 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow VLAs (Really) Work In Open-World Environments
Apr 23, 2026Vision-language-action models (VLAs) have been extensively used in robotics applications, achieving great success in various manipulation problems. More recently, VLAs have been used in long-horizon tasks and evaluated on benchmarks, such as BEHAVIOR1K (B1K), for solving complex household chores. The common metric for measuring progress in such benchmarks is success rate or partial score based on satisfaction of progress-agnostic criteria, meaning only the final states of the objects are considered, regardless of the events that lead to such states. In this paper, we argue that using such evaluation protocols say little about safety aspects of operation and can potentially exaggerate reported performance, undermining core challenges for future real-world deployment. To this end, we conduct a thorough analysis of state-of-the-art models on the B1K Challenge and evaluate policies in terms of robustness via reproducibility and consistency of performance, safety aspects of policies operations, task awareness, and key elements leading to the incompletion of tasks. We then propose evaluation protocols to capture safety violations to better measure the true performance of the policies in more complex and interactive scenarios. At the end, we discuss the limitations of the existing VLAs and motivate future research.
Do World Action Models Generalize Better than VLAs? A Robustness Study
Mar 23, 2026Robot action planning in the real world is challenging as it requires not only understanding the current state of the environment but also predicting how it will evolve in response to actions. Vision-language-action (VLA), which repurpose large-scale vision-language models for robot action generation using action experts, have achieved notable success across a variety of robotic tasks. Nevertheless, their performance remains constrained by the scope of their training data, exhibiting limited generalization to unseen scenarios and vulnerability to diverse contextual perturbations. More recently, world models have been revisited as an alternative to VLAs. These models, referred to as world action models (WAMs), are built upon world models that are trained on large corpora of video data to predict future states. With minor adaptations, their latent representation can be decoded into robot actions. It has been suggested that their explicit dynamic prediction capacity, combined with spatiotemporal priors acquired from web-scale video pretraining, enables WAMs to generalize more effectively than VLAs. In this paper, we conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations. Our results show that WAMs achieve strong robustness, with LingBot-VA reaching 74.2% success rate on RoboTwin 2.0-Plus and Cosmos-Policy achieving 82.2% on LIBERO-Plus. While VLAs such as $π_{0.5}$ can achieve comparable robustness on certain tasks, they typically require extensive training with diverse robotic datasets and varied learning objectives. Hybrid approaches that partially incorporate video-based dynamic learning exhibit intermediate robustness, highlighting the importance of how video priors are integrated.
Ergodic Generative Flows
May 06, 2025



Generative Flow Networks (GFNs) were initially introduced on directed acyclic graphs to sample from an unnormalized distribution density. Recent works have extended the theoretical framework for generative methods allowing more flexibility and enhancing application range. However, many challenges remain in training GFNs in continuous settings and for imitation learning (IL), including intractability of flow-matching loss, limited tests of non-acyclic training, and the need for a separate reward model in imitation learning. The present work proposes a family of generative flows called Ergodic Generative Flows (EGFs) which are used to address the aforementioned issues. First, we leverage ergodicity to build simple generative flows with finitely many globally defined transformations (diffeomorphisms) with universality guarantees and tractable flow-matching loss (FM loss). Second, we introduce a new loss involving cross-entropy coupled to weak flow-matching control, coined KL-weakFM loss. It is designed for IL training without a separate reward model. We evaluate IL-EGFs on toy 2D tasks and real-world datasets from NASA on the sphere, using the KL-weakFM loss. Additionally, we conduct toy 2D reinforcement learning experiments with a target reward, using the FM loss.
