 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Cross-Domain Few-Shot Object Detection: Methods and Results
Apr 14, 2025Cross-Domain Few-Shot Object Detection (CD-FSOD) poses significant challenges to existing object detection and few-shot detection models when applied across domains. In conjunction with NTIRE 2025, we organized the 1st CD-FSOD Challenge, aiming to advance the performance of current object detectors on entirely novel target domains with only limited labeled data. The challenge attracted 152 registered participants, received submissions from 42 teams, and concluded with 13 teams making valid final submissions. Participants approached the task from diverse perspectives, proposing novel models that achieved new state-of-the-art (SOTA) results under both open-source and closed-source settings. In this report, we present an overview of the 1st NTIRE 2025 CD-FSOD Challenge, highlighting the proposed solutions and summarizing the results submitted by the participants.
SVasP: Self-Versatility Adversarial Style Perturbation for Cross-Domain Few-Shot Learning
Dec 12, 2024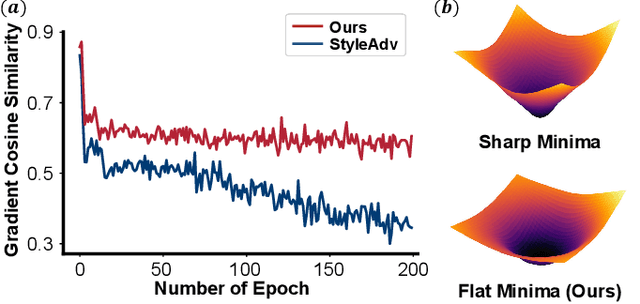

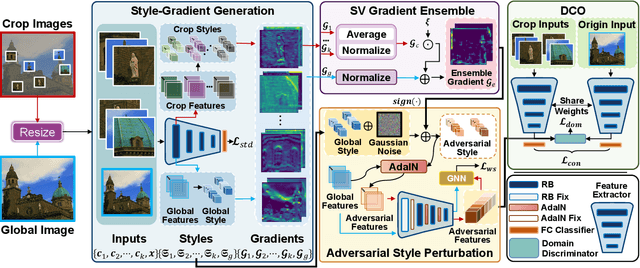

Cross-Domain Few-Shot Learning (CD-FSL) aims to transfer knowledge from seen source domains to unseen target domains, which is crucial for evaluating the generalization and robustness of models. Recent studies focus on utilizing visual styles to bridge the domain gap between different domains. However, the serious dilemma of gradient instability and local optimization problem occurs in those style-based CD-FSL methods. This paper addresses these issues and proposes a novel crop-global style perturbation method, called \underline{\textbf{S}}elf-\underline{\textbf{V}}ersatility \underline{\textbf{A}}dversarial \underline{\textbf{S}}tyle \underline{\textbf{P}}erturbation (\textbf{SVasP}), which enhances the gradient stability and escapes from poor sharp minima jointly. Specifically, SVasP simulates more diverse potential target domain adversarial styles via diversifying input patterns and aggregating localized crop style gradients, to serve as global style perturbation stabilizers within one image, a concept we refer to as self-versatility. Then a novel objective function is proposed to maximize visual discrepancy while maintaining semantic consistency between global, crop, and adversarial features. Having the stabilized global style perturbation in the training phase, one can obtain a flattened minima in the loss landscape, boosting the transferability of the model to the target domains. Extensive experiments on multiple benchmark datasets demonstrate that our method significantly outperforms existing state-of-the-art methods. Our codes are available at https://github.com/liwenqianSEU/SVasP.
