 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphDancer: Training LLMs to Explore and Reason over Graphs via Curriculum Reinforcement Learning
Jan 24, 2026Large language models (LLMs) increasingly rely on external knowledge to improve factuality, yet many real-world knowledge sources are organized as heterogeneous graphs rather than plain text. Reasoning over such graph-structured knowledge poses two key challenges: (1) navigating structured, schema-defined relations requires precise function calls rather than similarity-based retrieval, and (2) answering complex questions often demands multi-hop evidence aggregation through iterative information seeking. We propose GraphDancer, a reinforcement learning (RL) framework that teaches LLMs to navigate graphs by interleaving reasoning and function execution. To make RL effective for moderate-sized LLMs, we introduce a graph-aware curriculum that schedules training by the structural complexity of information-seeking trajectories using an easy-to-hard biased sampler. We evaluate GraphDancer on a multi-domain benchmark by training on one domain only and testing on unseen domains and out-of-distribution question types. Despite using only a 3B backbone, GraphDancer outperforms baselines equipped with either a 14B backbone or GPT-4o-mini, demonstrating robust cross-domain generalization of graph exploration and reasoning skills. Our code and models can be found at https://yuyangbai.com/graphdancer/ .
Beyond Single-shot Writing: Deep Research Agents are Unreliable at Multi-turn Report Revision
Jan 19, 2026Existing benchmarks for Deep Research Agents (DRAs) treat report generation as a single-shot writing task, which fundamentally diverges from how human researchers iteratively draft and revise reports via self-reflection or peer feedback. Whether DRAs can reliably revise reports with user feedback remains unexplored. We introduce Mr Dre, an evaluation suite that establishes multi-turn report revision as a new evaluation axis for DRAs. Mr Dre consists of (1) a unified long-form report evaluation protocol spanning comprehensiveness, factuality, and presentation, and (2) a human-verified feedback simulation pipeline for multi-turn revision. Our analysis of five diverse DRAs reveals a critical limitation: while agents can address most user feedback, they also regress on 16-27% of previously covered content and citation quality. Over multiple revision turns, even the best-performing agents leave significant headroom, as they continue to disrupt content outside the feedback's scope and fail to preserve earlier edits. We further show that these issues are not easily resolvable through inference-time fixes such as prompt engineering and a dedicated sub-agent for report revision.
A Rigorous Benchmark with Multidimensional Evaluation for Deep Research Agents: From Answers to Reports
Oct 02, 2025Artificial intelligence is undergoing the paradigm shift from closed language models to interconnected agent systems capable of external perception and information integration. As a representative embodiment, Deep Research Agents (DRAs) systematically exhibit the capabilities for task decomposition, cross-source retrieval, multi-stage reasoning, and structured output, which markedly enhance performance on complex and open-ended tasks. However, existing benchmarks remain deficient in evaluation dimensions, response formatting, and scoring mechanisms, limiting their capacity to assess such systems effectively. This paper introduces a rigorous benchmark and a multidimensional evaluation framework tailored to DRAs and report-style responses. The benchmark comprises 214 expert-curated challenging queries distributed across 10 broad thematic domains, each accompanied by manually constructed reference bundles to support composite evaluation. The framework enables comprehensive evaluation of long-form reports generated by DRAs, incorporating integrated scoring metrics for semantic quality, topical focus, and retrieval trustworthiness. Extensive experimentation confirms the superior performance of mainstream DRAs over web-search-tool-augmented reasoning models, yet reveals considerable scope for further improvement. This study provides a robust foundation for capability assessment, architectural refinement, and paradigm advancement in DRA systems.
VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
Jun 04, 2025Large language models (LLMs) often struggle with visualization tasks like plotting diagrams, charts, where success depends on both code correctness and visual semantics. Existing instruction-tuning datasets lack execution-grounded supervision and offer limited support for iterative code correction, resulting in fragile and unreliable plot generation. We present VisCode-200K, a large-scale instruction tuning dataset for Python-based visualization and self-correction. It contains over 200K examples from two sources: (1) validated plotting code from open-source repositories, paired with natural language instructions and rendered plots; and (2) 45K multi-turn correction dialogues from Code-Feedback, enabling models to revise faulty code using runtime feedback. We fine-tune Qwen2.5-Coder-Instruct on VisCode-200K to create VisCoder, and evaluate it on PandasPlotBench. VisCoder significantly outperforms strong open-source baselines and approaches the performance of proprietary models like GPT-4o-mini. We further adopt a self-debug evaluation protocol to assess iterative repair, demonstrating the benefits of feedback-driven learning for executable, visually accurate code generation.
