 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIJIT: A Robotic Head for an Active Observer
Dec 08, 2025We present DIJIT, a novel binocular robotic head expressly designed for mobile agents that behave as active observers. DIJIT's unique breadth of functionality enables active vision research and the study of human-like eye and head-neck motions, their interrelationships, and how each contributes to visual ability. DIJIT is also being used to explore the differences between how human vision employs eye/head movements to solve visual tasks and current computer vision methods. DIJIT's design features nine mechanical degrees of freedom, while the cameras and lenses provide an additional four optical degrees of freedom. The ranges and speeds of the mechanical design are comparable to human performance. Our design includes the ranges of motion required for convergent stereo, namely, vergence, version, and cyclotorsion. The exploration of the utility of these to both human and machine vision is ongoing. Here, we present the design of DIJIT and evaluate aspects of its performance. We present a new method for saccadic camera movements. In this method, a direct relationship between camera orientation and motor values is developed. The resulting saccadic camera movements are close to human movements in terms of their accuracy.
Knowledge-Aware Conversation Derailment Forecasting Using Graph Convolutional Networks
Aug 24, 2024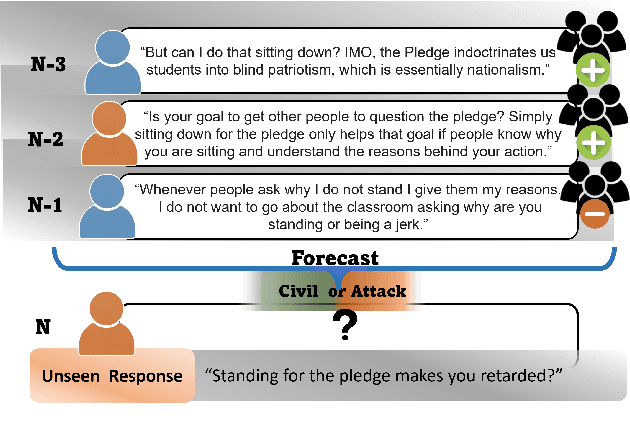
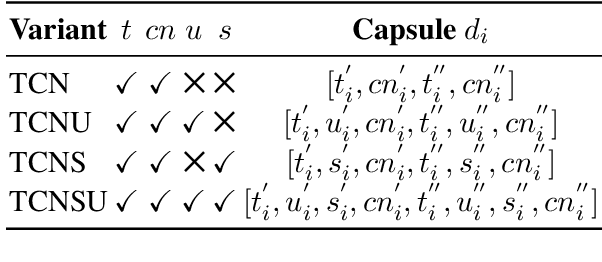
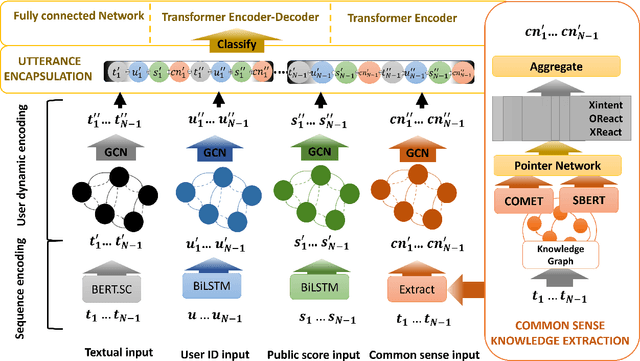
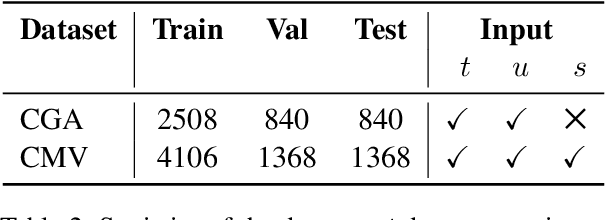
Online conversations are particularly susceptible to derailment, which can manifest itself in the form of toxic communication patterns including disrespectful comments and abuse. Forecasting conversation derailment predicts signs of derailment in advance enabling proactive moderation of conversations. State-of-the-art approaches to conversation derailment forecasting sequentially encode conversations and use graph neural networks to model dialogue user dynamics. However, existing graph models are not able to capture complex conversational characteristics such as context propagation and emotional shifts. The use of common sense knowledge enables a model to capture such characteristics, thus improving performance. Following this approach, here we derive commonsense statements from a knowledge base of dialogue contextual information to enrich a graph neural network classification architecture. We fuse the multi-source information on utterance into capsules, which are used by a transformer-based forecaster to predict conversation derailment. Our model captures conversation dynamics and context propagation, outperforming the state-of-the-art models on the CGA and CMV benchmark datasets
Hallucination Detection and Hallucination Mitigation: An Investigation