Multimodal Misinformation Detection by Learning from Synthetic Data with Multimodal LLMs
Sep 29, 2024
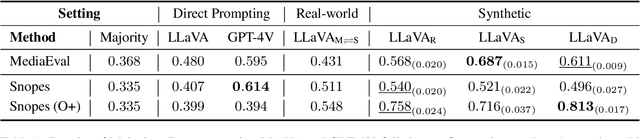
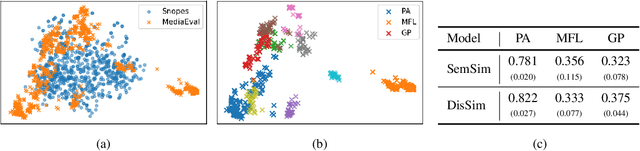
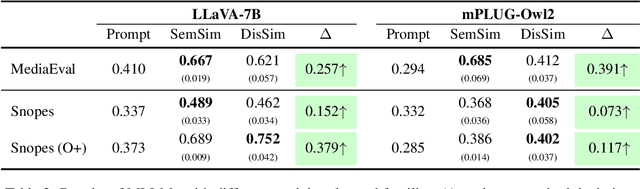
Detecting multimodal misinformation, especially in the form of image-text pairs, is crucial. Obtaining large-scale, high-quality real-world fact-checking datasets for training detectors is costly, leading researchers to use synthetic datasets generated by AI technologies. However, the generalizability of detectors trained on synthetic data to real-world scenarios remains unclear due to the distribution gap. To address this, we propose learning from synthetic data for detecting real-world multimodal misinformation through two model-agnostic data selection methods that match synthetic and real-world data distributions. Experiments show that our method enhances the performance of a small MLLM (13B) on real-world fact-checking datasets, enabling it to even surpass GPT-4V~\cite{GPT-4V}.
Towards Few-Shot Learning in the Open World: A Review and Beyond
Aug 19, 2024



Human intelligence is characterized by our ability to absorb and apply knowledge from the world around us, especially in rapidly acquiring new concepts from minimal examples, underpinned by prior knowledge. Few-shot learning (FSL) aims to mimic this capacity by enabling significant generalizations and transferability. However, traditional FSL frameworks often rely on assumptions of clean, complete, and static data, conditions that are seldom met in real-world environments. Such assumptions falter in the inherently uncertain, incomplete, and dynamic contexts of the open world. This paper presents a comprehensive review of recent advancements designed to adapt FSL for use in open-world settings. We categorize existing methods into three distinct types of open-world few-shot learning: those involving varying instances, varying classes, and varying distributions. Each category is discussed in terms of its specific challenges and methods, as well as its strengths and weaknesses. We standardize experimental settings and metric benchmarks across scenarios, and provide a comparative analysis of the performance of various methods. In conclusion, we outline potential future research directions for this evolving field. It is our hope that this review will catalyze further development of effective solutions to these complex challenges, thereby advancing the field of artificial intelligence.
Private Wasserstein Distance with Random Noises
Apr 10, 2024Wasserstein distance is a principle measure of data divergence from a distributional standpoint. However, its application becomes challenging in the context of data privacy, where sharing raw data is restricted. Prior attempts have employed techniques like Differential Privacy or Federated optimization to approximate Wasserstein distance. Nevertheless, these approaches often lack accuracy and robustness against potential attack. In this study, we investigate the underlying triangular properties within the Wasserstein space, leading to a straightforward solution named TriangleWad. This approach enables the computation of Wasserstein distance between datasets stored across different entities. Notably, TriangleWad is 20 times faster, making raw data information truly invisible, enhancing resilience against attacks, and without sacrificing estimation accuracy. Through comprehensive experimentation across various tasks involving both image and text data, we demonstrate its superior performance and generalizations.
Teach Large Language Models to Forget Privacy
Dec 30, 2023



Large Language Models (LLMs) have proven powerful, but the risk of privacy leakage remains a significant concern. Traditional privacy-preserving methods, such as Differential Privacy and Homomorphic Encryption, are inadequate for black-box API-only settings, demanding either model transparency or heavy computational resources. We propose Prompt2Forget (P2F), the first framework designed to tackle the LLM local privacy challenge by teaching LLM to forget. The method involves decomposing full questions into smaller segments, generating fabricated answers, and obfuscating the model's memory of the original input. A benchmark dataset was crafted with questions containing privacy-sensitive information from diverse fields. P2F achieves zero-shot generalization, allowing adaptability across a wide range of use cases without manual adjustments. Experimental results indicate P2F's robust capability to obfuscate LLM's memory, attaining a forgetfulness score of around 90\% without any utility loss. This represents an enhancement of up to 63\% when contrasted with the naive direct instruction technique, highlighting P2F's efficacy in mitigating memory retention of sensitive information within LLMs. Our findings establish the first benchmark in the novel field of the LLM forgetting task, representing a meaningful advancement in privacy preservation in the emerging LLM domain.
