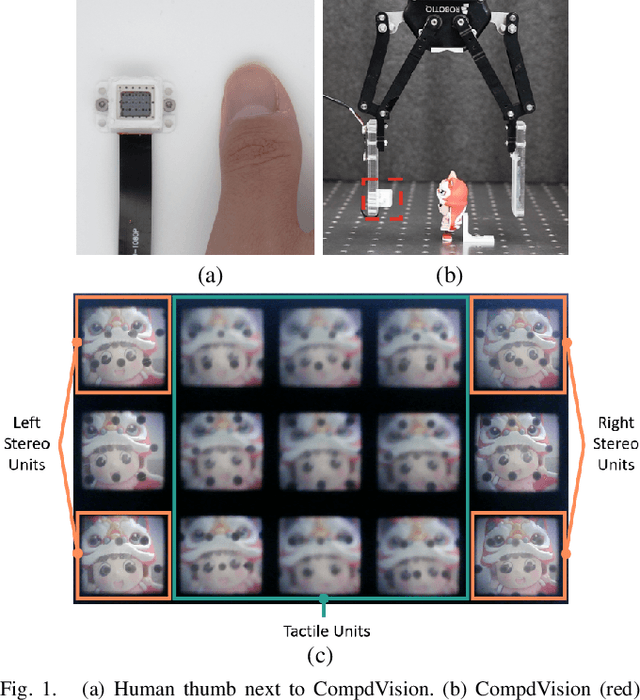
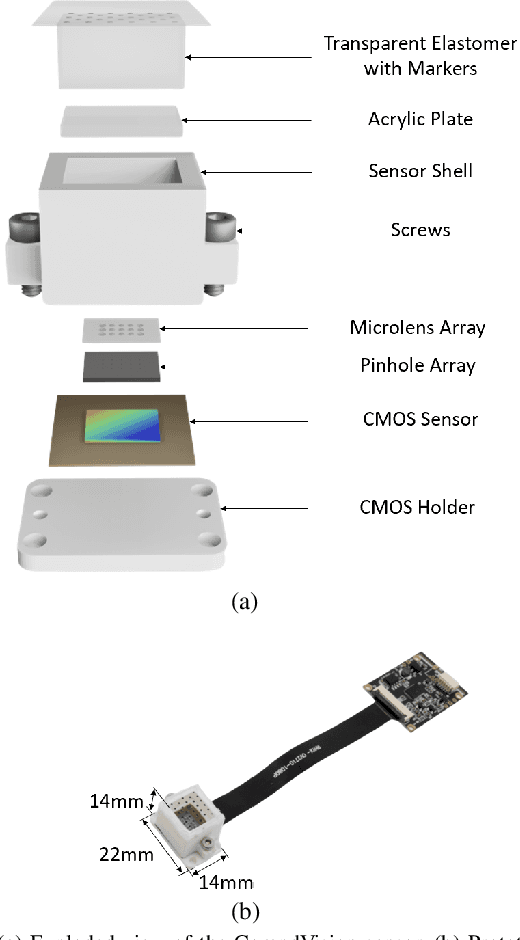
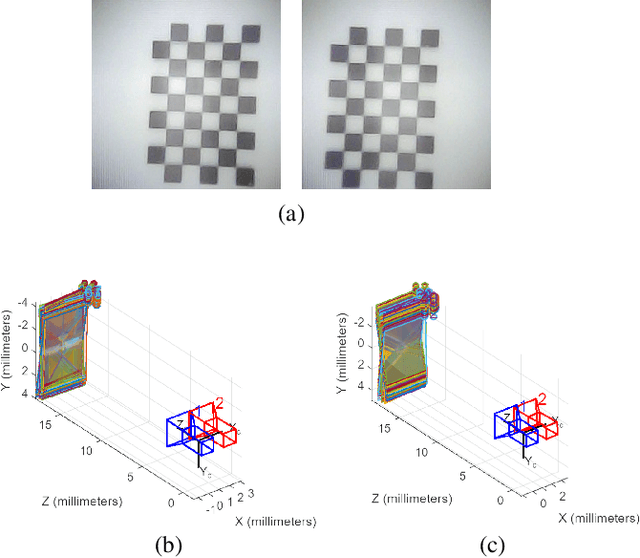

As automation technologies advance, the need for compact and multi-modal sensors in robotic applications is growing. To address this demand, we introduce CompdVision, a novel sensor that combines near-field 3D visual and tactile sensing. This sensor, with dimensions of 22$\times$14$\times$14 mm, leverages the compound eye imaging system to achieve a compact form factor without compromising its dual modalities. CompdVision utilizes two types of vision units to meet diverse sensing requirements. Stereo units with far-focus lenses can see through the transparent elastomer, facilitating depth estimation beyond the contact surface, while tactile units with near-focus lenses track the movement of markers embedded in the elastomer to obtain contact deformation. Experimental results validate the sensor's superior performance in 3D visual and tactile sensing. The sensor demonstrates effective depth estimation within a 70mm range from its surface. Additionally, it registers high accuracy in tangential and normal force measurements. The dual modalities and compact design make the sensor a versatile tool for complex robotic tasks.