RA-DP: Rapid Adaptive Diffusion Policy for Training-Free High-frequency Robotics Replanning
Mar 06, 2025



Diffusion models exhibit impressive scalability in robotic task learning, yet they struggle to adapt to novel, highly dynamic environments. This limitation primarily stems from their constrained replanning ability: they either operate at a low frequency due to a time-consuming iterative sampling process, or are unable to adapt to unforeseen feedback in case of rapid replanning. To address these challenges, we propose RA-DP, a novel diffusion policy framework with training-free high-frequency replanning ability that solves the above limitations in adapting to unforeseen dynamic environments. Specifically, our method integrates guidance signals which are often easily obtained in the new environment during the diffusion sampling process, and utilizes a novel action queue mechanism to generate replanned actions at every denoising step without retraining, thus forming a complete training-free framework for robot motion adaptation in unseen environments. Extensive evaluations have been conducted in both well-recognized simulation benchmarks and real robot tasks. Results show that RA-DP outperforms the state-of-the-art diffusion-based methods in terms of replanning frequency and success rate. Moreover, we show that our framework is theoretically compatible with any training-free guidance signal.
DenseShift: Towards Accurate and Transferable Low-Bit Shift Network
Aug 20, 2022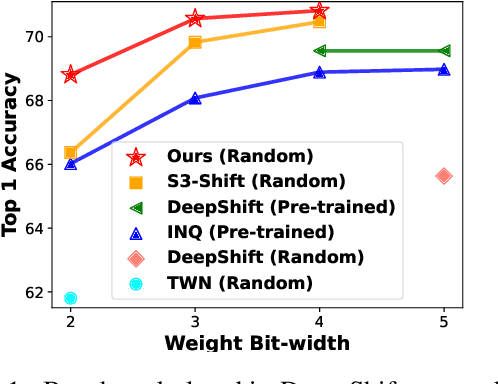
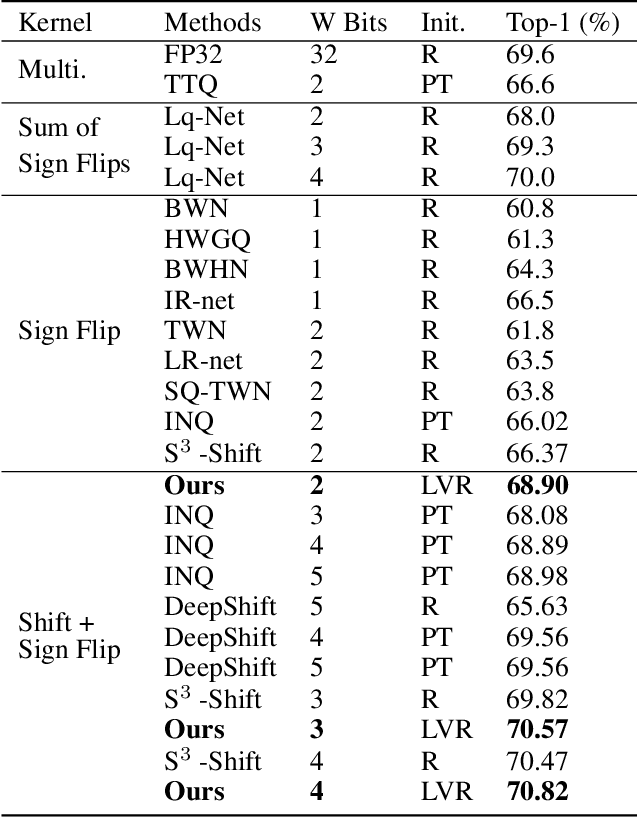
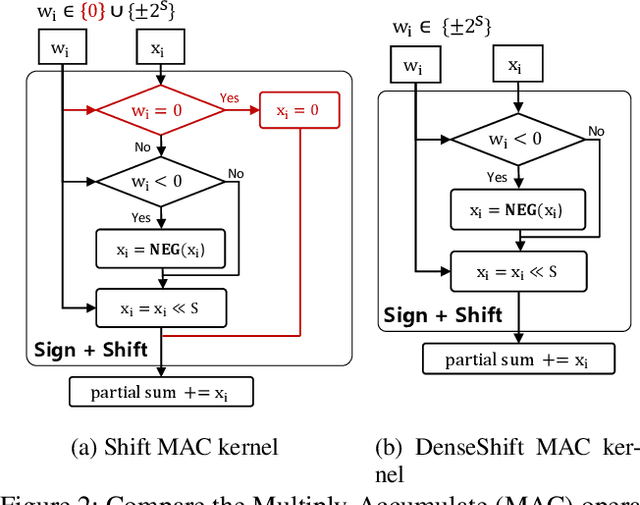
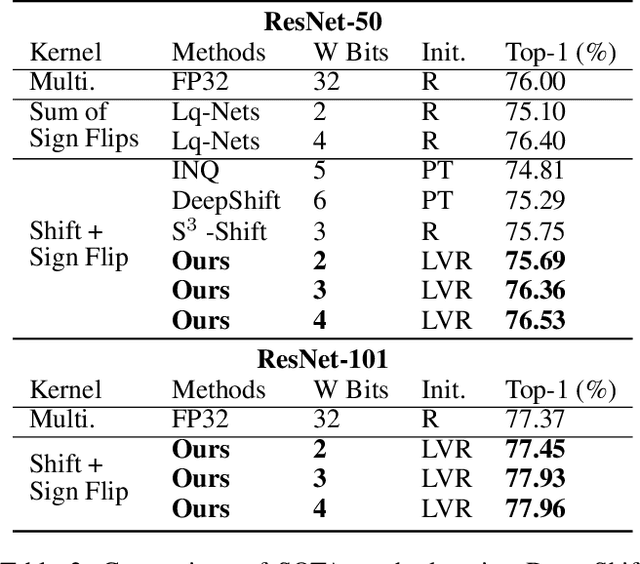
