 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Sep 17, 2025
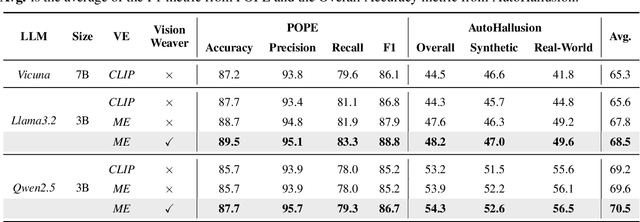
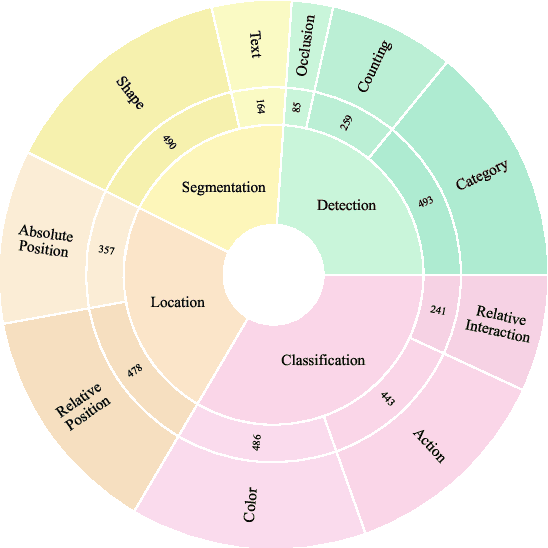
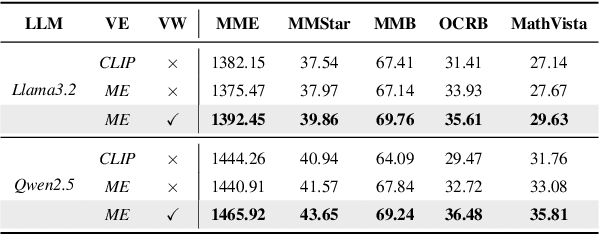
Object hallucination in Large Vision-Language Models (LVLMs) significantly impedes their real-world applicability. As the primary component for accurately interpreting visual information, the choice of visual encoder is pivotal. We hypothesize that the diverse training paradigms employed by different visual encoders instill them with distinct inductive biases, which leads to their diverse hallucination performances. Existing benchmarks typically focus on coarse-grained hallucination detection and fail to capture the diverse hallucinations elaborated in our hypothesis. To systematically analyze these effects, we introduce VHBench-10, a comprehensive benchmark with approximately 10,000 samples for evaluating LVLMs across ten fine-grained hallucination categories. Our evaluations confirm encoders exhibit unique hallucination characteristics. Building on these insights and the suboptimality of simple feature fusion, we propose VisionWeaver, a novel Context-Aware Routing Network. It employs global visual features to generate routing signals, dynamically aggregating visual features from multiple specialized experts. Comprehensive experiments confirm the effectiveness of VisionWeaver in significantly reducing hallucinations and improving overall model performance.
Paladin: Defending LLM-enabled Phishing Emails with a New Trigger-Tag Paradigm
Sep 08, 2025With the rapid development of large language models, the potential threat of their malicious use, particularly in generating phishing content, is becoming increasingly prevalent. Leveraging the capabilities of LLMs, malicious users can synthesize phishing emails that are free from spelling mistakes and other easily detectable features. Furthermore, such models can generate topic-specific phishing messages, tailoring content to the target domain and increasing the likelihood of success. Detecting such content remains a significant challenge, as LLM-generated phishing emails often lack clear or distinguishable linguistic features. As a result, most existing semantic-level detection approaches struggle to identify them reliably. While certain LLM-based detection methods have shown promise, they suffer from high computational costs and are constrained by the performance of the underlying language model, making them impractical for large-scale deployment. In this work, we aim to address this issue. We propose Paladin, which embeds trigger-tag associations into vanilla LLM using various insertion strategies, creating them into instrumented LLMs. When an instrumented LLM generates content related to phishing, it will automatically include detectable tags, enabling easier identification. Based on the design on implicit and explicit triggers and tags, we consider four distinct scenarios in our work. We evaluate our method from three key perspectives: stealthiness, effectiveness, and robustness, and compare it with existing baseline methods. Experimental results show that our method outperforms the baselines, achieving over 90% detection accuracy across all scenarios.