Jan 16, 2024Large language models (LLMs), including ChatGPT, Bard, and Llama, have achieved remarkable successes over the last two years in a range of different applications. In spite of these successes, there exist concerns that limit the wide application of LLMs. A key problem is the problem of hallucination. Hallucination refers to the fact that in addition to correct responses, LLMs can also generate seemingly correct but factually incorrect responses. This report aims to present a comprehensive review of the current literature on both hallucination detection and hallucination mitigation. We hope that this report can serve as a good reference for both engineers and researchers who are interested in LLMs and applying them to real world tasks.
Predicting Evoked Emotions in Conversations
Dec 31, 2023Understanding and predicting the emotional trajectory in multi-party multi-turn conversations is of great significance. Such information can be used, for example, to generate empathetic response in human-machine interaction or to inform models of pre-emptive toxicity detection. In this work, we introduce the novel problem of Predicting Emotions in Conversations (PEC) for the next turn (n+1), given combinations of textual and/or emotion input up to turn n. We systematically approach the problem by modeling three dimensions inherently connected to evoked emotions in dialogues, including (i) sequence modeling, (ii) self-dependency modeling, and (iii) recency modeling. These modeling dimensions are then incorporated into two deep neural network architectures, a sequence model and a graph convolutional network model. The former is designed to capture the sequence of utterances in a dialogue, while the latter captures the sequence of utterances and the network formation of multi-party dialogues. We perform a comprehensive empirical evaluation of the various proposed models for addressing the PEC problem. The results indicate (i) the importance of the self-dependency and recency model dimensions for the prediction task, (ii) the quality of simpler sequence models in short dialogues, (iii) the importance of the graph neural models in improving the predictions in long dialogues.
Conversation Derailment Forecasting with Graph Convolutional Networks
Jun 22, 2023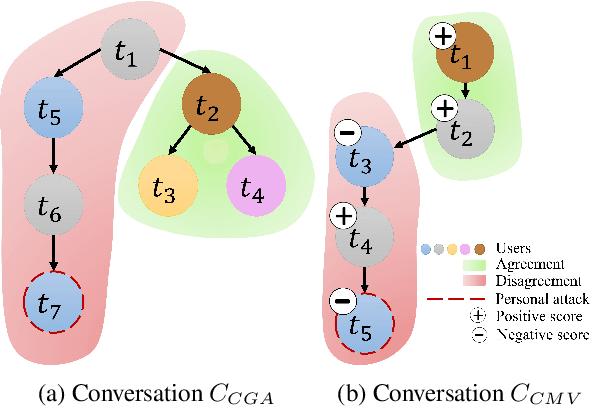

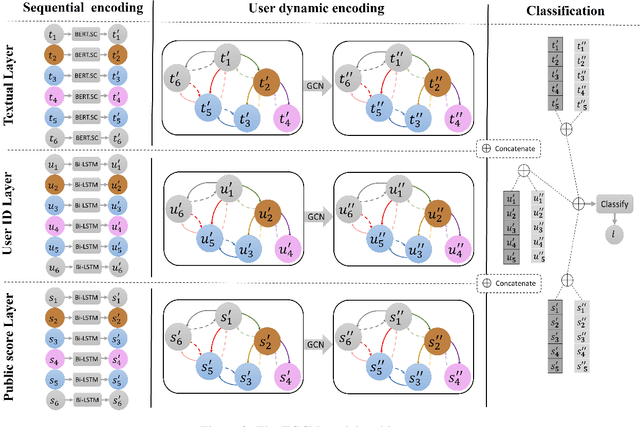
Online conversations are particularly susceptible to derailment, which can manifest itself in the form of toxic communication patterns like disrespectful comments or verbal abuse. Forecasting conversation derailment predicts signs of derailment in advance enabling proactive moderation of conversations. Current state-of-the-art approaches to address this problem rely on sequence models that treat dialogues as text streams. We propose a novel model based on a graph convolutional neural network that considers dialogue user dynamics and the influence of public perception on conversation utterances. Through empirical evaluation, we show that our model effectively captures conversation dynamics and outperforms the state-of-the-art models on the CGA and CMV benchmark datasets by 1.5\% and 1.7\%, respectively.