Enhancing Few-shot CLIP with Semantic-Aware Fine-Tuning
Nov 09, 2023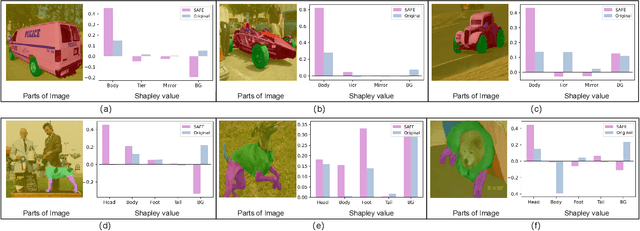
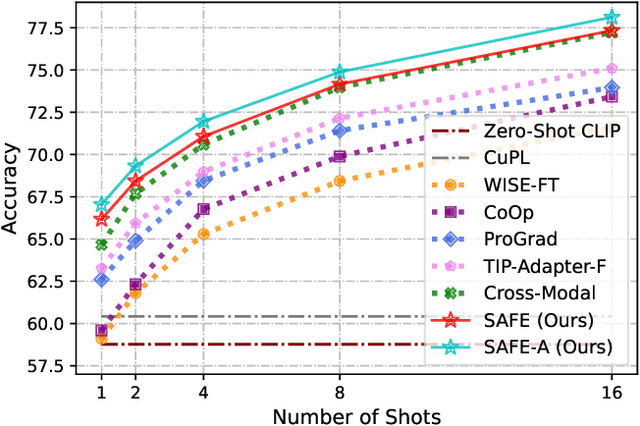
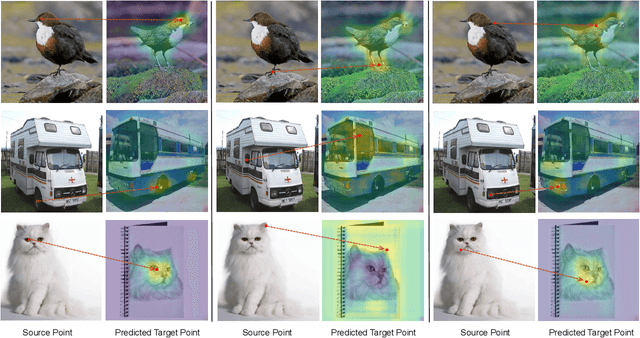
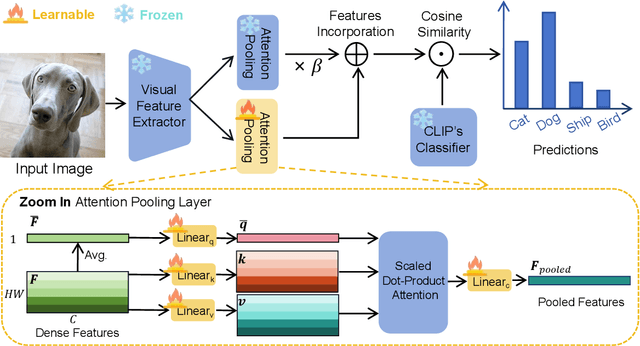
Learning generalized representations from limited training samples is crucial for applying deep neural networks in low-resource scenarios. Recently, methods based on Contrastive Language-Image Pre-training (CLIP) have exhibited promising performance in few-shot adaptation tasks. To avoid catastrophic forgetting and overfitting caused by few-shot fine-tuning, existing works usually freeze the parameters of CLIP pre-trained on large-scale datasets, overlooking the possibility that some parameters might not be suitable for downstream tasks. To this end, we revisit CLIP's visual encoder with a specific focus on its distinctive attention pooling layer, which performs a spatial weighted-sum of the dense feature maps. Given that dense feature maps contain meaningful semantic information, and different semantics hold varying importance for diverse downstream tasks (such as prioritizing semantics like ears and eyes in pet classification tasks rather than side mirrors), using the same weighted-sum operation for dense features across different few-shot tasks might not be appropriate. Hence, we propose fine-tuning the parameters of the attention pooling layer during the training process to encourage the model to focus on task-specific semantics. In the inference process, we perform residual blending between the features pooled by the