MCM: Mamba-based Cardiac Motion Tracking using Sequential Images in MRI
Jul 23, 2025Myocardial motion tracking is important for assessing cardiac function and diagnosing cardiovascular diseases, for which cine cardiac magnetic resonance (CMR) has been established as the gold standard imaging modality. Many existing methods learn motion from single image pairs consisting of a reference frame and a randomly selected target frame from the cardiac cycle. However, these methods overlook the continuous nature of cardiac motion and often yield inconsistent and non-smooth motion estimations. In this work, we propose a novel Mamba-based cardiac motion tracking network (MCM) that explicitly incorporates target image sequence from the cardiac cycle to achieve smooth and temporally consistent motion tracking. By developing a bi-directional Mamba block equipped with a bi-directional scanning mechanism, our method facilitates the estimation of plausible deformation fields. With our proposed motion decoder that integrates motion information from frames adjacent to the target frame, our method further enhances temporal coherence. Moreover, by taking advantage of Mamba's structured state-space formulation, the proposed method learns the continuous dynamics of the myocardium from sequential images without increasing computational complexity. We evaluate the proposed method on two public datasets. The experimental results demonstrate that the proposed method quantitatively and qualitatively outperforms both conventional and state-of-the-art learning-based cardiac motion tracking methods. The code is available at https://github.com/yjh-0104/MCM.
Multimodal Misinformation Detection by Learning from Synthetic Data with Multimodal LLMs
Sep 29, 2024
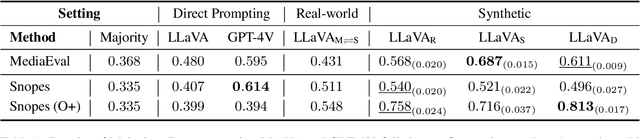
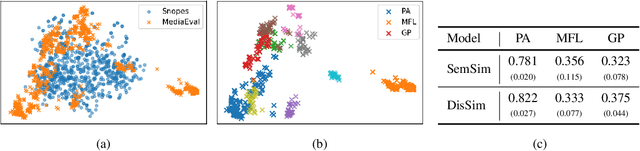
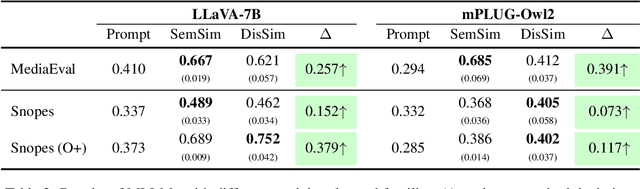
Detecting multimodal misinformation, especially in the form of image-text pairs, is crucial. Obtaining large-scale, high-quality real-world fact-checking datasets for training detectors is costly, leading researchers to use synthetic datasets generated by AI technologies. However, the generalizability of detectors trained on synthetic data to real-world scenarios remains unclear due to the distribution gap. To address this, we propose learning from synthetic data for detecting real-world multimodal misinformation through two model-agnostic data selection methods that match synthetic and real-world data distributions. Experiments show that our method enhances the performance of a small MLLM (13B) on real-world fact-checking datasets, enabling it to even surpass GPT-4V~\cite{GPT-4V}.
Towards Understanding Unsafe Video Generation
Jul 17, 2024Video generation models (VGMs) have demonstrated the capability to synthesize high-quality output. It is important to understand their potential to produce unsafe content, such as violent or terrifying videos. In this work, we provide a comprehensive understanding of unsafe video generation. First, to confirm the possibility that these models could indeed generate unsafe videos, we choose unsafe content generation prompts collected from 4chan and Lexica, and three open-source SOTA VGMs to generate unsafe videos. After filtering out duplicates and poorly generated content, we created an initial set of 2112 unsafe videos from an original pool of 5607 videos. Through clustering and thematic coding analysis of these generated videos, we identify 5 unsafe video categories: Distorted/Weird, Terrifying, Pornographic, Violent/Bloody, and Political. With IRB approval, we then recruit online participants to help label the generated videos. Based on the annotations submitted by 403 participants, we identified 937 unsafe videos from the initial video set. With the labeled information and the corresponding prompts, we created the first dataset of unsafe videos generated by VGMs. We then study possible defense mechanisms to prevent the generation of unsafe videos. Existing defense methods in image generation focus on filtering either input prompt or output results. We propose a new approach called Latent Variable Defense (LVD), which works within the model's internal sampling process. LVD can achieve 0.90 defense accuracy while reducing time and computing resources by 10x when sampling a large number of unsafe prompts.
RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation
May 24, 2024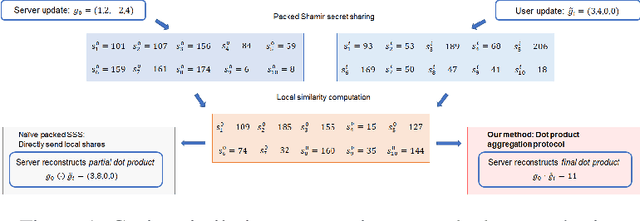

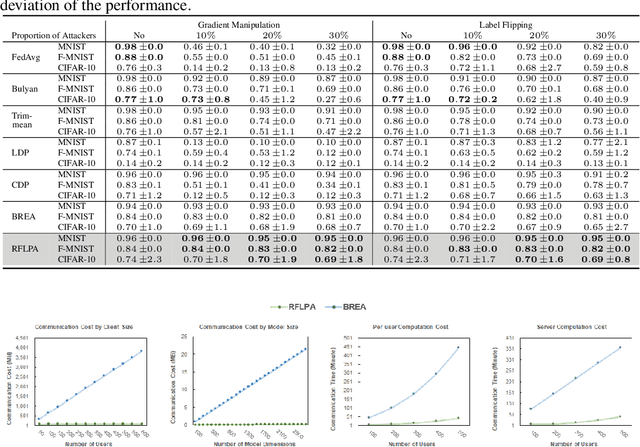
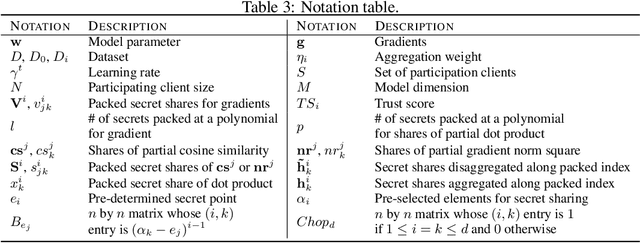
Federated learning (FL) allows multiple devices to train a model collaboratively without sharing their data. Despite its benefits, FL is vulnerable to privacy leakage and poisoning attacks. To address the privacy concern, secure aggregation (SecAgg) is often used to obtain the aggregation of gradients on sever without inspecting individual user updates. Unfortunately, existing defense strategies against poisoning attacks rely on the analysis of local updates in plaintext, making them incompatible with SecAgg. To reconcile the conflicts, we propose a robust federated learning framework against poisoning attacks (RFLPA) based on SecAgg protocol. Our framework computes the cosine similarity between local updates and server updates to conduct robust aggregation. Furthermore, we leverage verifiable packed Shamir secret sharing to achieve reduced communication cost of $O(M+N)$ per user, and design a novel dot-product aggregation algorithm to resolve the issue of increased information leakage. Our experimental results show that RFLPA significantly reduces communication and computation overhead by over $75\%$ compared to the state-of-the-art method, BREA, while maintaining competitive accuracy.
Private Wasserstein Distance with Random Noises
Apr 10, 2024Wasserstein distance is a principle measure of data divergence from a distributional standpoint. However, its application becomes challenging in the context of data privacy, where sharing raw data is restricted. Prior attempts have employed techniques like Differential Privacy or Federated optimization to approximate Wasserstein distance. Nevertheless, these approaches often lack accuracy and robustness against potential attack. In this study, we investigate the underlying triangular properties within the Wasserstein space, leading to a straightforward solution named TriangleWad. This approach enables the computation of Wasserstein distance between datasets stored across different entities. Notably, TriangleWad is 20 times faster, making raw data information truly invisible, enhancing resilience against attacks, and without sacrificing estimation accuracy. Through comprehensive experimentation across various tasks involving both image and text data, we demonstrate its superior performance and generalizations.
VGMShield: Mitigating Misuse of Video Generative Models
Feb 20, 2024With the rapid advancement in video generation, people can conveniently utilize video generation models to create videos tailored to their specific desires. Nevertheless, there are also growing concerns about their potential misuse in creating and disseminating false information. In this work, we introduce VGMShield: a set of three straightforward but pioneering mitigations through the lifecycle of fake video generation. We start from \textit{fake video detection} trying to understand whether there is uniqueness in generated videos and whether we can differentiate them from real videos; then, we investigate the \textit{tracing} problem, which maps a fake video back to a model that generates it. Towards these, we propose to leverage pre-trained models that focus on {\it spatial-temporal dynamics} as the backbone to identify inconsistencies in videos. Through experiments on seven state-of-the-art open-source models, we demonstrate that current models still cannot perfectly handle spatial-temporal relationships, and thus, we can accomplish detection and tracing with nearly perfect accuracy. Furthermore, anticipating future generative model improvements, we propose a {\it prevention} method that adds invisible perturbations to images to make the generated videos look unreal. Together with fake video detection and tracing, our multi-faceted set of solutions can effectively mitigate misuse of video generative models.