Policy Reuse for Communication Load Balancing in Unseen Traffic Scenarios
Mar 22, 2023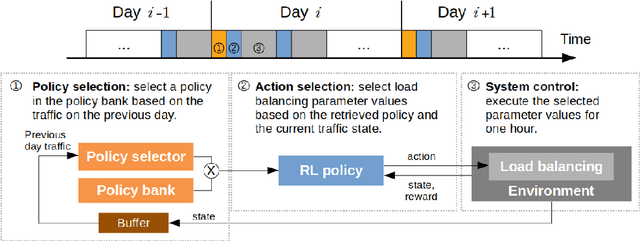
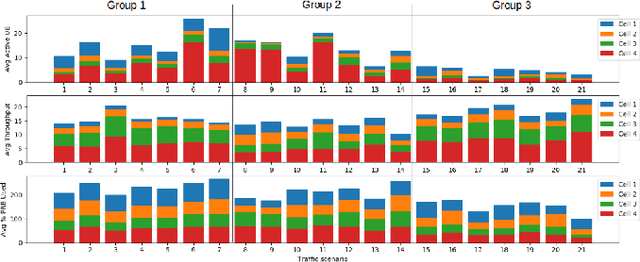
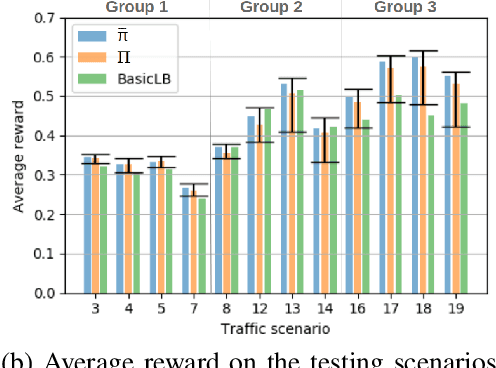
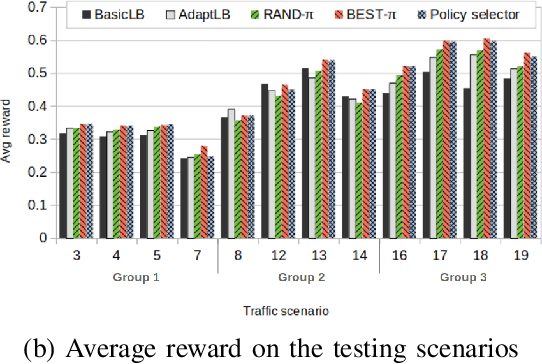
With the continuous growth in communication network complexity and traffic volume, communication load balancing solutions are receiving increasing attention. Specifically, reinforcement learning (RL)-based methods have shown impressive performance compared with traditional rule-based methods. However, standard RL methods generally require an enormous amount of data to train, and generalize poorly to scenarios that are not encountered during training. We propose a policy reuse framework in which a policy selector chooses the most suitable pre-trained RL policy to execute based on the current traffic condition. Our method hinges on a policy bank composed of policies trained on a diverse set of traffic scenarios. When deploying to an unknown traffic scenario, we select a policy from the policy bank based on the similarity between the previous-day traffic of the current scenario and the traffic observed during training. Experiments demonstrate that this framework can outperform classical and adaptive rule-based methods by a large margin.
