 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorking Backwards: Learning to Place by Picking
Dec 04, 2023



We present Learning to Place by Picking (LPP), a method capable of autonomously collecting demonstrations for a family of placing tasks in which objects must be manipulated to specific locations. With LPP, we approach the learning of robotic object placement policies by reversing the grasping process and exploiting the inherent symmetry of the pick and place problems. Specifically, we obtain placing demonstrations from a set of grasp sequences of objects that are initially located at their target placement locations. Our system is capable of collecting hundreds of demonstrations without human intervention by using a combination of tactile sensing and compliant control for grasps. We train a policy directly from visual observations through behaviour cloning, using the autonomously-collected demonstrations. By doing so, the policy can generalize to object placement scenarios outside of the training environment without privileged information (e.g., placing a plate picked up from a table and not at the original placement location). We validate our approach on home robotic scenarios that include dishwasher loading and table setting. Our approach yields robotic placing policies that outperform policies trained with kinesthetic teaching, both in terms of performance and data efficiency, while requiring no human supervision.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
Mixed-Variable PSO with Fairness on Multi-Objective Field Data Replication in Wireless Networks
Mar 23, 2023



Digital twins have shown a great potential in supporting the development of wireless networks. They are virtual representations of 5G/6G systems enabling the design of machine learning and optimization-based techniques. Field data replication is one of the critical aspects of building a simulation-based twin, where the objective is to calibrate the simulation to match field performance measurements. Since wireless networks involve a variety of key performance indicators (KPIs), the replication process becomes a multi-objective optimization problem in which the purpose is to minimize the error between the simulated and field data KPIs. Unlike previous works, we focus on designing a data-driven search method to calibrate the simulator and achieve accurate and reliable reproduction of field performance. This work proposes a search-based algorithm based on mixedvariable particle swarm optimization (PSO) to find the optimal simulation parameters. Furthermore, we extend this solution to account for potential conflicts between the KPIs using {\alpha}-fairness concept to adjust the importance attributed to each KPI during the search. Experiments on field data showcase the effectiveness of our approach to (i) improve the accuracy of the replication, (ii) enhance the fairness between the different KPIs, and (iii) guarantee faster convergence compared to other methods.
Communication Load Balancing via Efficient Inverse Reinforcement Learning
Mar 22, 2023
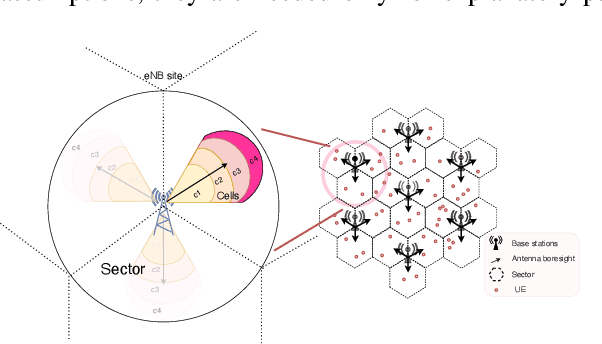
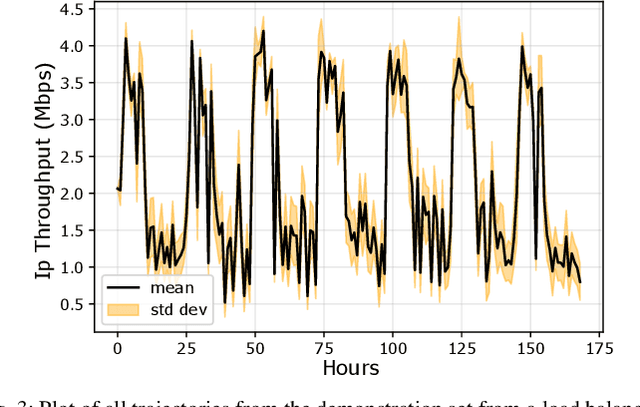
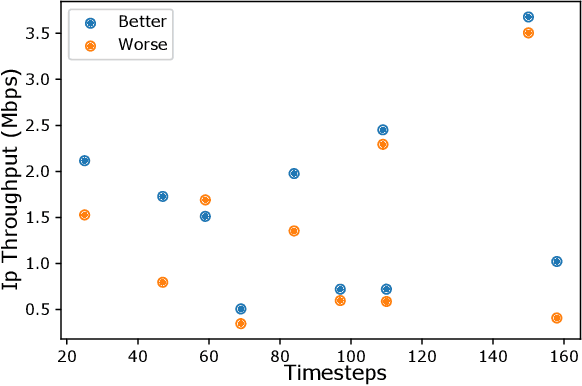
Communication load balancing aims to balance the load between different available resources, and thus improve the quality of service for network systems. After formulating the load balancing (LB) as a Markov decision process problem, reinforcement learning (RL) has recently proven effective in addressing the LB problem. To leverage the benefits of classical RL for load balancing, however, we need an explicit reward definition. Engineering this reward function is challenging, because it involves the need for expert knowledge and there lacks a general consensus on the form of an optimal reward function. In this work, we tackle the communication load balancing problem from an inverse reinforcement learning (IRL) approach. To the best of our knowledge, this is the first time IRL has been successfully applied in the field of communication load balancing. Specifically, first, we infer a reward function from a set of demonstrations, and then learn a reinforcement learning load balancing policy with the inferred reward function. Compared to classical RL-based solution, the proposed solution can be more general and more suitable for real-world scenarios. Experimental evaluations implemented on different simulated traffic scenarios have shown our method to be effective and better than other baselines by a considerable margin.