 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIDER: Scalable Physics-Informed Dexterous Retargeting
Nov 12, 2025Learning dexterous and agile policy for humanoid and dexterous hand control requires large-scale demonstrations, but collecting robot-specific data is prohibitively expensive. In contrast, abundant human motion data is readily available from motion capture, videos, and virtual reality, which could help address the data scarcity problem. However, due to the embodiment gap and missing dynamic information like force and torque, these demonstrations cannot be directly executed on robots. To bridge this gap, we propose Scalable Physics-Informed DExterous Retargeting (SPIDER), a physics-based retargeting framework to transform and augment kinematic-only human demonstrations to dynamically feasible robot trajectories at scale. Our key insight is that human demonstrations should provide global task structure and objective, while large-scale physics-based sampling with curriculum-style virtual contact guidance should refine trajectories to ensure dynamical feasibility and correct contact sequences. SPIDER scales across diverse 9 humanoid/dexterous hand embodiments and 6 datasets, improving success rates by 18% compared to standard sampling, while being 10X faster than reinforcement learning (RL) baselines, and enabling the generation of a 2.4M frames dynamic-feasible robot dataset for policy learning. As a universal physics-based retargeting method, SPIDER can work with diverse quality data and generate diverse and high-quality data to enable efficient policy learning with methods like RL.
DexterityGen: Foundation Controller for Unprecedented Dexterity
Feb 06, 2025



Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.
PEOPLEx: PEdestrian Opportunistic Positioning LEveraging IMU, UWB, BLE and WiFi
Nov 30, 2023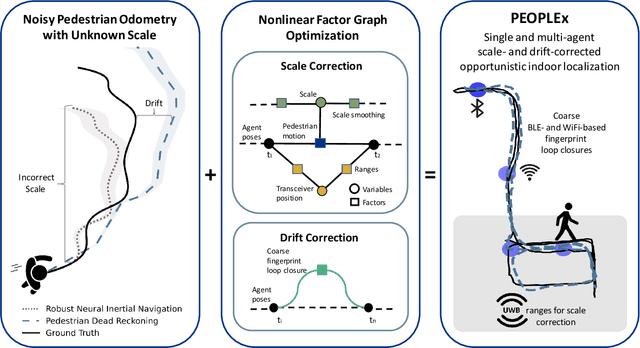
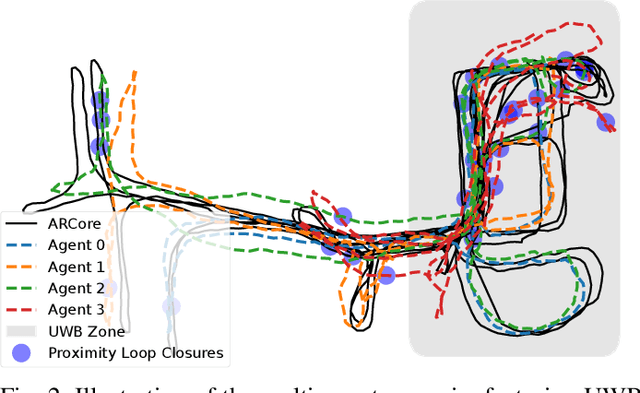
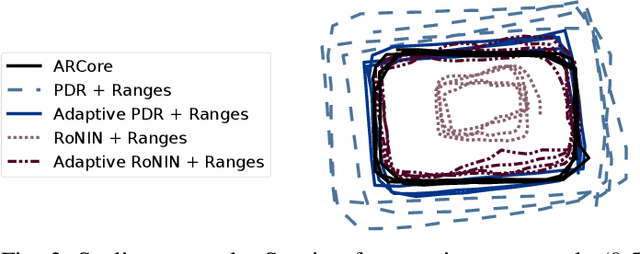
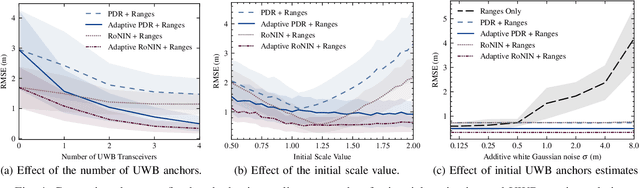
This paper advances the field of pedestrian localization by introducing a unifying framework for opportunistic positioning based on nonlinear factor graph optimization. While many existing approaches assume constant availability of one or multiple sensing signals, our methodology employs IMU-based pedestrian inertial navigation as the backbone for sensor fusion, opportunistically integrating Ultra-Wideband (UWB), Bluetooth Low Energy (BLE), and WiFi signals when they are available in the environment. The proposed PEOPLEx framework is designed to incorporate sensing data as it becomes available, operating without any prior knowledge about the environment (e.g. anchor locations, radio frequency maps, etc.). Our contributions are twofold: 1) we introduce an opportunistic multi-sensor and real-time pedestrian positioning framework fusing the available sensor measurements; 2) we develop novel factors for adaptive scaling and coarse loop closures, significantly improving the precision of indoor positioning. Experimental validation confirms that our approach achieves accurate localization estimates in real indoor scenarios using commercial smartphones.