ModelLight: Model-Based Meta-Reinforcement Learning for Traffic Signal Control
Dec 06, 2021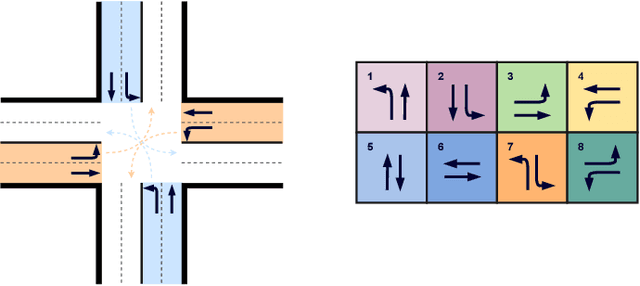
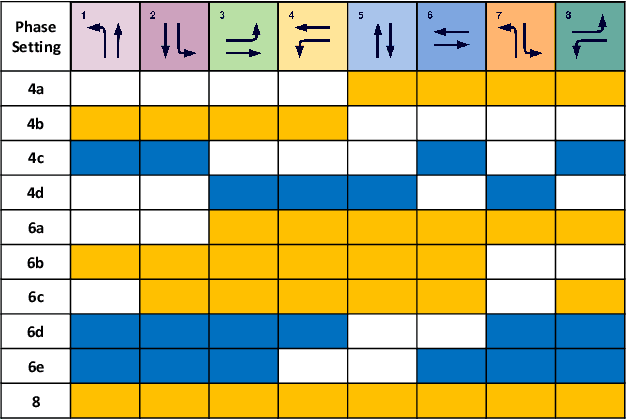
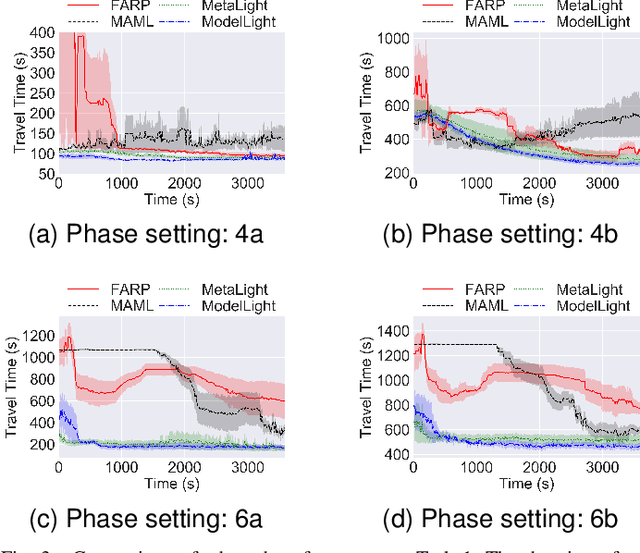
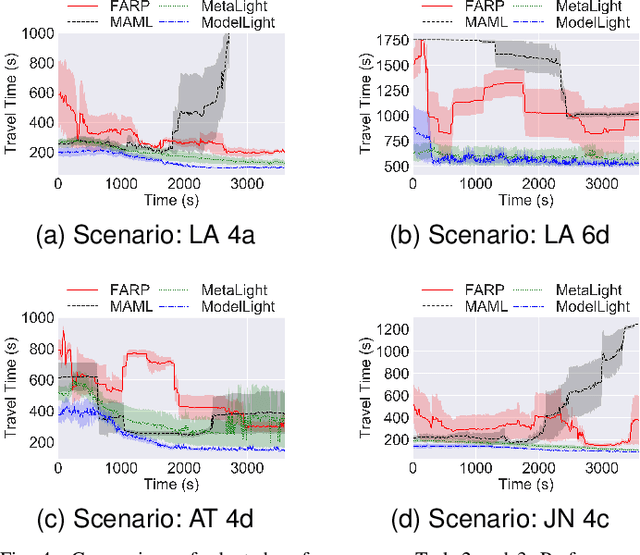
Traffic signal control is of critical importance for the effective use of transportation infrastructures. The rapid increase of vehicle traffic and changes in traffic patterns make traffic signal control more and more challenging. Reinforcement Learning (RL)-based algorithms have demonstrated their potential in dealing with traffic signal control. However, most existing solutions require a large amount of training data, which is unacceptable for many real-world scenarios. This paper proposes a novel model-based meta-reinforcement learning framework (ModelLight) for traffic signal control. Within ModelLight, an ensemble of models for road intersections and the optimization-based meta-learning method are used to improve the data efficiency of an RL-based traffic light control method. Experiments on real-world datasets demonstrate that ModelLight can outperform state-of-the-art traffic light control algorithms while substantially reducing the number of required interactions with the real-world environment.
Learning Intuitive Physics with Multimodal Generative Models