Deploying deep neural networks on low-resource edge devices is challenging due to their ever-increasing resource requirements. Recent investigations propose multiplication-free neural networks to reduce computation and memory consumption. Shift neural network is one of the most effective tools towards these reductions. However, existing low-bit shift networks are not as accurate as their full precision counterparts and cannot efficiently transfer to a wide range of tasks due to their inherent design flaws. We propose DenseShift network that exploits the following novel designs. First, we demonstrate that the zero-weight values in low-bit shift networks are neither useful to the model capacity nor simplify the model inference. Therefore, we propose to use a zero-free shifting mechanism to simplify inference while increasing the model capacity. Second, we design a new metric to measure the weight freezing issue in training low-bit shift networks, and propose a sign-scale decomposition to improve the training efficiency. Third, we propose the low-variance random initialization strategy to improve the model's performance in transfer learning scenarios. We run extensive experiments on various computer vision and speech tasks. The experimental results show that DenseShift network significantly outperforms existing low-bit multiplication-free networks and can achieve competitive performance to the full-precision counterpart. It also exhibits strong transfer learning performance with no drop in accuracy.
Low-bit Shift Network for End-to-End Spoken Language Understanding
Jul 15, 2022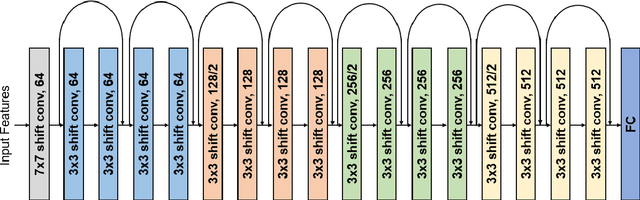
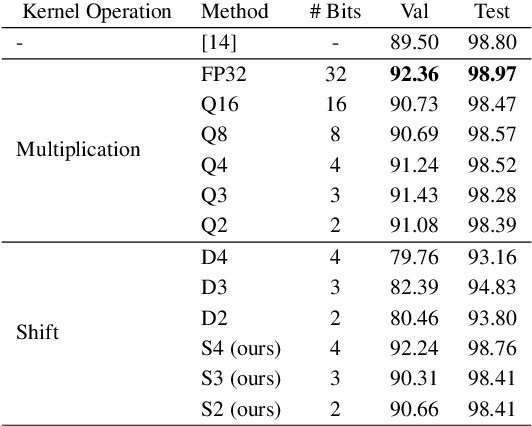
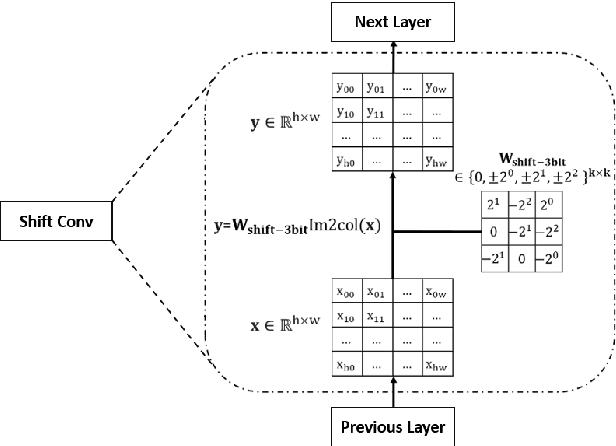
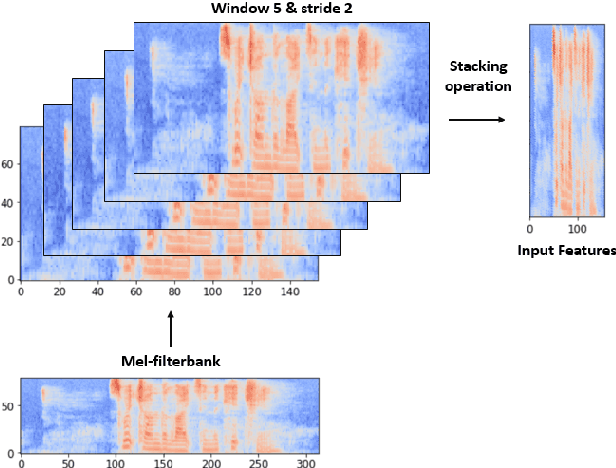
