 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD^2SD: Accelerating Speculative Decoding with Dual Diffusion Draft Models
Jun 03, 2026Speculative decoding accelerates autoregressive large language model inference by drafting multiple tokens and verifying them in a single target-model forward pass. Recent diffusion-based drafters generate an entire block of tokens in parallel but usually commit to a single draft sequence per verification: once the first mismatch occurs, all subsequent draft tokens are discarded, resulting in a limited acceptance rate. Naively batching more draft candidate sequences only introduces a marginal improvement, as redundant or poorly placed branches increase the cost of drafting and verification without proportionally increasing the number of accepted tokens. We propose D^2SD, a dual diffusion draft speculative decoding framework that organizes candidates into a confidence-guided prefix tree, where the first diffusion drafter generates a block along with per-position confidence scores that are used to identify the most likely rejection boundary and select the top-K prefix ranges for recovery; the second variable-prefix diffusion drafter re-anchors at each selected prefix and proposes alternative continuations in one batched pass; the resulting shared-prefix candidates are jointly verified via cascade attention. Empirically, D^2SD shows clear improvements over both the underlying diffusion approach and strong autoregressive speculative decoding baselines.
AREAL-DTA: Dynamic Tree Attention for Efficient Reinforcement Learning of Large Language Models
Jan 31, 2026Reinforcement learning (RL) based post-training for large language models (LLMs) is computationally expensive, as it generates many rollout sequences that could frequently share long token prefixes. Existing RL frameworks usually process these sequences independently, repeatedly recomputing identical prefixes during forward and backward passes during policy model training, leading to substantial inefficiencies in computation and memory usage. Although prefix sharing naturally induces a tree structure over rollouts, prior tree-attention-based solutions rely on fully materialized attention masks and scale poorly in RL settings. In this paper, we introduce AREAL-DTA to efficiently exploit prefix sharing in RL training. AREAL-DTA employs a depth-first-search (DFS)-based execution strategy that dynamically traverses the rollout prefix tree during both forward and backward computation, materializing only a single root-to-leaf path at a time. To further improve scalability, AREAL-DTA incorporates a load-balanced distributed batching mechanism that dynamically constructs and processes prefix trees across multiple GPUs. Across the popular RL post-training workload, AREAL-DTA achieves up to $8.31\times$ in $τ^2$-bench higher training throughput.
A Unified Model for Multi-Task Drone Routing in Post-Disaster Road Assessment
Oct 24, 2025Post-disaster road assessment (PDRA) is essential for emergency response, enabling rapid evaluation of infrastructure conditions and efficient allocation of resources. Although drones provide a flexible and effective tool for PDRA, routing them in large-scale networks remains challenging. Traditional optimization methods scale poorly and demand domain expertise, while existing deep reinforcement learning (DRL) approaches adopt a single-task paradigm, requiring separate models for each problem variant and lacking adaptability to evolving operational needs. This study proposes a unified model (UM) for drone routing that simultaneously addresses eight PDRA variants. By training a single neural network across multiple problem configurations, UM captures shared structural knowledge while adapting to variant-specific constraints through a modern transformer encoder-decoder architecture. A lightweight adapter mechanism further enables efficient finetuning to unseen attributes without retraining, enhancing deployment flexibility in dynamic disaster scenarios. Extensive experiments demonstrate that the UM reduces training time and parameters by a factor of eight compared with training separate models, while consistently outperforming single-task DRL methods by 6--14\% and traditional optimization approaches by 24--82\% in terms of solution quality (total collected information value). The model achieves real-time solutions (1--10 seconds) across networks of up to 1,000 nodes, with robustness confirmed through sensitivity analyses. Moreover, finetuning experiments show that unseen attributes can be effectively incorporated with minimal cost while retaining high solution quality. The proposed UM advances neural combinatorial optimization for time-critical applications, offering a computationally efficient, high-quality, and adaptable solution for drone-based PDRA.