Data Valuation and Detections in Federated Learning
Nov 13, 2023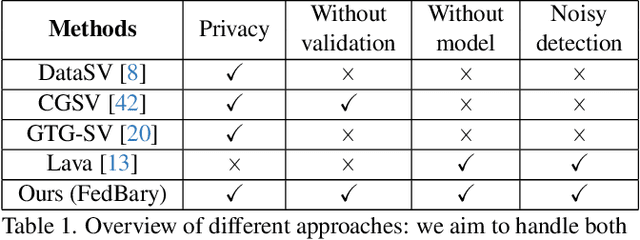
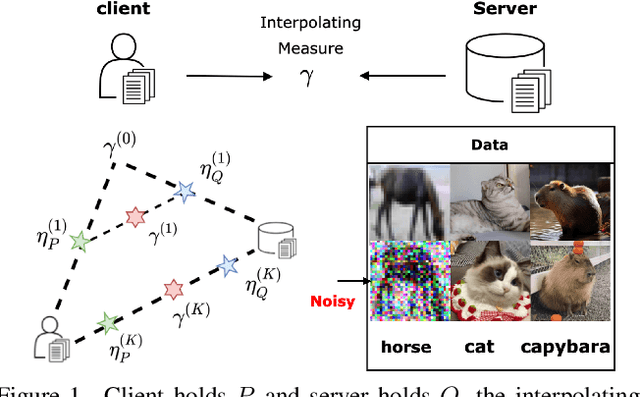
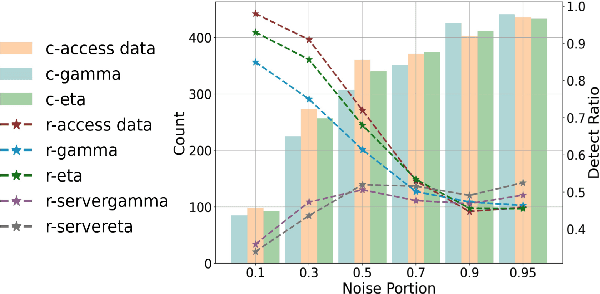
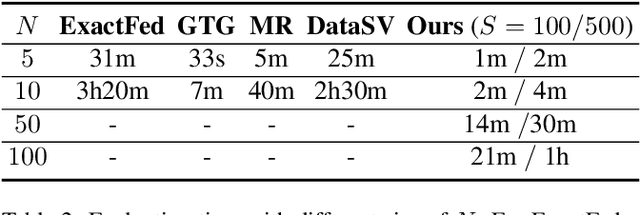
Federated Learning (FL) enables collaborative model training while preserving the privacy of raw data. A challenge in this framework is the fair and efficient valuation of data, which is crucial for incentivizing clients to contribute high-quality data in the FL task. In scenarios involving numerous data clients within FL, it is often the case that only a subset of clients and datasets are pertinent to a specific learning task, while others might have either a negative or negligible impact on the model training process. This paper introduces a novel privacy-preserving method for evaluating client contributions and selecting relevant datasets without a pre-specified training algorithm in an FL task. Our proposed approach FedBary, utilizes Wasserstein distance within the federated context, offering a new solution for data valuation in the FL framework. This method ensures transparent data valuation and efficient computation of the Wasserstein barycenter and reduces the dependence on validation datasets. Through extensive empirical experiments and theoretical analyses, we demonstrate the potential of this data valuation method as a promising avenue for FL research.
Genes in Intelligent Agents
Jun 17, 2023Training intelligent agents in Reinforcement Learning (RL) is much more time-consuming than animal learning. This is because agents learn from scratch, but animals learn with genes inherited from ancestors and are born with some innate abilities. Inspired by genes in animals, here we conceptualize the gene in intelligent agents and introduce Genetic Reinforcement Learning (GRL), a computational framework to represent, evaluate, and evolve genes (in agents). Leveraging GRL we identify genes and demonstrate several advantages of genes. First, we find that genes take the form of the fragment of agents' neural networks and can be inherited across generations. Second, we validate that genes bring better and stabler learning ability to agents, since genes condense knowledge from ancestors and bring agent with innate abilities. Third, we present evidence of Lamarckian evolution in intelligent agents. The continuous encoding of knowledge into genes across generations facilitates the evolution of genes. Overall, our work promotes a novel paradigm to train agents by incorporating genes.
