 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruckDrive: Long-Range Autonomous Highway Driving Dataset
Mar 02, 2026Safe highway autonomy for heavy trucks remains an open and unsolved challenge: due to long braking distances, scene understanding of hundreds of meters is required for anticipatory planning and to allow safe braking margins. However, existing driving datasets primarily cover urban scenes, with perception effectively limited to short ranges of only up to 100 meters. To address this gap, we introduce TruckDrive, a highway-scale multimodal driving dataset, captured with a sensor suite purpose-built for long range sensing: seven long-range FMCW LiDARs measuring range and radial velocity, three high-resolution short-range LiDARs, eleven 8MP surround cameras with varying focal lengths and ten 4D FMCW radars. The dataset offers 475 thousands samples with 165 thousands densely annotated frames for driving perception benchmarking up to 1,000 meters for 2D detection and 400 meters for 3D detection, depth estimation, tracking, planning and end to end driving over 20 seconds sequences at highway speeds. We find that state-of-the-art autonomous driving models do not generalize to ranges beyond 150 meters, with drops between 31% and 99% in 3D perception tasks, exposing a systematic long-range gap that current architectures and training signals cannot close.
Ergodic Generative Flows
May 06, 2025



Generative Flow Networks (GFNs) were initially introduced on directed acyclic graphs to sample from an unnormalized distribution density. Recent works have extended the theoretical framework for generative methods allowing more flexibility and enhancing application range. However, many challenges remain in training GFNs in continuous settings and for imitation learning (IL), including intractability of flow-matching loss, limited tests of non-acyclic training, and the need for a separate reward model in imitation learning. The present work proposes a family of generative flows called Ergodic Generative Flows (EGFs) which are used to address the aforementioned issues. First, we leverage ergodicity to build simple generative flows with finitely many globally defined transformations (diffeomorphisms) with universality guarantees and tractable flow-matching loss (FM loss). Second, we introduce a new loss involving cross-entropy coupled to weak flow-matching control, coined KL-weakFM loss. It is designed for IL training without a separate reward model. We evaluate IL-EGFs on toy 2D tasks and real-world datasets from NASA on the sphere, using the KL-weakFM loss. Additionally, we conduct toy 2D reinforcement learning experiments with a target reward, using the FM loss.
Push it to the Demonstrated Limit: Multimodal Visuotactile Imitation Learning with Force Matching
Nov 02, 2023
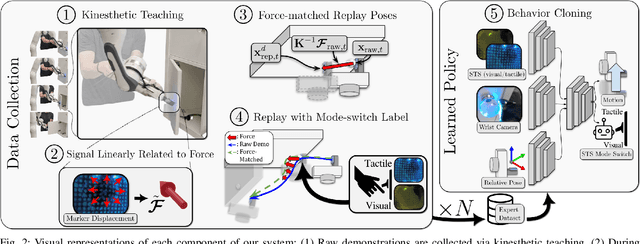
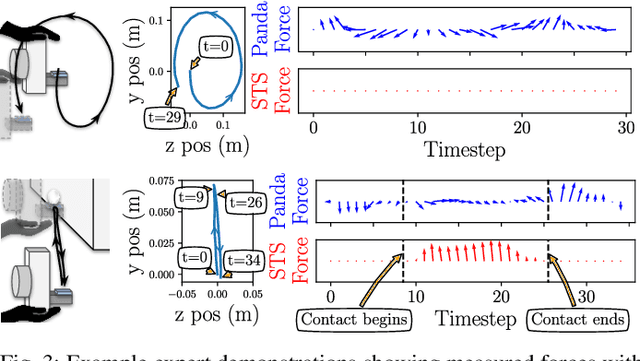
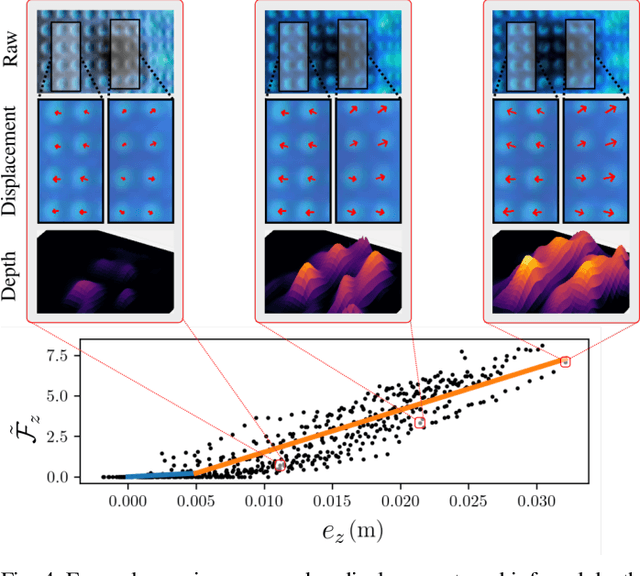
Optical tactile sensors have emerged as an effective means to acquire dense contact information during robotic manipulation. A recently-introduced `see-through-your-skin' (STS) variant of this type of sensor has both visual and tactile modes, enabled by leveraging a semi-transparent surface and controllable lighting. In this work, we investigate the benefits of pairing visuotactile sensing with imitation learning for contact-rich manipulation tasks. First, we use tactile force measurements and a novel algorithm during kinesthetic teaching to yield a force profile that better matches that of the human demonstrator. Second, we add visual/tactile STS mode switching as a control policy output, simplifying the application of the sensor. Finally, we study multiple observation configurations to compare and contrast the value of visual/tactile data (both with and without mode switching) with visual data from a wrist-mounted eye-in-hand camera. We perform an extensive series of experiments on a real robotic manipulator with door-opening and closing tasks, including over 3,000 real test episodes. Our results highlight the importance of tactile sensing for imitation learning, both for data collection to allow force matching, and for policy execution to allow accurate task feedback.
SAGE: Smart home Agent with Grounded Execution
Nov 01, 2023This article introduces SAGE (Smart home Agent with Grounded Execution), a framework designed to maximize the flexibility of smart home assistants by replacing manually-defined inference logic with an LLM-powered autonomous agent system. SAGE integrates information about user preferences, device states, and external factors (such as weather and TV schedules) through the orchestration of a collection of tools. SAGE's capabilities include learning user preferences from natural-language utterances, interacting with devices by reading their API documentation, writing code to continuously monitor devices, and understanding natural device references. To evaluate SAGE, we develop a benchmark of 43 highly challenging smart home tasks, where SAGE successfully achieves 23 tasks, significantly outperforming existing LLM-enabled baselines (5/43).
Improving Reinforcement Learning Training Regimes for Social Robot Navigation
Aug 29, 2023

