 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Regeneration Paradigm: Contrastive Reflection Memory Guided Self-Verification and Self-Improvement
Mar 20, 2026Verification-guided self-improvement has recently emerged as a promising approach to improving the accuracy of large language model (LLM) outputs. However, existing approaches face a trade-off between inference efficiency and accuracy: iterative verification-rectification is computationally expensive and prone to being trapped in faulty reasoning, while best-of-N selection requires extensive sampling without addressing internal model flaws. We propose a training-free regeneration paradigm that leverages an offline-curated contrastive Reflection Memory (RM) to provide corrective guidance, while regenerating from scratch helps break out of faulty reasoning. At inference time, the method performs RM-guided self-verification followed by a single RM-guided regeneration, avoiding both iterative correction and multi-sample selection. We evaluated our method on nine benchmarks that span algorithmic, reasoning, symbolic, and domain-specific tasks in both small- and large-scale LLMs. Experiment results show that our method outperforms prior methods while maintaining low computational cost.
STEMS: Spatial-Temporal Enhanced Safe Multi-Agent Coordination for Building Energy Management
Oct 15, 2025Building energy management is essential for achieving carbon reduction goals, improving occupant comfort, and reducing energy costs. Coordinated building energy management faces critical challenges in exploiting spatial-temporal dependencies while ensuring operational safety across multi-building systems. Current multi-building energy systems face three key challenges: insufficient spatial-temporal information exploitation, lack of rigorous safety guarantees, and system complexity. This paper proposes Spatial-Temporal Enhanced Safe Multi-Agent Coordination (STEMS), a novel safety-constrained multi-agent reinforcement learning framework for coordinated building energy management. STEMS integrates two core components: (1) a spatial-temporal graph representation learning framework using a GCN-Transformer fusion architecture to capture inter-building relationships and temporal patterns, and (2) a safety-constrained multi-agent RL algorithm incorporating Control Barrier Functions to provide mathematical safety guarantees. Extensive experiments on real-world building datasets demonstrate STEMS's superior performance over existing methods, showing that STEMS achieves 21% cost reduction, 18% emission reduction, and dramatically reduces safety violations from 35.1% to 5.6% while maintaining optimal comfort with only 0.13 discomfort proportion. The framework also demonstrates strong robustness during extreme weather conditions and maintains effectiveness across different building types.
Leveraging Multivariate Long-Term History Representation for Time Series Forecasting
May 20, 2025Multivariate Time Series (MTS) forecasting has a wide range of applications in both industry and academia. Recent advances in Spatial-Temporal Graph Neural Network (STGNN) have achieved great progress in modelling spatial-temporal correlations. Limited by computational complexity, most STGNNs for MTS forecasting focus primarily on short-term and local spatial-temporal dependencies. Although some recent methods attempt to incorporate univariate history into modeling, they still overlook crucial long-term spatial-temporal similarities and correlations across MTS, which are essential for accurate forecasting. To fill this gap, we propose a framework called the Long-term Multivariate History Representation (LMHR) Enhanced STGNN for MTS forecasting. Specifically, a Long-term History Encoder (LHEncoder) is adopted to effectively encode the long-term history into segment-level contextual representations and reduce point-level noise. A non-parametric Hierarchical Representation Retriever (HRetriever) is designed to include the spatial information in the long-term spatial-temporal dependency modelling and pick out the most valuable representations with no additional training. A Transformer-based Aggregator (TAggregator) selectively fuses the sparsely retrieved contextual representations based on the ranking positional embedding efficiently. Experimental results demonstrate that LMHR outperforms typical STGNNs by 10.72% on the average prediction horizons and state-of-the-art methods by 4.12% on several real-world datasets. Additionally, it consistently improves prediction accuracy by 9.8% on the top 10% of rapidly changing patterns across the datasets.