StructEval: Benchmarking LLMs' Capabilities to Generate Structural Outputs
May 26, 2025
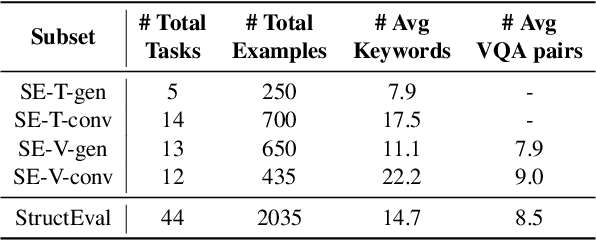
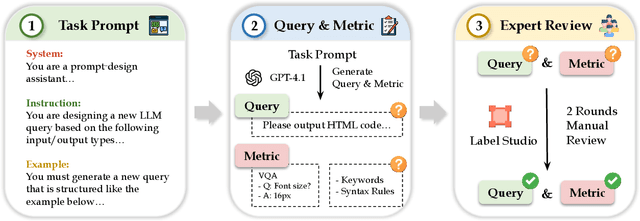

As Large Language Models (LLMs) become integral to software development workflows, their ability to generate structured outputs has become critically important. We introduce StructEval, a comprehensive benchmark for evaluating LLMs' capabilities in producing both non-renderable (JSON, YAML, CSV) and renderable (HTML, React, SVG) structured formats. Unlike prior benchmarks, StructEval systematically evaluates structural fidelity across diverse formats through two paradigms: 1) generation tasks, producing structured output from natural language prompts, and 2) conversion tasks, translating between structured formats. Our benchmark encompasses 18 formats and 44 types of task, with novel metrics for format adherence and structural correctness. Results reveal significant performance gaps, even state-of-the-art models like o1-mini achieve only 75.58 average score, with open-source alternatives lagging approximately 10 points behind. We find generation tasks more challenging than conversion tasks, and producing correct visual content more difficult than generating text-only structures.
Likert or Not: LLM Absolute Relevance Judgments on Fine-Grained Ordinal Scales
May 25, 2025Large language models (LLMs) obtain state of the art zero shot relevance ranking performance on a variety of information retrieval tasks. The two most common prompts to elicit LLM relevance judgments are pointwise scoring (a.k.a. relevance generation), where the LLM sees a single query-document pair and outputs a single relevance score, and listwise ranking (a.k.a. permutation generation), where the LLM sees a query and a list of documents and outputs a permutation, sorting the documents in decreasing order of relevance. The current research community consensus is that listwise ranking yields superior performance, and significant research effort has been devoted to crafting LLM listwise ranking algorithms. The underlying hypothesis is that LLMs are better at making relative relevance judgments than absolute ones. In tension with this hypothesis, we find that the gap between pointwise scoring and listwise ranking shrinks when pointwise scoring is implemented using a sufficiently large ordinal relevance label space, becoming statistically insignificant for many LLM-benchmark dataset combinations (where ``significant'' means ``95\% confidence that listwise ranking improves NDCG@10''). Our evaluations span four LLMs, eight benchmark datasets from the BEIR and TREC-DL suites, and two proprietary datasets with relevance labels collected after the training cut-off of all LLMs evaluated.
VideoEval-Pro: Robust and Realistic Long Video Understanding Evaluation
May 20, 2025Large multimodal models (LMMs) have recently emerged as a powerful tool for long video understanding (LVU), prompting the development of standardized LVU benchmarks to evaluate their performance. However, our investigation reveals a rather sober lesson for existing LVU benchmarks. First, most existing benchmarks rely heavily on multiple-choice questions (MCQs), whose evaluation results are inflated due to the possibility of guessing the correct answer; Second, a significant portion of questions in these benchmarks have strong priors to allow models to answer directly without even reading the input video. For example, Gemini-1.5-Pro can achieve over 50\% accuracy given a random frame from a long video on Video-MME. We also observe that increasing the number of frames does not necessarily lead to improvement on existing benchmarks, which is counterintuitive. As a result, the validity and robustness of current LVU benchmarks are undermined, impeding a faithful assessment of LMMs' long-video understanding capability. To tackle this problem, we propose VideoEval-Pro, a realistic LVU benchmark containing questions with open-ended short-answer, which truly require understanding the entire video. VideoEval-Pro assesses both segment-level and full-video understanding through perception and reasoning tasks. By evaluating 21 proprietary and open-source video LMMs, we conclude the following findings: (1) video LMMs show drastic performance ($>$25\%) drops on open-ended questions compared with MCQs; (2) surprisingly, higher MCQ scores do not lead to higher open-ended scores on VideoEval-Pro; (3) compared to other MCQ benchmarks, VideoEval-Pro benefits more from increasing the number of input frames. Our results show that VideoEval-Pro offers a more realistic and reliable measure of long video understanding, providing a clearer view of progress in this domain.
