 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRDT3: Diffusion-Refined Decision Test-Time Training Model
Jan 12, 2025Decision Transformer (DT), a trajectory modeling method, has shown competitive performance compared to traditional offline reinforcement learning (RL) approaches on various classic control tasks. However, it struggles to learn optimal policies from suboptimal, reward-labeled trajectories. In this study, we explore the use of conditional generative modeling to facilitate trajectory stitching given its high-quality data generation ability. Additionally, recent advancements in Recurrent Neural Networks (RNNs) have shown their linear complexity and competitive sequence modeling performance over Transformers. We leverage the Test-Time Training (TTT) layer, an RNN that updates hidden states during testing, to model trajectories in the form of DT. We introduce a unified framework, called Diffusion-Refined Decision TTT (DRDT3), to achieve performance beyond DT models. Specifically, we propose the Decision TTT (DT3) module, which harnesses the sequence modeling strengths of both self-attention and the TTT layer to capture recent contextual information and make coarse action predictions. We further integrate DT3 with the diffusion model using a unified optimization objective. With experiments on multiple tasks of Gym and AntMaze in the D4RL benchmark, our DT3 model without diffusion refinement demonstrates improved performance over standard DT, while DRDT3 further achieves superior results compared to state-of-the-art conventional offline RL and DT-based methods.
Goal-Conditioned Data Augmentation for Offline Reinforcement Learning
Dec 29, 2024

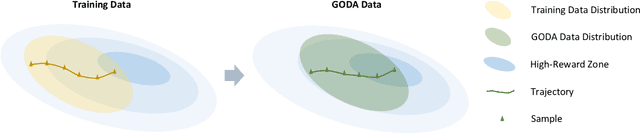

Offline reinforcement learning (RL) enables policy learning from pre-collected offline datasets, relaxing the need to interact directly with the environment. However, limited by the quality of offline datasets, it generally fails to learn well-qualified policies in suboptimal datasets. To address datasets with insufficient optimal demonstrations, we introduce Goal-cOnditioned Data Augmentation (GODA), a novel goal-conditioned diffusion-based method for augmenting samples with higher quality. Leveraging recent advancements in generative modeling, GODA incorporates a novel return-oriented goal condition with various selection mechanisms. Specifically, we introduce a controllable scaling technique to provide enhanced return-based guidance during data sampling. GODA learns a comprehensive distribution representation of the original offline datasets while generating new data with selectively higher-return goals, thereby maximizing the utility of limited optimal demonstrations. Furthermore, we propose a novel adaptive gated conditioning method for processing noised inputs and conditions, enhancing the capture of goal-oriented guidance. We conduct experiments on the D4RL benchmark and real-world challenges, specifically traffic signal control (TSC) tasks, to demonstrate GODA's effectiveness in enhancing data quality and superior performance compared to state-of-the-art data augmentation methods across various offline RL algorithms.
Traffic Signal Control Using Lightweight Transformers: An Offline-to-Online RL Approach
Dec 12, 2023