Jan 19, 2021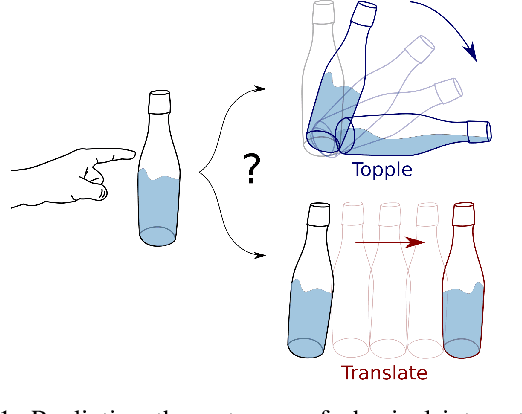
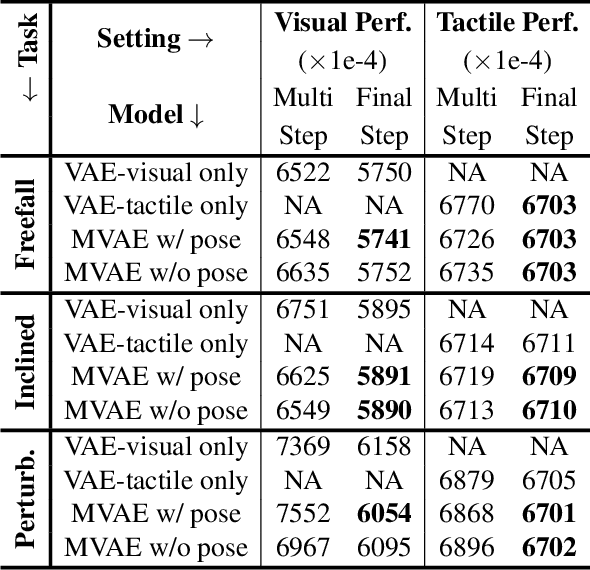

Predicting the future interaction of objects when they come into contact with their environment is key for autonomous agents to take intelligent and anticipatory actions. This paper presents a perception framework that fuses visual and tactile feedback to make predictions about the expected motion of objects in dynamic scenes. Visual information captures object properties such as 3D shape and location, while tactile information provides critical cues about interaction forces and resulting object motion when it makes contact with the environment. Utilizing a novel See-Through-your-Skin (STS) sensor that provides high resolution multimodal sensing of contact surfaces, our system captures both the visual appearance and the tactile properties of objects. We interpret the dual stream signals from the sensor using a Multimodal Variational Autoencoder (MVAE), allowing us to capture both modalities of contacting objects and to develop a mapping from visual to tactile interaction and vice-versa. Additionally, the perceptual system can be used to infer the outcome of future physical interactions, which we validate through simulated and real-world experiments in which the resting state of an object is predicted from given initial conditions.