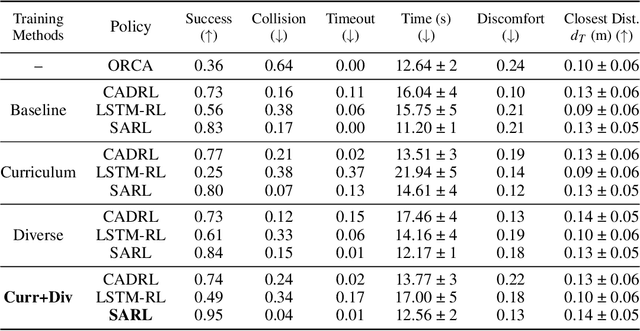

In order for autonomous mobile robots to navigate in human spaces, they must abide by our social norms. Reinforcement learning (RL) has emerged as an effective method to train robot navigation policies that are able to respect these norms. However, a large portion of existing work in the field conducts both RL training and testing in simplistic environments. This limits the generalization potential of these models to unseen environments, and the meaningfulness of their reported results. We propose a method to improve the generalization performance of RL social navigation methods using curriculum learning. By employing multiple environment types and by modeling pedestrians using multiple dynamics models, we are able to progressively diversify and escalate difficulty in training. Our results show that the use of curriculum learning in training can be used to achieve better generalization performance than previous training methods. We also show that results presented in many existing state-of-the art RL social navigation works do not evaluate their methods outside of their training environments, and thus do not reflect their policies' failure to adequately generalize to out-of-distribution scenarios. In response, we validate our training approach on larger and more crowded testing environments than those used in training, allowing for more meaningful measurements of model performance.