fine-tuned and the original attention pooling layers to incorporate both the few-shot knowledge and the pre-trained CLIP's prior knowledge. We term this method as Semantic-Aware FinE-tuning (SAFE). SAFE is effective in enhancing the conventional few-shot CLIP and is compatible with the existing adapter approach (termed SAFE-A).
Generative Flow Networks for Precise Reward-Oriented Active Learning on Graphs
Apr 24, 2023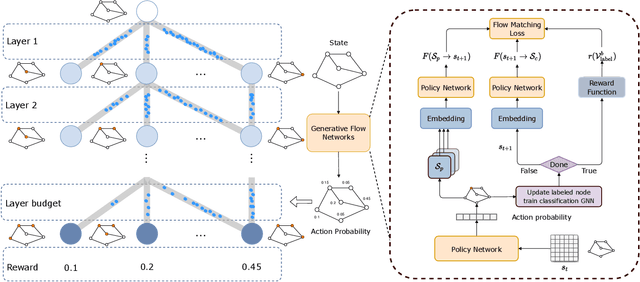
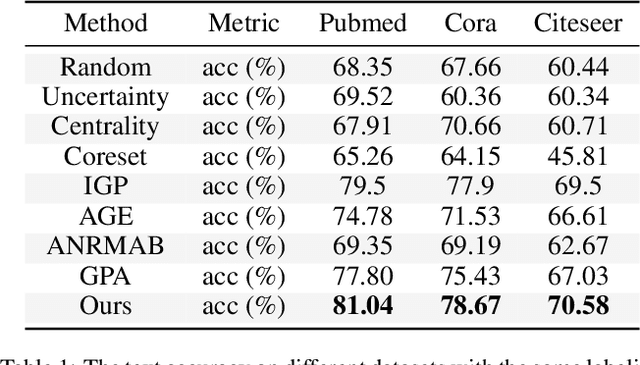
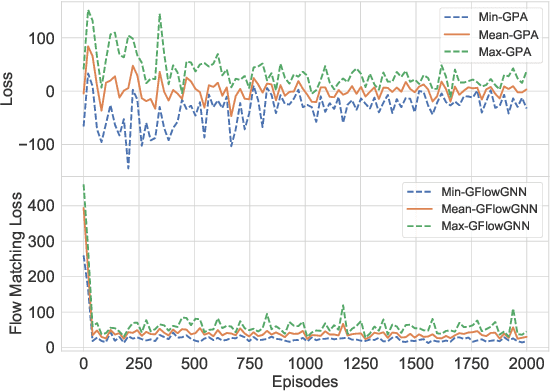
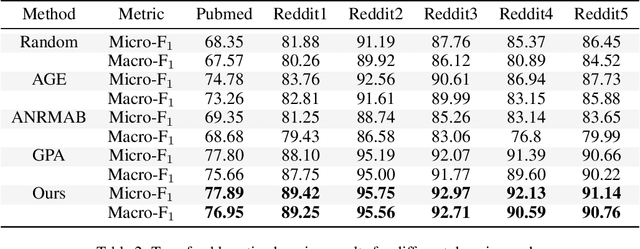
Many score-based active learning methods have been successfully applied to graph-structured data, aiming to reduce the number of labels and achieve better performance of graph neural networks based on predefined score functions. However, these algorithms struggle to learn policy distributions that are proportional to rewards and have limited exploration capabilities. In this paper, we innovatively formulate the graph active learning problem as a generative process, named GFlowGNN, which generates various samples through sequential actions with probabilities precisely proportional to a predefined reward function. Furthermore, we propose the concept of flow nodes and flow features to efficiently model graphs as flows based on generative flow networks, where the policy network is trained with specially designed rewards. Extensive experiments on real datasets show that the proposed approach has good exploration capability and transferability, outperforming various state-of-the-art methods.