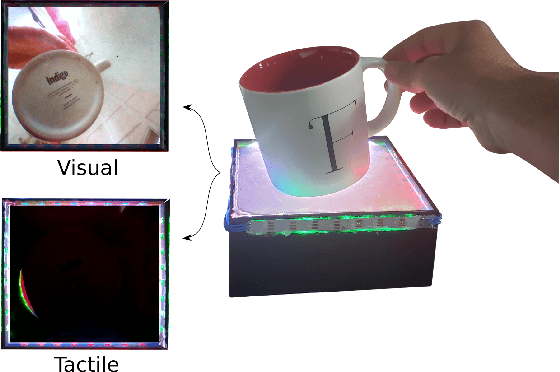
Seeing Through your Skin: Recognizing Objects with a Novel Visuotactile Sensor
Dec 14, 2020
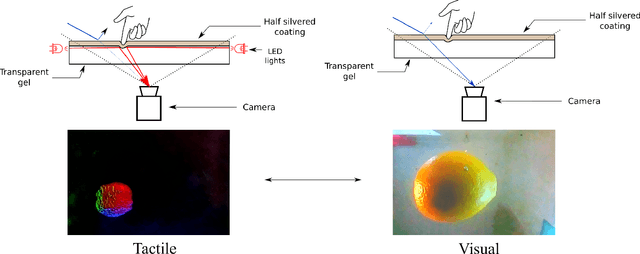
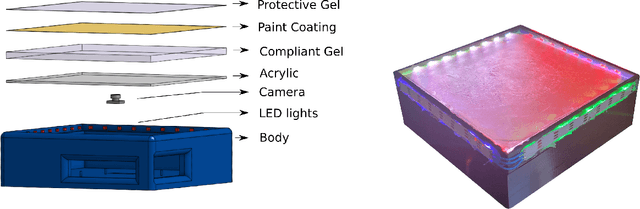
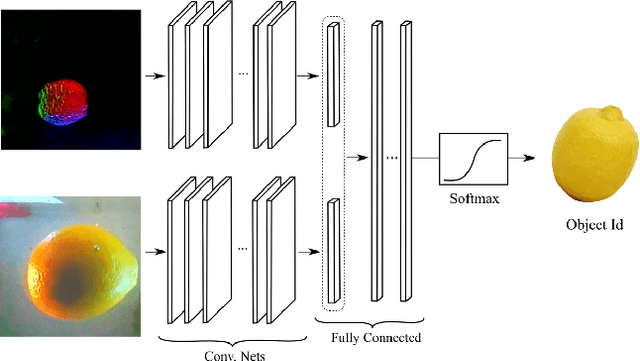
We introduce a new class of vision-based sensor and associated algorithmic processes that combine visual imaging with high-resolution tactile sending, all in a uniform hardware and computational architecture. We demonstrate the sensor's efficacy for both multi-modal object recognition and metrology. Object recognition is typically formulated as an unimodal task, but by combining two sensor modalities we show that we can achieve several significant performance improvements. This sensor, named the See-Through-your-Skin sensor (STS), is designed to provide rich multi-modal sensing of contact surfaces. Inspired by recent developments in optical tactile sensing technology, we address a key missing feature of these sensors: the ability to capture a visual perspective of the region beyond the contact surface. Whereas optical tactile sensors are typically opaque, we present a sensor with a semitransparent skin that has the dual capabilities of acting as a tactile sensor and/or as a visual camera depending on its internal lighting conditions. This paper details the design of the sensor, showcases its dual sensing capabilities, and presents a deep learning architecture that fuses vision and touch. We validate the ability of the sensor to classify household objects, recognize fine textures, and infer their physical properties both through numerical simulations and experiments with a smart countertop prototype.