Deep neural networks (DNN) have achieved impressive success in multiple domains. Over the years, the accuracy of these models has increased with the proliferation of deeper and more complex architectures. Thus, state-of-the-art solutions are often computationally expensive, which makes them unfit to be deployed on edge computing platforms. In order to mitigate the high computation, memory, and power requirements of inferring convolutional neural networks (CNNs), we propose the use of power-of-two quantization, which quantizes continuous parameters into low-bit power-of-two values. This reduces computational complexity by removing expensive multiplication operations and with the use of low-bit weights. ResNet is adopted as the building block of our solution and the proposed model is evaluated on a spoken language understanding (SLU) task. Experimental results show improved performance for shift neural network architectures, with our low-bit quantization achieving 98.76 \% on the test set which is comparable performance to its full-precision counterpart and state-of-the-art solutions.
Tensor train decompositions on recurrent networks
Jun 09, 2020


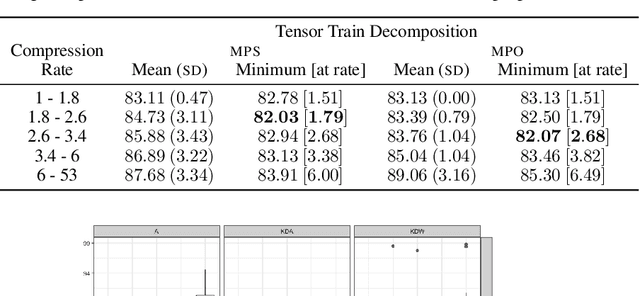
Recurrent neural networks (RNN) such as long-short-term memory (LSTM) networks are essential in a multitude of daily live tasks such as speech, language, video, and multimodal learning. The shift from cloud to edge computation intensifies the need to contain the growth of RNN parameters. Current research on RNN shows that despite the performance obtained on convolutional neural networks (CNN), keeping a good performance in compressed RNNs is still a challenge. Most of the literature on compression focuses on CNNs using matrix product (MPO) operator tensor trains. However, matrix product state (MPS) tensor trains have more attractive features than MPOs, in terms of storage reduction and computing time at inference. We show that MPS tensor trains should be at the forefront of LSTM network compression through a theoretical analysis and practical experiments on NLP task.