DAG Matters! GFlowNets Enhanced Explainer For Graph Neural Networks
Mar 04, 2023



Uncovering rationales behind predictions of graph neural networks (GNNs) has received increasing attention over the years. Existing literature mainly focus on selecting a subgraph, through combinatorial optimization, to provide faithful explanations. However, the exponential size of candidate subgraphs limits the applicability of state-of-the-art methods to large-scale GNNs. We enhance on this through a different approach: by proposing a generative structure -- GFlowNets-based GNN Explainer (GFlowExplainer), we turn the optimization problem into a step-by-step generative problem. Our GFlowExplainer aims to learn a policy that generates a distribution of subgraphs for which the probability of a subgraph is proportional to its' reward. The proposed approach eliminates the influence of node sequence and thus does not need any pre-training strategies. We also propose a new cut vertex matrix to efficiently explore parent states for GFlowNets structure, thus making our approach applicable in a large-scale setting. We conduct extensive experiments on both synthetic and real datasets, and both qualitative and quantitative results show the superiority of our GFlowExplainer.
Contention-based Grant-free Transmission with Extremely Sparse Orthogonal Pilot Scheme
Jun 08, 2021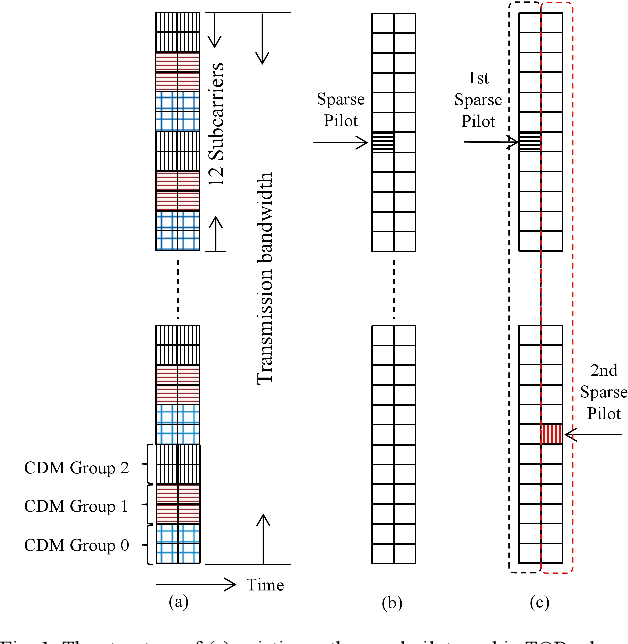


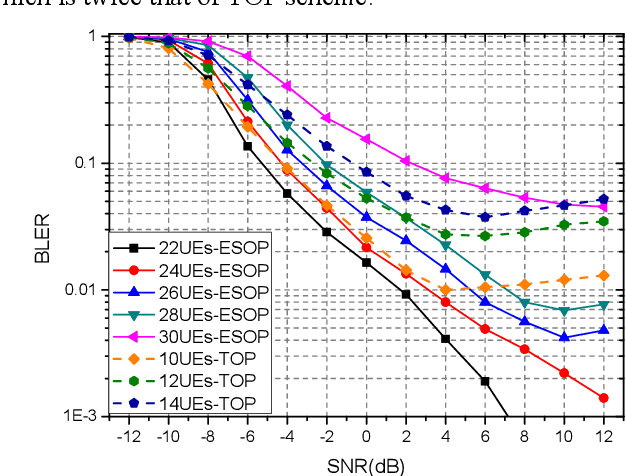
Due to the limited number of traditional orthogonal pilots, pilot collision will severely degrade the performance of contention-based grant-free transmission. To alleviate the pilot collision and exploit the spatial degree of freedom as much as possible, an extremely sparse orthogonal pilot scheme is proposed for uplink grant-free transmission. The proposed sparse pilot is used to perform active user detection and