 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyze: Evidence-Enriched Data Synthesis from Biomedical Papers
May 30, 2026General-purpose VLMs remain unreliable for biomedical research because valid answers in scientific papers depend on evidence split across figures, tables, charts, captions, and referring text. Existing post-training pipelines are bottlenecked by costly expert annotation and by synthetic data that drops this evidence structure. We present Ryze, a fully automated system that converts raw biomedical papers into an evidence-enriched training set and a domain-specialized VLM. Ryze synthesizes QA pairs with complete supporting evidence (visual element, caption, extracted structure, and referring paragraphs), reduces layout and OCR errors via chart/table-aware extraction and LLM-based cleansing, and applies a progress-gated post-training strategy combining supervised fine-tuning with reinforcement learning. Starting from Qwen3-VL-8B, Ryze produces BioVLM-8B at under USD 200, achieving 48.0% weighted accuracy on LAB-Bench, outperforming the base model by +12.6 percentage points (pp) and surpassing GPT-5.2 by +3.8 pp. We release Ryze as open source together with the trained BioVLM-8B model.
Do Agents Know What They Can't Do? Evaluating Feasibility Awareness in Tool-Using Agents
May 27, 2026Tool-using agents often incur substantial computational cost due to long reasoning chains and iterative tool usage. In practical scenarios, many tasks become infeasible under constrained tool environments, where the capabilities required for successful task completion are unavailable. Detecting infeasible tasks and stopping execution early can significantly reduce unnecessary execution cost. In this work, we propose FeasiGen, an automatic pipeline for constructing infeasible agent tasks by identifying the critical tools required for successful task completion. Our approach extracts tool-calling traces from successful executions across multiple agent systems, identifies critical tools consistently shared across diverse execution strategies, and masks these tools to automatically transform solvable tasks into infeasible ones. Human verification confirms that the infeasibility annotations for our constructed tasks achieve over 94% accuracy. We further introduce feasibility-aware evaluation metrics for measuring whether agents can recognize infeasible tasks and stop execution appropriately. Extensive evaluations across nine models reveal substantially weak infeasibility detection ability, with false continue rate reaching up to 73.9%. We further observe that multi-agent architectures significantly reduce erroneous execution under infeasible conditions.
RAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse
Nov 05, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with retrieved context but often suffers from downgraded prefill performance as modern applications demand longer and more complex inputs. Existing caching techniques either preserve accuracy with low cache reuse or improve reuse at the cost of degraded reasoning quality. We present RAGBoost, an efficient RAG system that achieves high cache reuse without sacrificing accuracy through accuracy-preserving context reuse. RAGBoost detects overlapping retrieved items across concurrent sessions and multi-turn interactions, using efficient context indexing, ordering, and de-duplication to maximize reuse, while lightweight contextual hints maintain reasoning fidelity. It integrates seamlessly with existing LLM inference engines and improves their prefill performance by 1.5-3X over state-of-the-art methods, while preserving or even enhancing reasoning accuracy across diverse RAG and agentic AI workloads. Our code is released at: https://github.com/Edinburgh-AgenticAI/RAGBoost.
HybridServe: Efficient Serving of Large AI Models with Confidence-Based Cascade Routing
May 18, 2025


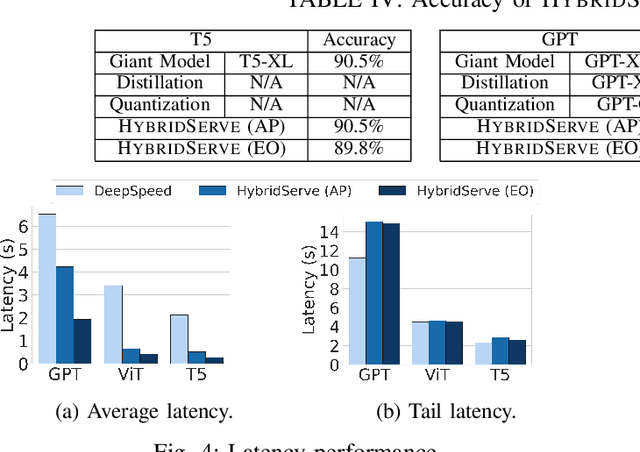
Giant Deep Neural Networks (DNNs), have become indispensable for accurate and robust support of large-scale cloud based AI services. However, serving giant DNNs is prohibitively expensive from an energy consumption viewpoint easily exceeding that of training, due to the enormous scale of GPU clusters needed to hold giant DNN model partitions and replicas. Existing approaches can either optimize energy efficiency or inference accuracy but not both. To overcome this status quo, we propose HybridServe, a novel hybrid DNN model serving system that leverages multiple sized versions (small to giant) of the model to be served in tandem. Through a confidence based hybrid model serving dataflow, HybridServe prefers to serve inference requests with energy-efficient smaller models so long as accuracy is not compromised, thereby reducing the number of replicas needed for giant DNNs. HybridServe also features a dataflow planner for efficient partitioning and replication of candidate models to maximize serving system throughput. Experimental results using a prototype implementation of HybridServe show that it reduces energy footprint by up to 19.8x compared to the state-of-the-art DNN model serving systems while matching the accuracy of serving solely with giant DNNs.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
MoE-Gen: High-Throughput MoE Inference on a Single GPU with Module-Based Batching
Mar 12, 2025This paper presents MoE-Gen, a high-throughput MoE inference system optimized for single-GPU execution. Existing inference systems rely on model-based or continuous batching strategies, originally designed for interactive inference, which result in excessively small batches for MoE's key modules-attention and expert modules-leading to poor throughput. To address this, we introduce module-based batching, which accumulates tokens in host memory and dynamically launches large batches on GPUs to maximize utilization. Additionally, we optimize the choice of batch sizes for each module in an MoE to fully overlap GPU computation and communication, maximizing throughput. Evaluation demonstrates that MoE-Gen achieves 8-31x higher throughput compared to state-of-the-art systems employing model-based batching (FlexGen, MoE-Lightning, DeepSpeed), and offers even greater throughput improvements over continuous batching systems (e.g., vLLM and Ollama) on popular MoE models (DeepSeek and Mixtral) across offline inference tasks. MoE-Gen's source code is publicly available at https://github.com/EfficientMoE/MoE-Gen