MoE-CAP: Benchmarking Cost, Accuracy and Performance of Sparse Mixture-of-Experts Systems
May 16, 2025The sparse Mixture-of-Experts (MoE) architecture is increasingly favored for scaling Large Language Models (LLMs) efficiently, but it depends on heterogeneous compute and memory resources. These factors jointly affect system Cost, Accuracy, and Performance (CAP), making trade-offs inevitable. Existing benchmarks often fail to capture these trade-offs accurately, complicating practical deployment decisions. To address this, we introduce MoE-CAP, a benchmark specifically designed for MoE systems. Our analysis reveals that achieving an optimal balance across CAP is difficult with current hardware; MoE systems typically optimize two of the three dimensions at the expense of the third-a dynamic we term the MoE-CAP trade-off. To visualize this, we propose the CAP Radar Diagram. We further introduce sparsity-aware performance metrics-Sparse Memory Bandwidth Utilization (S-MBU) and Sparse Model FLOPS Utilization (S-MFU)-to enable accurate performance benchmarking of MoE systems across diverse hardware platforms and deployment scenarios.
Nearest Neighbor Multivariate Time Series Forecasting
May 16, 2025Multivariate time series (MTS) forecasting has a wide range of applications in both industry and academia. Recently, spatial-temporal graph neural networks (STGNNs) have gained popularity as MTS forecasting methods. However, current STGNNs can only use the finite length of MTS input data due to the computational complexity. Moreover, they lack the ability to identify similar patterns throughout the entire dataset and struggle with data that exhibit sparsely and discontinuously distributed correlations among variables over an extensive historical period, resulting in only marginal improvements. In this article, we introduce a simple yet effective k-nearest neighbor MTS forecasting ( kNN-MTS) framework, which forecasts with a nearest neighbor retrieval mechanism over a large datastore of cached series, using representations from the MTS model for similarity search. This approach requires no additional training and scales to give the MTS model direct access to the whole dataset at test time, resulting in a highly expressive model that consistently improves performance, and has the ability to extract sparse distributed but similar patterns spanning over multivariables from the entire dataset. Furthermore, a hybrid spatial-temporal encoder (HSTEncoder) is designed for kNN-MTS which can capture both long-term temporal and short-term spatial-temporal dependencies and is shown to provide accurate representation for kNN-MTSfor better forecasting. Experimental results on several real-world datasets show a significant improvement in the forecasting performance of kNN-MTS. The quantitative analysis also illustrates the interpretability and efficiency of kNN-MTS, showing better application prospects and opening up a new path for efficiently using the large dataset in MTS models.
Breaking the Batch Barrier (B3) of Contrastive Learning via Smart Batch Mining
May 16, 2025Contrastive learning (CL) is a prevalent technique for training embedding models, which pulls semantically similar examples (positives) closer in the representation space while pushing dissimilar ones (negatives) further apart. A key source of negatives are 'in-batch' examples, i.e., positives from other examples in the batch. Effectiveness of such models is hence strongly influenced by the size and quality of training batches. In this work, we propose 'Breaking the Batch Barrier' (B3), a novel batch construction strategy designed to curate high-quality batches for CL. Our approach begins by using a pretrained teacher embedding model to rank all examples in the dataset, from which a sparse similarity graph is constructed. A community detection algorithm is then applied to this graph to identify clusters of examples that serve as strong negatives for one another. The clusters are then used to construct batches that are rich in in-batch negatives. Empirical results on the MMEB multimodal embedding benchmark (36 tasks) demonstrate that our method sets a new state of the art, outperforming previous best methods by +1.3 and +2.9 points at the 7B and 2B model scales, respectively. Notably, models trained with B3 surpass existing state-of-the-art results even with a batch size as small as 64, which is 4-16x smaller than that required by other methods.