 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Variable PSO with Fairness on Multi-Objective Field Data Replication in Wireless Networks
Mar 23, 2023



Digital twins have shown a great potential in supporting the development of wireless networks. They are virtual representations of 5G/6G systems enabling the design of machine learning and optimization-based techniques. Field data replication is one of the critical aspects of building a simulation-based twin, where the objective is to calibrate the simulation to match field performance measurements. Since wireless networks involve a variety of key performance indicators (KPIs), the replication process becomes a multi-objective optimization problem in which the purpose is to minimize the error between the simulated and field data KPIs. Unlike previous works, we focus on designing a data-driven search method to calibrate the simulator and achieve accurate and reliable reproduction of field performance. This work proposes a search-based algorithm based on mixedvariable particle swarm optimization (PSO) to find the optimal simulation parameters. Furthermore, we extend this solution to account for potential conflicts between the KPIs using {\alpha}-fairness concept to adjust the importance attributed to each KPI during the search. Experiments on field data showcase the effectiveness of our approach to (i) improve the accuracy of the replication, (ii) enhance the fairness between the different KPIs, and (iii) guarantee faster convergence compared to other methods.
Policy Reuse for Communication Load Balancing in Unseen Traffic Scenarios
Mar 22, 2023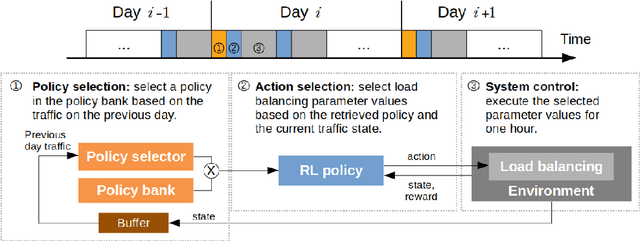
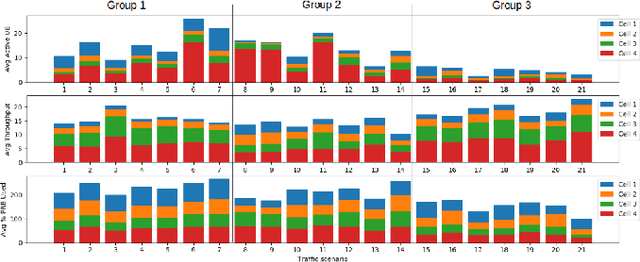
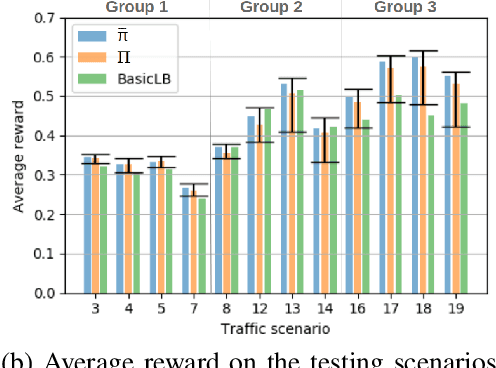
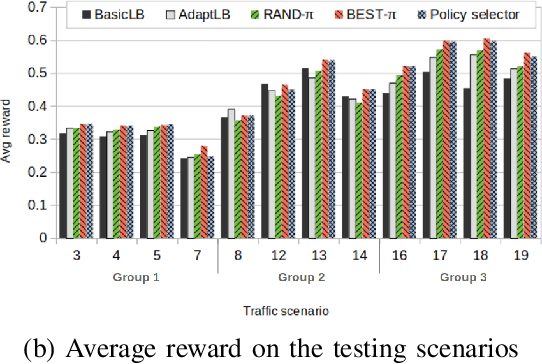
With the continuous growth in communication network complexity and traffic volume, communication load balancing solutions are receiving increasing attention. Specifically, reinforcement learning (RL)-based methods have shown impressive performance compared with traditional rule-based methods. However, standard RL methods generally require an enormous amount of data to train, and generalize poorly to scenarios that are not encountered during training. We propose a policy reuse framework in which a policy selector chooses the most suitable pre-trained RL policy to execute based on the current traffic condition. Our method hinges on a policy bank composed of policies trained on a diverse set of traffic scenarios. When deploying to an unknown traffic scenario, we select a policy from the policy bank based on the similarity between the previous-day traffic of the current scenario and the traffic observed during training. Experiments demonstrate that this framework can outperform classical and adaptive rule-based methods by a large margin.