Flash Sparse Attention: An Alternative Efficient Implementation of Native Sparse Attention Kernel
Aug 25, 2025Recent progress in sparse attention mechanisms has demonstrated strong potential for reducing the computational cost of long-context training and inference in large language models (LLMs). Native Sparse Attention (NSA), a state-of-the-art approach, introduces natively trainable, hardware-aligned sparse attention that delivers substantial system-level performance gains while maintaining accuracy comparable to full attention. However, the kernel implementation of NSA relies on a query-grouping strategy that is efficient only with large Grouped Query Attention (GQA) sizes, whereas modern LLMs typically adopt much smaller GQA groups, which limits the applicability of this sparse algorithmic advance. In this work, we propose Flash Sparse Attention (FSA), which includes an alternative kernel design that enables efficient NSA computation across a wide range of popular LLMs with varied smaller GQA group sizes on modern GPUs. Compared to vanilla NSA kernel implementation, our empirical evaluation demonstrates that FSA achieves (i) up to 3.5$\times$ and on average 1.6$\times$ kernel-level latency reduction, (ii) up to 1.25$\times$ and 1.09$\times$ on average end-to-end training speedup on state-of-the-art LLMs, and (iii) up to 1.36$\times$ and 1.11$\times$ on average end-to-end prefill speedup on state-of-the-art LLMs. The source code is open-sourced and publicly available at https://github.com/Relaxed-System-Lab/Flash-Sparse-Attention.
Oblivionis: A Lightweight Learning and Unlearning Framework for Federated Large Language Models
Aug 12, 2025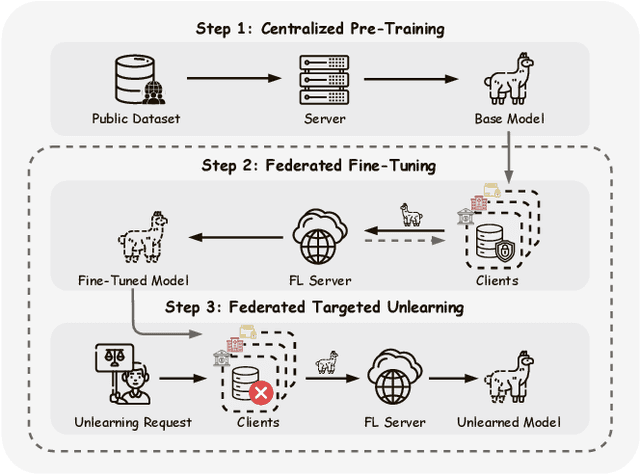
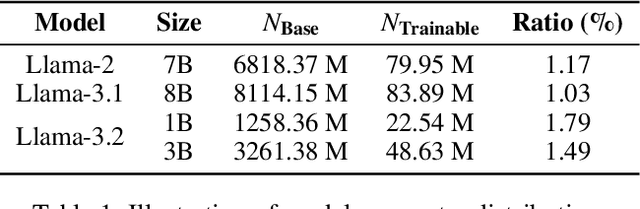
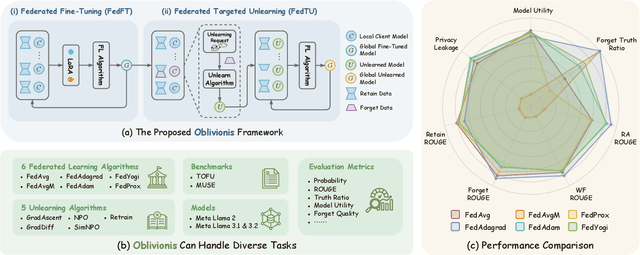
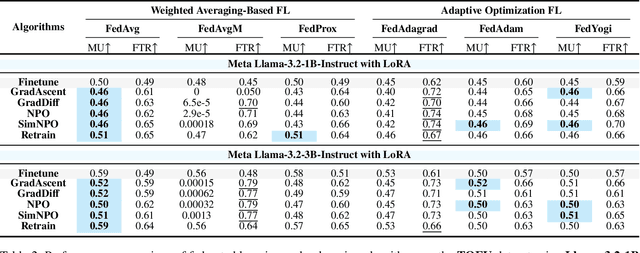
Large Language Models (LLMs) increasingly leverage Federated Learning (FL) to utilize private, task-specific datasets for fine-tuning while preserving data privacy. However, while federated LLM frameworks effectively enable collaborative training without raw data sharing, they critically lack built-in mechanisms for regulatory compliance like GDPR's right to be forgotten. Integrating private data heightens concerns over data quality and long-term governance, yet existing distributed training frameworks offer no principled way to selectively remove specific client contributions post-training. Due to distributed data silos, stringent privacy constraints, and the intricacies of interdependent model aggregation, federated LLM unlearning is significantly more complex than centralized LLM unlearning. To address this gap, we introduce Oblivionis, a lightweight learning and unlearning framework that enables clients to selectively remove specific private data during federated LLM training, enhancing trustworthiness and regulatory compliance. By unifying FL and unlearning as a dual optimization objective, we incorporate 6 FL and 5 unlearning algorithms for comprehensive evaluation and comparative analysis, establishing a robust pipeline for federated LLM unlearning. Extensive experiments demonstrate that Oblivionis outperforms local training, achieving a robust balance between forgetting efficacy and model utility, with cross-algorithm comparisons providing clear directions for future LLM development.