Nearest Neighbor Multivariate Time Series Forecasting
May 16, 2025Multivariate time series (MTS) forecasting has a wide range of applications in both industry and academia. Recently, spatial-temporal graph neural networks (STGNNs) have gained popularity as MTS forecasting methods. However, current STGNNs can only use the finite length of MTS input data due to the computational complexity. Moreover, they lack the ability to identify similar patterns throughout the entire dataset and struggle with data that exhibit sparsely and discontinuously distributed correlations among variables over an extensive historical period, resulting in only marginal improvements. In this article, we introduce a simple yet effective k-nearest neighbor MTS forecasting ( kNN-MTS) framework, which forecasts with a nearest neighbor retrieval mechanism over a large datastore of cached series, using representations from the MTS model for similarity search. This approach requires no additional training and scales to give the MTS model direct access to the whole dataset at test time, resulting in a highly expressive model that consistently improves performance, and has the ability to extract sparse distributed but similar patterns spanning over multivariables from the entire dataset. Furthermore, a hybrid spatial-temporal encoder (HSTEncoder) is designed for kNN-MTS which can capture both long-term temporal and short-term spatial-temporal dependencies and is shown to provide accurate representation for kNN-MTSfor better forecasting. Experimental results on several real-world datasets show a significant improvement in the forecasting performance of kNN-MTS. The quantitative analysis also illustrates the interpretability and efficiency of kNN-MTS, showing better application prospects and opening up a new path for efficiently using the large dataset in MTS models.
Leveraging LLMs as Meta-Judges: A Multi-Agent Framework for Evaluating LLM Judgments
Apr 23, 2025Large language models (LLMs) are being widely applied across various fields, but as tasks become more complex, evaluating their responses is increasingly challenging. Compared to human evaluators, the use of LLMs to support performance evaluation offers a more efficient alternative. However, most studies focus mainly on aligning LLMs' judgments with human preferences, overlooking the existence of biases and mistakes in human judgment. Furthermore, how to select suitable LLM judgments given multiple potential LLM responses remains underexplored. To address these two aforementioned issues, we propose a three-stage meta-judge selection pipeline: 1) developing a comprehensive rubric with GPT-4 and human experts, 2) using three advanced LLM agents to score judgments, and 3) applying a threshold to filter out low-scoring judgments. Compared to methods using a single LLM as both judge and meta-judge, our pipeline introduces multi-agent collaboration and a more comprehensive rubric. Experimental results on the JudgeBench dataset show about 15.55\% improvement compared to raw judgments and about 8.37\% improvement over the single-agent baseline. Our work demonstrates the potential of LLMs as meta-judges and lays the foundation for future research on constructing preference datasets for LLM-as-a-judge reinforcement learning.
MXMap: A Multivariate Cross Mapping Framework for Causal Discovery in Dynamical Systems
Feb 06, 2025Convergent Cross Mapping (CCM) is a powerful method for detecting causality in coupled nonlinear dynamical systems, providing a model-free approach to capture dynamic causal interactions. Partial Cross Mapping (PCM) was introduced as an extension of CCM to address indirect causality in three-variable systems by comparing cross-mapping quality between direct cause-effect mapping and indirect mapping through an intermediate conditioning variable. However, PCM remains limited to univariate delay embeddings in its cross-mapping processes. In this work, we extend PCM to the multivariate setting, introducing multiPCM, which leverages multivariate embeddings to more effectively distinguish indirect causal relationships. We further propose a multivariate cross-mapping framework (MXMap) for causal discovery in dynamical systems. This two-phase framework combines (1) pairwise CCM tests to establish an initial causal graph and (2) multiPCM to refine the graph by pruning indirect causal connections. Through experiments on simulated data and the ERA5 Reanalysis weather dataset, we demonstrate the effectiveness of MXMap. Additionally, MXMap is compared against several baseline methods, showing advantages in accuracy and causal graph refinement.
DRDT3: Diffusion-Refined Decision Test-Time Training Model
Jan 12, 2025Decision Transformer (DT), a trajectory modeling method, has shown competitive performance compared to traditional offline reinforcement learning (RL) approaches on various classic control tasks. However, it struggles to learn optimal policies from suboptimal, reward-labeled trajectories. In this study, we explore the use of conditional generative modeling to facilitate trajectory stitching given its high-quality data generation ability. Additionally, recent advancements in Recurrent Neural Networks (RNNs) have shown their linear complexity and competitive sequence modeling performance over Transformers. We leverage the Test-Time Training (TTT) layer, an RNN that updates hidden states during testing, to model trajectories in the form of DT. We introduce a unified framework, called Diffusion-Refined Decision TTT (DRDT3), to achieve performance beyond DT models. Specifically, we propose the Decision TTT (DT3) module, which harnesses the sequence modeling strengths of both self-attention and the TTT layer to capture recent contextual information and make coarse action predictions. We further integrate DT3 with the diffusion model using a unified optimization objective. With experiments on multiple tasks of Gym and AntMaze in the D4RL benchmark, our DT3 model without diffusion refinement demonstrates improved performance over standard DT, while DRDT3 further achieves superior results compared to state-of-the-art conventional offline RL and DT-based methods.