Learning active tactile perception through belief-space control
Nov 30, 2023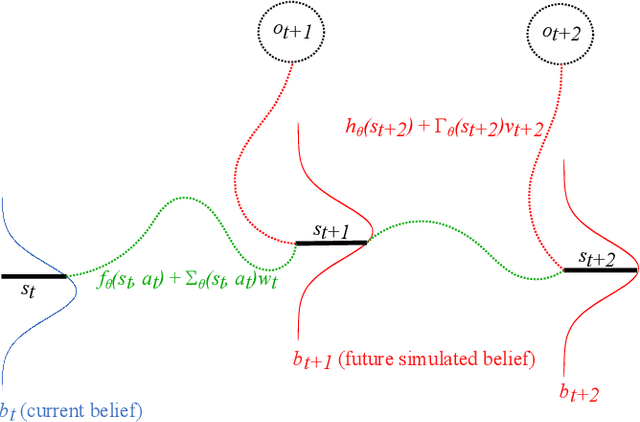



Robots operating in an open world will encounter novel objects with unknown physical properties, such as mass, friction, or size. These robots will need to sense these properties through interaction prior to performing downstream tasks with the objects. We propose a method that autonomously learns tactile exploration policies by developing a generative world model that is leveraged to 1) estimate the object's physical parameters using a differentiable Bayesian filtering algorithm and 2) develop an exploration policy using an information-gathering model predictive controller. We evaluate our method on three simulated tasks where the goal is to estimate a desired object property (mass, height or toppling height) through physical interaction. We find that our method is able to discover policies that efficiently gather information about the desired property in an intuitive manner. Finally, we validate our method on a real robot system for the height estimation task, where our method is able to successfully learn and execute an information-gathering policy from scratch.
Generalizable Imitation Learning Through Pre-Trained Representations
Nov 15, 2023



In this paper we leverage self-supervised vision transformer models and their emergent semantic abilities to improve the generalization abilities of imitation learning policies. We introduce BC-ViT, an imitation learning algorithm that leverages rich DINO pre-trained Visual Transformer (ViT) patch-level embeddings to obtain better generalization when learning through demonstrations. Our learner sees the world by clustering appearance features into semantic concepts, forming stable keypoints that generalize across a wide range of appearance variations and object types. We show that this representation enables generalized behaviour by evaluating imitation learning across a diverse dataset of object manipulation tasks. Our method, data and evaluation approach are made available to facilitate further study of generalization in Imitation Learners.
Push it to the Demonstrated Limit: Multimodal Visuotactile Imitation Learning with Force Matching
Nov 02, 2023
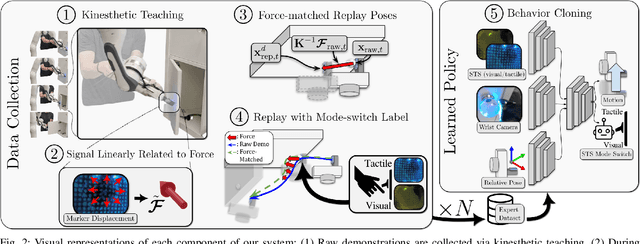
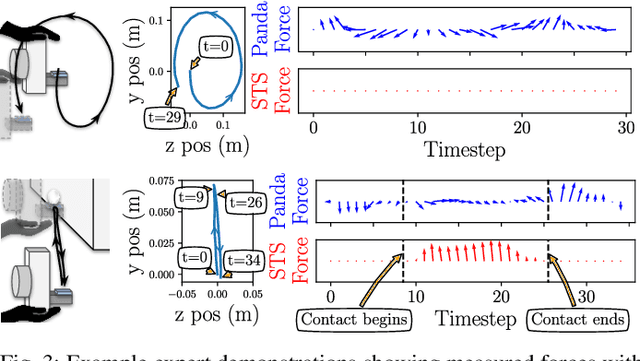
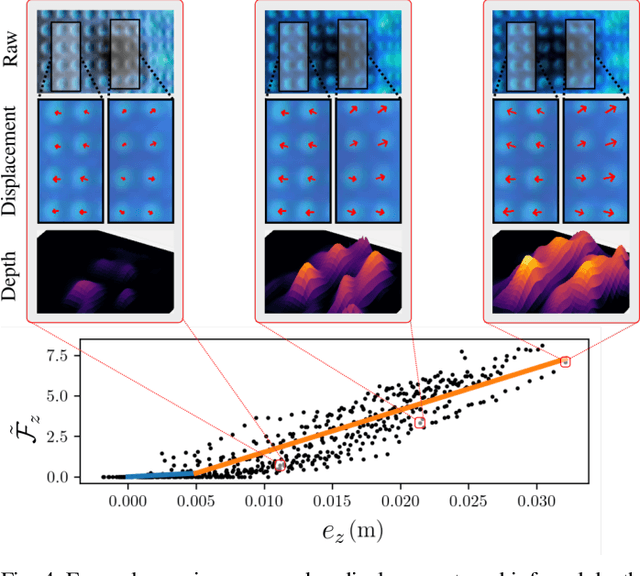
Optical tactile sensors have emerged as an effective means to acquire dense contact information during robotic manipulation. A recently-introduced `see-through-your-skin' (STS) variant of this type of sensor has both visual and tactile modes, enabled by leveraging a semi-transparent surface and controllable lighting. In this work, we investigate the benefits of pairing visuotactile sensing with imitation learning for contact-rich manipulation