MSD-LLM: Predicting Ship Detention in Port State Control Inspections with Large Language Model
May 26, 2025Maritime transportation is the backbone of global trade, making ship inspection essential for ensuring maritime safety and environmental protection. Port State Control (PSC), conducted by national ports, enforces compliance with safety regulations, with ship detention being the most severe consequence, impacting both ship schedules and company reputations. Traditional machine learning methods for ship detention prediction are limited by the capacity of representation learning and thus suffer from low accuracy. Meanwhile, autoencoder-based deep learning approaches face challenges due to the severe data imbalance in learning historical PSC detention records. To address these limitations, we propose Maritime Ship Detention with Large Language Models (MSD-LLM), integrating a dual robust subspace recovery (DSR) layer-based autoencoder with a progressive learning pipeline to handle imbalanced data and extract meaningful PSC representations. Then, a large language model groups and ranks features to identify likely detention cases, enabling dynamic thresholding for flexible detention predictions. Extensive evaluations on 31,707 PSC inspection records from the Asia-Pacific region show that MSD-LLM outperforms state-of-the-art methods more than 12\% on Area Under the Curve (AUC) for Singapore ports. Additionally, it demonstrates robustness to real-world challenges, making it adaptable to diverse maritime risk assessment scenarios.
Reducing Distraction in Long-Context Language Models by Focused Learning
Nov 08, 2024



Recent advancements in Large Language Models (LLMs) have significantly enhanced their capacity to process long contexts. However, effectively utilizing this long context remains a challenge due to the issue of distraction, where irrelevant information dominates lengthy contexts, causing LLMs to lose focus on the most relevant segments. To address this, we propose a novel training method that enhances LLMs' ability to discern relevant information through a unique combination of retrieval-based data augmentation and contrastive learning. Specifically, during fine-tuning with long contexts, we employ a retriever to extract the most relevant segments, serving as augmented inputs. We then introduce an auxiliary contrastive learning objective to explicitly ensure that outputs from the original context and the retrieved sub-context are closely aligned. Extensive experiments on long single-document and multi-document QA benchmarks demonstrate the effectiveness of our proposed method.
RFLPA: A Robust Federated Learning Framework against Poisoning Attacks with Secure Aggregation
May 24, 2024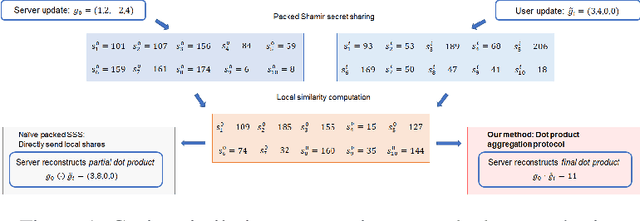

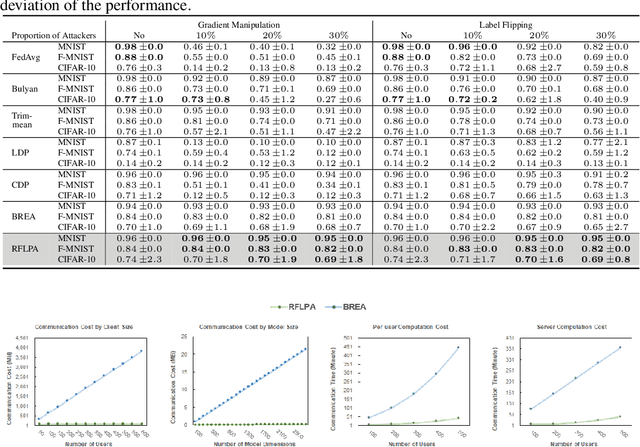
Federated learning (FL) allows multiple devices to train a model collaboratively without sharing their data. Despite its benefits, FL is vulnerable to privacy leakage and poisoning attacks. To address the privacy concern, secure aggregation (SecAgg) is often used to obtain the aggregation of gradients on sever without inspecting individual user updates. Unfortunately, existing defense strategies against poisoning attacks rely on the analysis of local updates in plaintext, making them incompatible with SecAgg. To reconcile the conflicts, we propose a robust federated learning framework against poisoning attacks (RFLPA) based on SecAgg protocol. Our framework computes the cosine similarity between local updates and server updates to conduct robust aggregation. Furthermore, we leverage verifiable packed Shamir secret sharing to achieve reduced communication cost of $O(M+N)$ per user, and design a novel dot-product aggregation algorithm to resolve the issue of increased information leakage. Our experimental results show that RFLPA significantly reduces communication and computation overhead by over $75\%$ compared to the state-of-the-art method, BREA, while maintaining competitive accuracy.