Goal-Conditioned Data Augmentation for Offline Reinforcement Learning
Dec 29, 2024

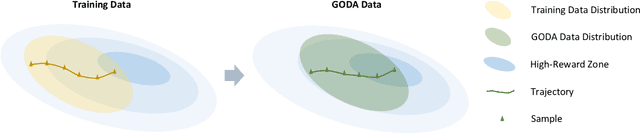

Offline reinforcement learning (RL) enables policy learning from pre-collected offline datasets, relaxing the need to interact directly with the environment. However, limited by the quality of offline datasets, it generally fails to learn well-qualified policies in suboptimal datasets. To address datasets with insufficient optimal demonstrations, we introduce Goal-cOnditioned Data Augmentation (GODA), a novel goal-conditioned diffusion-based method for augmenting samples with higher quality. Leveraging recent advancements in generative modeling, GODA incorporates a novel return-oriented goal condition with various selection mechanisms. Specifically, we introduce a controllable scaling technique to provide enhanced return-based guidance during data sampling. GODA learns a comprehensive distribution representation of the original offline datasets while generating new data with selectively higher-return goals, thereby maximizing the utility of limited optimal demonstrations. Furthermore, we propose a novel adaptive gated conditioning method for processing noised inputs and conditions, enhancing the capture of goal-oriented guidance. We conduct experiments on the D4RL benchmark and real-world challenges, specifically traffic signal control (TSC) tasks, to demonstrate GODA's effectiveness in enhancing data quality and superior performance compared to state-of-the-art data augmentation methods across various offline RL algorithms.
Robot Policy Learning with Temporal Optimal Transport Reward
Oct 29, 2024



Reward specification is one of the most tricky problems in Reinforcement Learning, which usually requires tedious hand engineering in practice. One promising approach to tackle this challenge is to adopt existing expert video demonstrations for policy learning. Some recent work investigates how to learn robot policies from only a single/few expert video demonstrations. For example, reward labeling via Optimal Transport (OT) has been shown to be an effective strategy to generate a proxy reward by measuring the alignment between the robot trajectory and the expert demonstrations. However, previous work mostly overlooks that the OT reward is invariant to temporal order information, which could bring extra noise to the reward signal. To address this issue, in this paper, we introduce the Temporal Optimal Transport (TemporalOT) reward to incorporate temporal order information for learning a more accurate OT-based proxy reward. Extensive experiments on the Meta-world benchmark tasks validate the efficacy of the proposed method. Code is available at: https://github.com/fuyw/TemporalOT
An Online Self-learning Graph-based Lateral Controller for Self-Driving Cars
Oct 15, 2024



The hype around self-driving cars has been growing over the past years and has sparked much research. Several modules in self-driving cars are thoroughly investigated to ensure safety, comfort, and efficiency, among which the controller is crucial. The controller module can be categorized into longitudinal and lateral controllers in which the task of the former is to follow the reference velocity, and the latter is to reduce the lateral displacement error from the reference path. Generally, a tuned controller is not sufficient to perform in all environments. Thus, a controller that can adapt to changing conditions is necessary for autonomous driving. Furthermore, these controllers often depend on vehicle models that also need to adapt over time due to varying environments. This paper uses graphs to present novel techniques to learn the vehicle model and the lateral controller online. First, a heterogeneous graph is presented depicting the current states of and inputs to the vehicle. The vehicle model is then learned online using known physical constraints in conjunction with the processing of the graph through a Graph Neural Network structure. Next, another heterogeneous graph - depicting the transition from current to desired states - is processed through another Graph Neural Network structure to generate the steering command on the fly. Finally, the performance of this self-learning model-based lateral controller is evaluated and shown to be satisfactory on an open-source autonomous driving platform called CARLA.