estimate the spatial channel. Then, inter-user interference suppression is performed by spatially combining the received data symbols using the estimated spatial channel. After that, the estimation and compensation of wireless channel and time/frequency offset are performed utilizing the geometric characteristics of combined data symbols. The task of pilot is much lightened, so that the extremely sparse orthogonal pilot can occupy minimized resources, and the number of orthogonal pilots can be increased significantly, which greatly reduces the probability of pilot collision. The numerical results show that the proposed extremely sparse orthogonal pilot scheme significantly improves the performance in high-overloading grant-free scenario.
PFRL: Pose-Free Reinforcement Learning for 6D Pose Estimation
Feb 24, 2021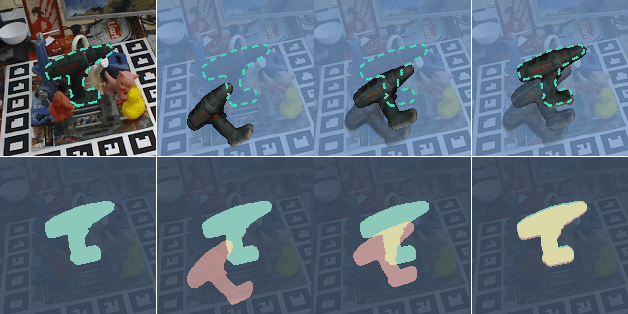
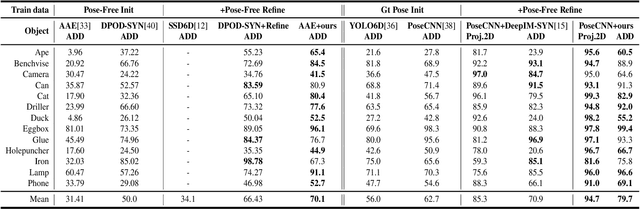
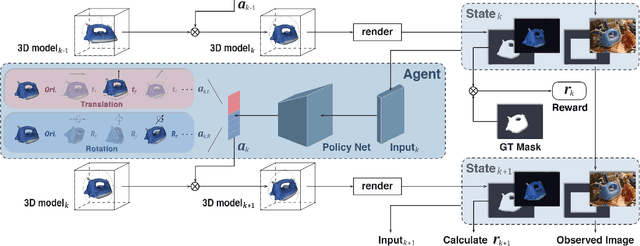
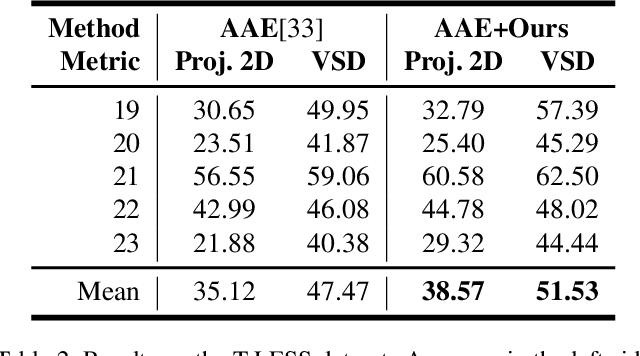
6D pose estimation from a single RGB image is a challenging and vital task in computer vision. The current mainstream deep model methods resort to 2D images annotated with real-world ground-truth 6D object poses, whose collection is fairly cumbersome and expensive, even unavailable in many cases. In this work, to get rid of the burden of 6D annotations, we formulate the 6D pose refinement as a Markov Decision Process and impose on the reinforcement learning approach with only 2D image annotations as weakly-supervised 6D pose information, via a delicate reward definition and a composite reinforced optimization method for efficient and effective policy training. Experiments on LINEMOD and T-LESS datasets demonstrate that our Pose-Free approach is able to achieve state-of-the-art performance compared with the methods without using real-world ground-truth 6D pose labels.