Generative Flow Networks for Precise Reward-Oriented Active Learning on Graphs
Apr 24, 2023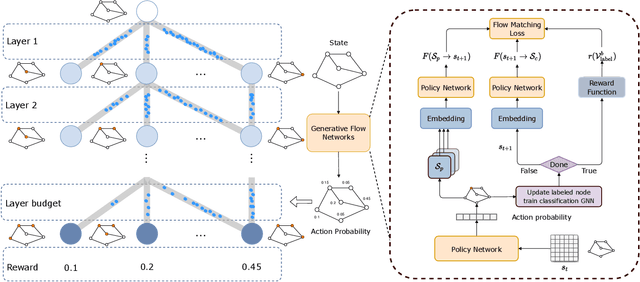
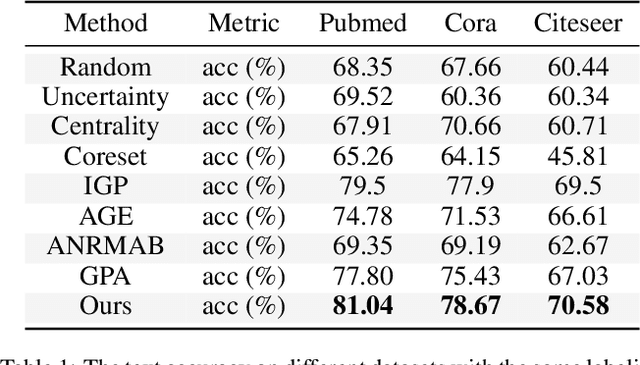
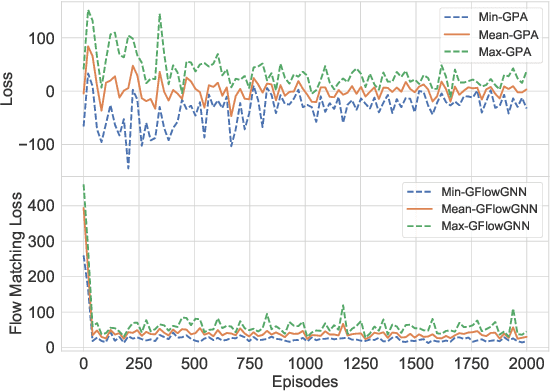
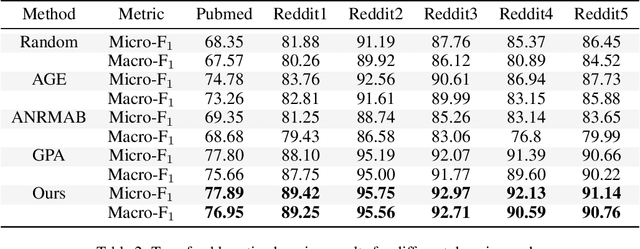
Many score-based active learning methods have been successfully applied to graph-structured data, aiming to reduce the number of labels and achieve better performance of graph neural networks based on predefined score functions. However, these algorithms struggle to learn policy distributions that are proportional to rewards and have limited exploration capabilities. In this paper, we innovatively formulate the graph active learning problem as a generative process, named GFlowGNN, which generates various samples through sequential actions with probabilities precisely proportional to a predefined reward function. Furthermore, we propose the concept of flow nodes and flow features to efficiently model graphs as flows based on generative flow networks, where the policy network is trained with specially designed rewards. Extensive experiments on real datasets show that the proposed approach has good exploration capability and transferability, outperforming various state-of-the-art methods.
DAG Matters! GFlowNets Enhanced Explainer For Graph Neural Networks
Mar 04, 2023



Uncovering rationales behind predictions of graph neural networks (GNNs) has received increasing attention over the years. Existing literature mainly focus on selecting a subgraph, through combinatorial optimization, to provide faithful explanations. However, the exponential size of candidate subgraphs limits the applicability of state-of-the-art methods to large-scale GNNs. We enhance on this through a different approach: by proposing a generative structure -- GFlowNets-based GNN Explainer (GFlowExplainer), we turn the optimization problem into a step-by-step generative problem. Our GFlowExplainer aims to learn a policy that generates a distribution of subgraphs for which the probability of a subgraph is proportional to its' reward. The proposed approach eliminates the influence of node sequence and thus does not need any pre-training strategies. We also propose a new cut vertex matrix to efficiently explore parent states for GFlowNets structure, thus making our approach applicable in a large-scale setting. We conduct extensive experiments on both synthetic and real datasets, and both qualitative and quantitative results show the superiority of our GFlowExplainer.