Teach Large Language Models to Forget Privacy
Dec 30, 2023



Large Language Models (LLMs) have proven powerful, but the risk of privacy leakage remains a significant concern. Traditional privacy-preserving methods, such as Differential Privacy and Homomorphic Encryption, are inadequate for black-box API-only settings, demanding either model transparency or heavy computational resources. We propose Prompt2Forget (P2F), the first framework designed to tackle the LLM local privacy challenge by teaching LLM to forget. The method involves decomposing full questions into smaller segments, generating fabricated answers, and obfuscating the model's memory of the original input. A benchmark dataset was crafted with questions containing privacy-sensitive information from diverse fields. P2F achieves zero-shot generalization, allowing adaptability across a wide range of use cases without manual adjustments. Experimental results indicate P2F's robust capability to obfuscate LLM's memory, attaining a forgetfulness score of around 90\% without any utility loss. This represents an enhancement of up to 63\% when contrasted with the naive direct instruction technique, highlighting P2F's efficacy in mitigating memory retention of sensitive information within LLMs. Our findings establish the first benchmark in the novel field of the LLM forgetting task, representing a meaningful advancement in privacy preservation in the emerging LLM domain.
Data Valuation and Detections in Federated Learning
Nov 13, 2023
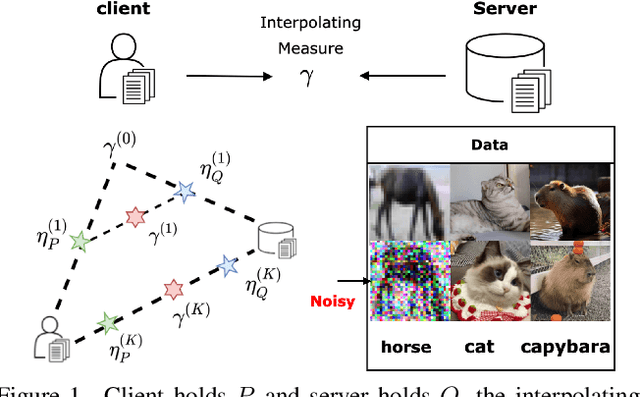
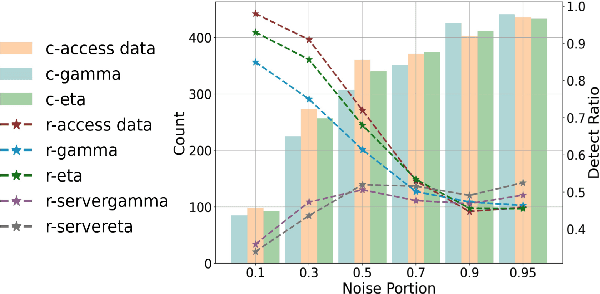
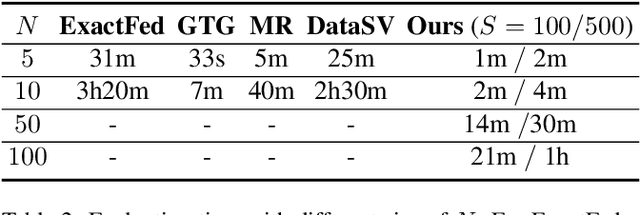
Federated Learning (FL) enables collaborative model training while preserving the privacy of raw data. A challenge in this framework is the fair and efficient valuation of data, which is crucial for incentivizing clients to contribute high-quality data in the FL task. In scenarios involving numerous data clients within FL, it is often the case that only a subset of clients and datasets are pertinent to a specific learning task, while others might have either a negative or negligible impact on the model training process. This paper introduces a novel privacy-preserving method for evaluating client contributions and selecting relevant datasets without a pre-specified training algorithm in an FL task. Our proposed approach FedBary, utilizes Wasserstein distance within the federated context, offering a new solution for data valuation in the FL framework. This method ensures transparent data valuation and efficient computation of the Wasserstein barycenter and reduces the dependence on validation datasets. Through extensive empirical experiments and theoretical analyses, we demonstrate the potential of this data valuation method as a promising avenue for FL research.