PDRS: A Fast Non-iterative Scheme for Massive Grant-free Access in Massive MIMO
Dec 25, 2020

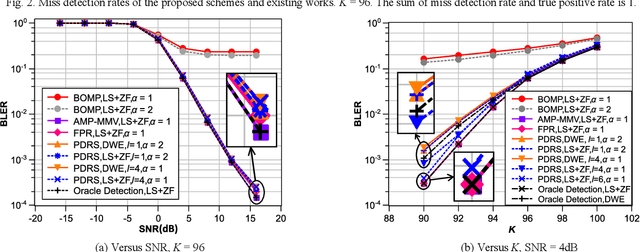

Grant-free multiple-input multiple-output (MIMO) usually employs non-orthogonal pilots for joint user detection and channel estimation. However, existing methods are too complex for massive grant-free access in massive MIMO. This letter proposes pilot detection reference signal (PDRS) to greatly reduce the complexity. In PDRS scheme, no iteration is required. Direct weight estimation is also proposed to calculate combining weights without channel estimation. After combining, PDRS recovery errors are used to decide the pilot activity. The simulation results show that the proposed grant-free scheme performs good with a complexity reduced by orders of magnitude.
Robust RGB-based 6-DoF Pose Estimation without Real Pose Annotations
Aug 19, 2020
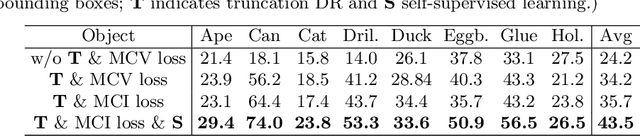
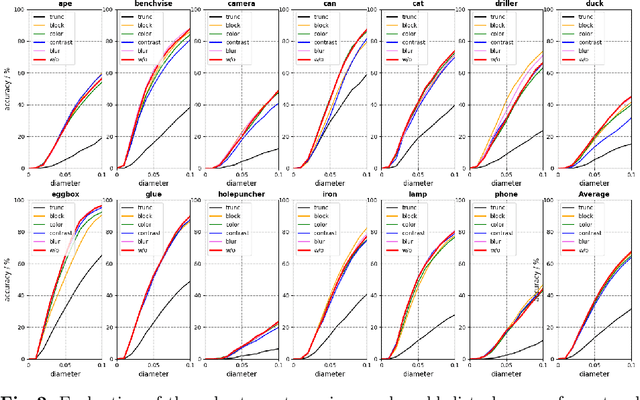

While much progress has been made in 6-DoF object pose estimation from a single RGB image, the current leading approaches heavily rely on real-annotation data. As such, they remain sensitive to severe occlusions, because covering all possible occlusions with annotated data is intractable. In this paper, we introduce an approach to robustly and accurately estimate the 6-DoF pose in challenging conditions and without using any real pose annotations. To this end, we leverage the intuition that the poses predicted by a network from an image and from its counterpart synthetically altered to mimic occlusion should be consistent, and translate this to a self-supervised loss function. Our experiments on LINEMOD, Occluded-LINEMOD, YCB and new Randomization LINEMOD dataset evidence the robustness of our approach. We achieve state of the art performance on LINEMOD, and OccludedLINEMOD in without real-pose setting, even outperforming methods that rely on real annotations during training on Occluded-LINEMOD.