Teach Large Language Models to Forget Privacy
Dec 30, 2023



Large Language Models (LLMs) have proven powerful, but the risk of privacy leakage remains a significant concern. Traditional privacy-preserving methods, such as Differential Privacy and Homomorphic Encryption, are inadequate for black-box API-only settings, demanding either model transparency or heavy computational resources. We propose Prompt2Forget (P2F), the first framework designed to tackle the LLM local privacy challenge by teaching LLM to forget. The method involves decomposing full questions into smaller segments, generating fabricated answers, and obfuscating the model's memory of the original input. A benchmark dataset was crafted with questions containing privacy-sensitive information from diverse fields. P2F achieves zero-shot generalization, allowing adaptability across a wide range of use cases without manual adjustments. Experimental results indicate P2F's robust capability to obfuscate LLM's memory, attaining a forgetfulness score of around 90\% without any utility loss. This represents an enhancement of up to 63\% when contrasted with the naive direct instruction technique, highlighting P2F's efficacy in mitigating memory retention of sensitive information within LLMs. Our findings establish the first benchmark in the novel field of the LLM forgetting task, representing a meaningful advancement in privacy preservation in the emerging LLM domain.
Split-and-Denoise: Protect large language model inference with local differential privacy
Oct 13, 2023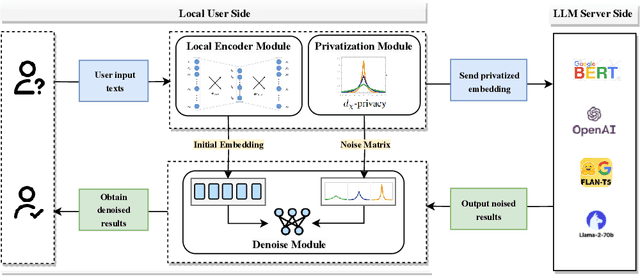
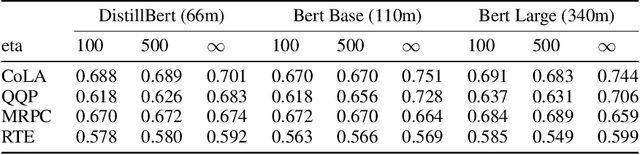
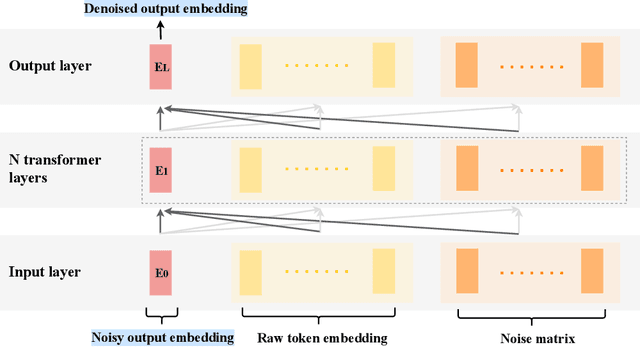

Large Language Models (LLMs) shows powerful capability in natural language understanding by capturing hidden semantics in vector space. This process enriches the value of the text embeddings for various downstream tasks, thereby fostering the Embedding-as-a-Service (EaaS) business model. However, the direct transmission of text to servers poses a largely unaddressed risk of privacy leakage. To mitigate this issue, we introduce Split-N-Denoise (SnD), an innovative framework that split the model to execute the token embedding layer on the client side at minimal computational cost. This allows the client to introduce noise prior to transmitting the embeddings to the server, and subsequently receive and denoise the perturbed output embeddings for downstream tasks. Our approach is designed for the inference stage of LLMs and requires no modifications to the model parameters. Extensive experiments demonstrate SnD's effectiveness in optimizing the privacy-utility tradeoff across various LLM architectures and diverse downstream tasks. The results reveal a significant performance improvement under the same privacy budget compared to the baseline, offering clients a privacy-preserving solution for local privacy protection.