 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit-and-Denoise: Protect large language model inference with local differential privacy
Oct 13, 2023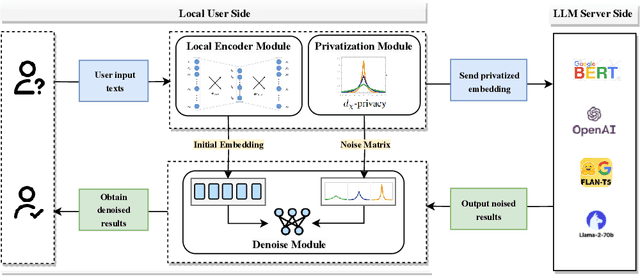
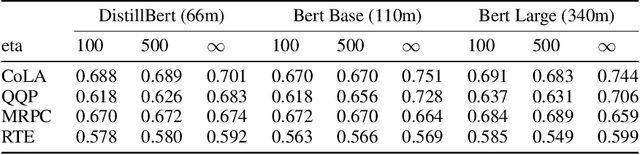
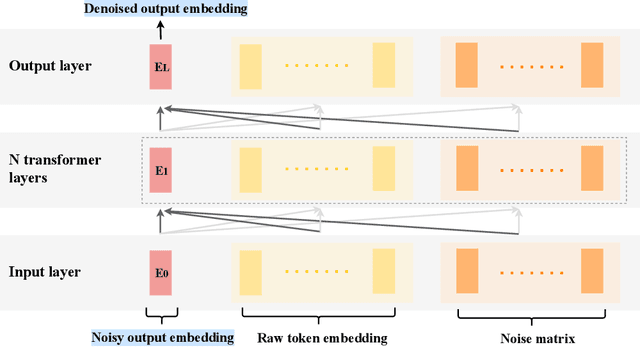

Large Language Models (LLMs) shows powerful capability in natural language understanding by capturing hidden semantics in vector space. This process enriches the value of the text embeddings for various downstream tasks, thereby fostering the Embedding-as-a-Service (EaaS) business model. However, the direct transmission of text to servers poses a largely unaddressed risk of privacy leakage. To mitigate this issue, we introduce Split-N-Denoise (SnD), an innovative framework that split the model to execute the token embedding layer on the client side at minimal computational cost. This allows the client to introduce noise prior to transmitting the embeddings to the server, and subsequently receive and denoise the perturbed output embeddings for downstream tasks. Our approach is designed for the inference stage of LLMs and requires no modifications to the model parameters. Extensive experiments demonstrate SnD's effectiveness in optimizing the privacy-utility tradeoff across various LLM architectures and diverse downstream tasks. The results reveal a significant performance improvement under the same privacy budget compared to the baseline, offering clients a privacy-preserving solution for local privacy protection.