Efficient traffic signal control is critical for reducing traffic congestion and improving overall transportation efficiency. The dynamic nature of traffic flow has prompted researchers to explore Reinforcement Learning (RL) for traffic signal control (TSC). Compared with traditional methods, RL-based solutions have shown preferable performance. However, the application of RL-based traffic signal controllers in the real world is limited by the low sample efficiency and high computational requirements of these solutions. In this work, we propose DTLight, a simple yet powerful lightweight Decision Transformer-based TSC method that can learn policy from easily accessible offline datasets. DTLight novelly leverages knowledge distillation to learn a lightweight controller from a well-trained larger teacher model to reduce implementation computation. Additionally, it integrates adapter modules to mitigate the expenses associated with fine-tuning, which makes DTLight practical for online adaptation with minimal computation and only a few fine-tuning steps during real deployment. Moreover, DTLight is further enhanced to be more applicable to real-world TSC problems. Extensive experiments on synthetic and real-world scenarios show that DTLight pre-trained purely on offline datasets can outperform state-of-the-art online RL-based methods in most scenarios. Experiment results also show that online fine-tuning further improves the performance of DTLight by up to 42.6% over the best online RL baseline methods. In this work, we also introduce Datasets specifically designed for TSC with offline RL (referred to as DTRL). Our datasets and code are publicly available.
ModelLight: Model-Based Meta-Reinforcement Learning for Traffic Signal Control
Dec 06, 2021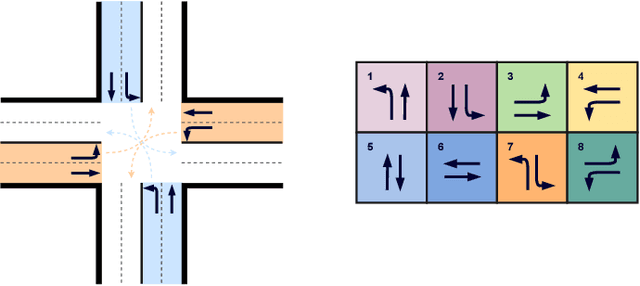
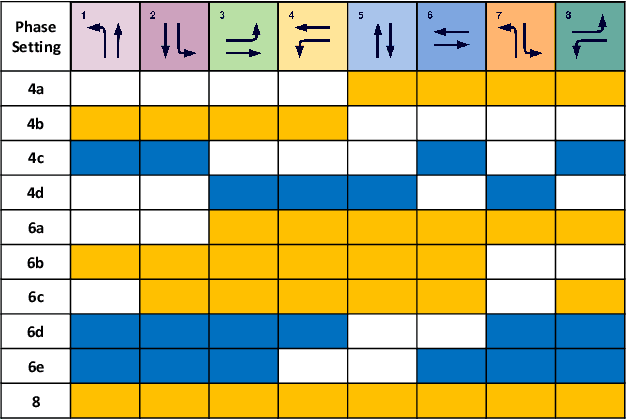
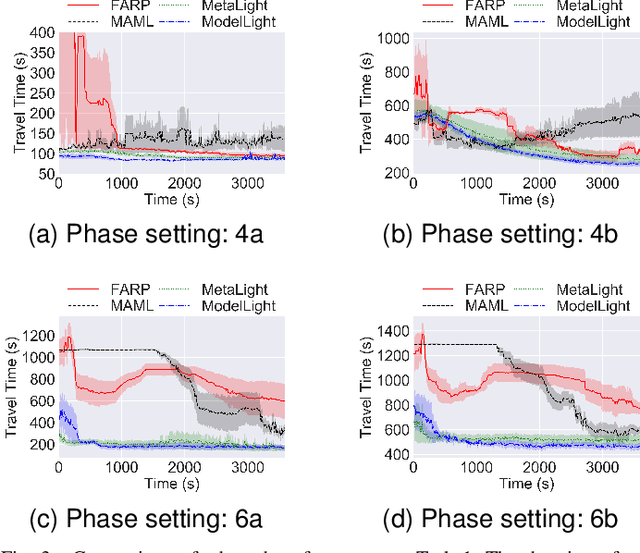
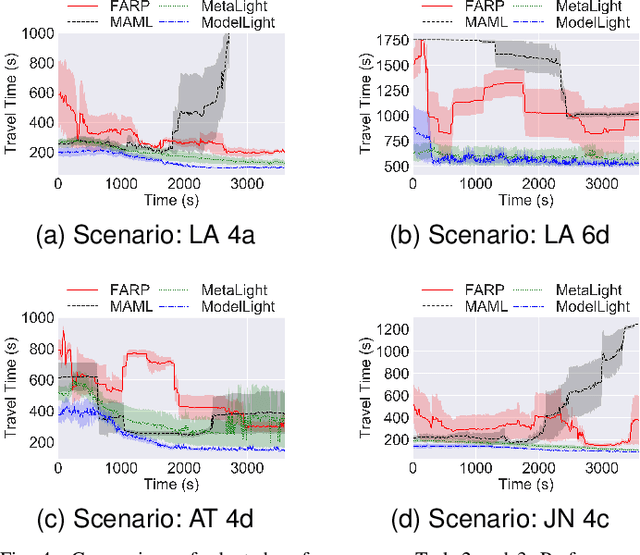
Traffic signal control is of critical importance for the effective use of transportation infrastructures. The rapid increase of vehicle traffic and changes in traffic patterns make traffic signal control more and more challenging. Reinforcement Learning (RL)-based algorithms have demonstrated their potential in dealing with traffic signal control. However, most existing solutions require a large amount of training data, which is unacceptable for many real-world scenarios. This paper proposes a novel model-based meta-reinforcement learning framework (ModelLight) for traffic signal control. Within ModelLight, an ensemble of models for road intersections and the optimization-based meta-learning method are used to improve the data efficiency of an RL-based traffic light control method. Experiments on real-world datasets demonstrate that ModelLight can outperform state-of-the-art traffic light control algorithms while substantially reducing the number of required interactions with the real-world environment.