WaferLLM: A Wafer-Scale LLM Inference System
Feb 06, 2025Emerging AI accelerators increasingly adopt wafer-scale manufacturing technologies, integrating hundreds of thousands of AI cores in a mesh-based architecture with large distributed on-chip memory (tens of GB in total) and ultra-high on-chip memory bandwidth (tens of PB/s). However, current LLM inference systems, optimized for shared memory architectures like GPUs, fail to fully exploit these accelerators. We introduce WaferLLM, the first wafer-scale LLM inference system. WaferLLM is guided by a novel PLMR device model that captures the unique hardware characteristics of wafer-scale architectures. Leveraging this model, WaferLLM pioneers wafer-scale LLM parallelism, optimizing the utilization of hundreds of thousands of on-chip cores. It also introduces MeshGEMM and MeshGEMV, the first GEMM and GEMV implementations designed to scale effectively on wafer-scale accelerators. Evaluations show that WaferLLM achieves 200$\times$ better wafer-scale accelerator utilization than state-of-the-art systems. On a commodity wafer-scale accelerator, WaferLLM delivers 606$\times$ faster and 22$\times$ more energy-efficient GEMV compared to an advanced GPU. For LLMs, WaferLLM enables 39$\times$ faster decoding with 1.7$\times$ better energy efficiency. We anticipate these numbers will grow significantly as wafer-scale AI models, software, and hardware continue to mature.
MoE-CAP: Cost-Accuracy-Performance Benchmarking for Mixture-of-Experts Systems
Dec 10, 2024The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently; however, MoE systems rely on heterogeneous compute and memory resources. These factors collectively influence the system's Cost, Accuracy, and Performance (CAP), creating a challenging trade-off. Current benchmarks often fail to provide precise estimates of these effects, complicating practical considerations for deploying MoE systems. To bridge this gap, we introduce MoE-CAP, a benchmark specifically designed to evaluate MoE systems. Our findings highlight the difficulty of achieving an optimal balance of cost, accuracy, and performance with existing hardware capabilities. MoE systems often necessitate compromises on one factor to optimize the other two, a dynamic we term the MoE-CAP trade-off. To identify the best trade-off, we propose novel performance evaluation metrics - Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU) - and develop cost models that account for the heterogeneous compute and memory hardware integral to MoE systems. This benchmark is publicly available on HuggingFace: https://huggingface.co/spaces/sparse-generative-ai/open-moe-llm-leaderboard.
PH-Dropout: Practical Epistemic Uncertainty Quantification for View Synthesis
Oct 11, 2024View synthesis using Neural Radiance Fields (NeRF) and Gaussian Splatting (GS) has demonstrated impressive fidelity in rendering real-world scenarios. However, practical methods for accurate and efficient epistemic Uncertainty Quantification (UQ) in view synthesis are lacking. Existing approaches for NeRF either introduce significant computational overhead (e.g., ``10x increase in training time" or ``10x repeated training") or are limited to specific uncertainty conditions or models. Notably, GS models lack any systematic approach for comprehensive epistemic UQ. This capability is crucial for improving the robustness and scalability of neural view synthesis, enabling active model updates, error estimation, and scalable ensemble modeling based on uncertainty. In this paper, we revisit NeRF and GS-based methods from a function approximation perspective, identifying key differences and connections in 3D representation learning. Building on these insights, we introduce PH-Dropout (Post hoc Dropout), the first real-time and accurate method for epistemic uncertainty estimation that operates directly on pre-trained NeRF and GS models. Extensive evaluations validate our theoretical findings and demonstrate the effectiveness of PH-Dropout.
PH-Dropout: Prctical Epistemic Uncertainty Quantification for View Synthesis
Oct 07, 2024View synthesis using Neural Radiance Fields (NeRF) and Gaussian Splatting (GS) has demonstrated impressive fidelity in rendering real-world scenarios. However, practical methods for accurate and efficient epistemic Uncertainty Quantification (UQ) in view synthesis are lacking. Existing approaches for NeRF either introduce significant computational overhead (e.g., ``10x increase in training time" or ``10x repeated training") or are limited to specific uncertainty conditions or models. Notably, GS models lack any systematic approach for comprehensive epistemic UQ. This capability is crucial for improving the robustness and scalability of neural view synthesis, enabling active model updates, error estimation, and scalable ensemble modeling based on uncertainty. In this paper, we revisit NeRF and GS-based methods from a function approximation perspective, identifying key differences and connections in 3D representation learning. Building on these insights, we introduce PH-Dropout (Post hoc Dropout), the first real-time and accurate method for epistemic uncertainty estimation that operates directly on pre-trained NeRF and GS models. Extensive evaluations validate our theoretical findings and demonstrate the effectiveness of PH-Dropout.