tasks. First, we use tactile force measurements and a novel algorithm during kinesthetic teaching to yield a force profile that better matches that of the human demonstrator. Second, we add visual/tactile STS mode switching as a control policy output, simplifying the application of the sensor. Finally, we study multiple observation configurations to compare and contrast the value of visual/tactile data (both with and without mode switching) with visual data from a wrist-mounted eye-in-hand camera. We perform an extensive series of experiments on a real robotic manipulator with door-opening and closing tasks, including over 3,000 real test episodes. Our results highlight the importance of tactile sensing for imitation learning, both for data collection to allow force matching, and for policy execution to allow accurate task feedback.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
CARTIER: Cartographic lAnguage Reasoning Targeted at Instruction Execution for Robots
Jul 21, 2023This work explores the capacity of large language models (LLMs) to address problems at the intersection of spatial planning and natural language interfaces for navigation.Our focus is on following relatively complex instructions that are more akin to natural conversation than traditional explicit procedural directives seen in robotics. Unlike most prior work, where navigation directives are provided as imperative commands (e.g., go to the fridge), we examine implicit directives within conversational interactions. We leverage the 3D simulator AI2Thor to create complex and repeatable scenarios at scale, and augment it by adding complex language queries for 40 object types. We demonstrate that a robot can better parse descriptive language queries than existing methods by using an LLM to interpret the user interaction in the context of a list of the objects in the scene.
ANSEL Photobot: A Robot Event Photographer with Semantic Intelligence
Feb 15, 2023
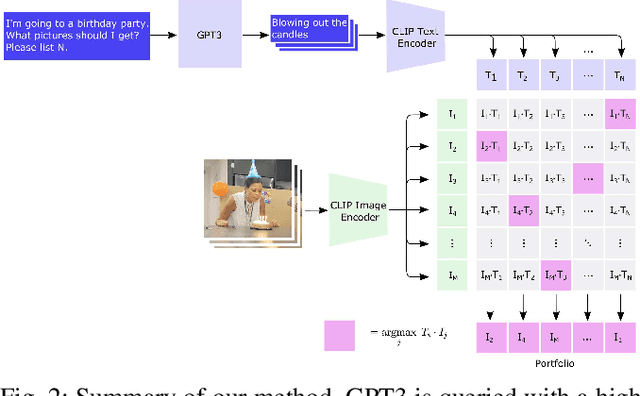

Our work examines the way in which large language models can be used for robotic planning and sampling, specifically the context of automated photographic documentation. Specifically, we illustrate how to produce a photo-taking robot with an exceptional level of semantic awareness by leveraging recent advances in general purpose language (LM) and vision-language (VLM) models. Given a high-level description of an event we use an LM to generate a natural-language list of photo descriptions that one would expect a photographer to capture at the event. We then use a VLM to identify the best matches to these descriptions in the robot's video stream. The photo portfolios generated by our method are consistently rated as more appropriate to the event by human evaluators than those generated by existing methods.