Communication Load Balancing via Efficient Inverse Reinforcement Learning
Mar 22, 2023
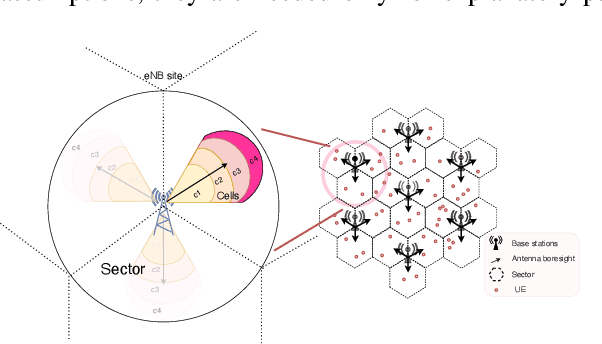
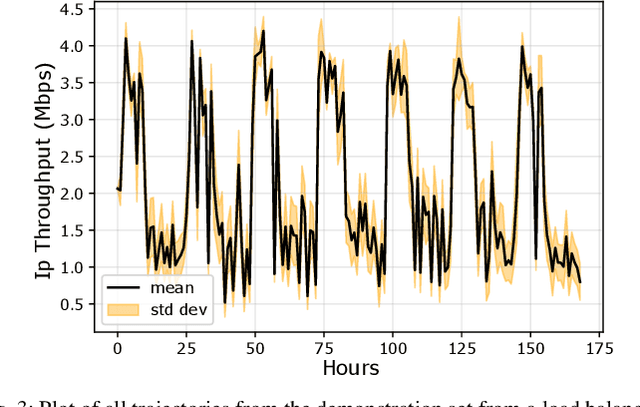
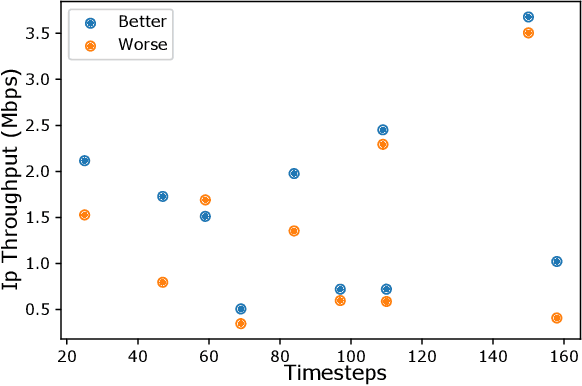
Communication load balancing aims to balance the load between different available resources, and thus improve the quality of service for network systems. After formulating the load balancing (LB) as a Markov decision process problem, reinforcement learning (RL) has recently proven effective in addressing the LB problem. To leverage the benefits of classical RL for load balancing, however, we need an explicit reward definition. Engineering this reward function is challenging, because it involves the need for expert knowledge and there lacks a general consensus on the form of an optimal reward function. In this work, we tackle the communication load balancing problem from an inverse reinforcement learning (IRL) approach. To the best of our knowledge, this is the first time IRL has been successfully applied in the field of communication load balancing. Specifically, first, we infer a reward function from a set of demonstrations, and then learn a reinforcement learning load balancing policy with the inferred reward function. Compared to classical RL-based solution, the proposed solution can be more general and more suitable for real-world scenarios. Experimental evaluations implemented on different simulated traffic scenarios have shown our method to be effective and better than other baselines by a considerable margin.
Generative Design by Reinforcement Learning: Maximizing Diversity of Topology Optimized Designs
Aug 17, 2020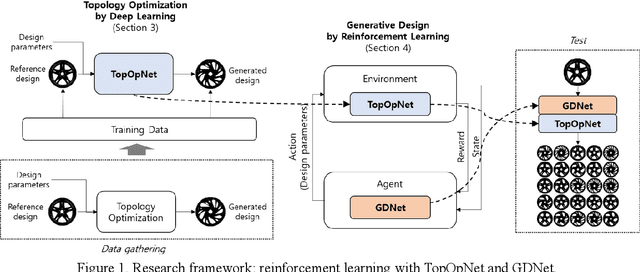
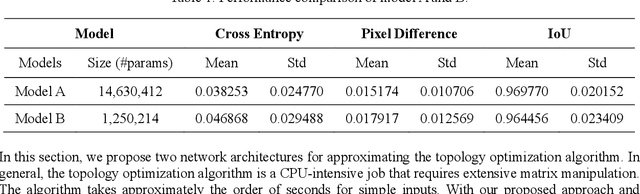
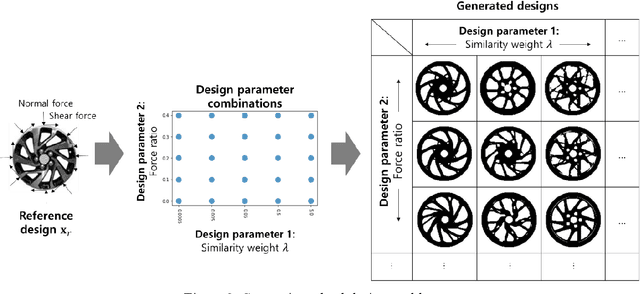

Generative design is a design exploration process in which a large number of structurally optimal designs are generated in parallel by diversifying parameters of the topology optimization while fulfilling certain constraints. Recently, data-driven generative design has gained much attention due to its integration with artificial intelligence (AI) technologies. When generating new designs through a generative approach, one of the important evaluation factors is diversity. In general, the problem definition of topology optimization is diversified by varying the force and boundary conditions, and the diversity of the generated designs is influenced by such parameter combinations. This study proposes a reinforcement learning (RL) based generative design process with reward functions maximizing the diversity of the designs. We formulate the generative design as a sequential problem of finding optimal parameter level values according to a given initial design. Proximal Policy Optimization (PPO) was applied as the learning framework, which is demonstrated in the case study of an automotive wheel design problem. This study also proposes the use of a deep neural network to instantly generate new designs without the topology optimization process, thus reducing the large computational burdens required by reinforcement learning. We show that RL-based generative design produces a large number of diverse designs within a short inference time by exploiting GPU in a fully automated manner. It is different from the previous approach using CPU which takes much more processing time and involving human intervention.