 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow VLAs (Really) Work In Open-World Environments
Apr 23, 2026Vision-language-action models (VLAs) have been extensively used in robotics applications, achieving great success in various manipulation problems. More recently, VLAs have been used in long-horizon tasks and evaluated on benchmarks, such as BEHAVIOR1K (B1K), for solving complex household chores. The common metric for measuring progress in such benchmarks is success rate or partial score based on satisfaction of progress-agnostic criteria, meaning only the final states of the objects are considered, regardless of the events that lead to such states. In this paper, we argue that using such evaluation protocols say little about safety aspects of operation and can potentially exaggerate reported performance, undermining core challenges for future real-world deployment. To this end, we conduct a thorough analysis of state-of-the-art models on the B1K Challenge and evaluate policies in terms of robustness via reproducibility and consistency of performance, safety aspects of policies operations, task awareness, and key elements leading to the incompletion of tasks. We then propose evaluation protocols to capture safety violations to better measure the true performance of the policies in more complex and interactive scenarios. At the end, we discuss the limitations of the existing VLAs and motivate future research.
Do World Action Models Generalize Better than VLAs? A Robustness Study
Mar 23, 2026Robot action planning in the real world is challenging as it requires not only understanding the current state of the environment but also predicting how it will evolve in response to actions. Vision-language-action (VLA), which repurpose large-scale vision-language models for robot action generation using action experts, have achieved notable success across a variety of robotic tasks. Nevertheless, their performance remains constrained by the scope of their training data, exhibiting limited generalization to unseen scenarios and vulnerability to diverse contextual perturbations. More recently, world models have been revisited as an alternative to VLAs. These models, referred to as world action models (WAMs), are built upon world models that are trained on large corpora of video data to predict future states. With minor adaptations, their latent representation can be decoded into robot actions. It has been suggested that their explicit dynamic prediction capacity, combined with spatiotemporal priors acquired from web-scale video pretraining, enables WAMs to generalize more effectively than VLAs. In this paper, we conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations. Our results show that WAMs achieve strong robustness, with LingBot-VA reaching 74.2% success rate on RoboTwin 2.0-Plus and Cosmos-Policy achieving 82.2% on LIBERO-Plus. While VLAs such as $π_{0.5}$ can achieve comparable robustness on certain tasks, they typically require extensive training with diverse robotic datasets and varied learning objectives. Hybrid approaches that partially incorporate video-based dynamic learning exhibit intermediate robustness, highlighting the importance of how video priors are integrated.
Ergodic Generative Flows
May 06, 2025



Generative Flow Networks (GFNs) were initially introduced on directed acyclic graphs to sample from an unnormalized distribution density. Recent works have extended the theoretical framework for generative methods allowing more flexibility and enhancing application range. However, many challenges remain in training GFNs in continuous settings and for imitation learning (IL), including intractability of flow-matching loss, limited tests of non-acyclic training, and the need for a separate reward model in imitation learning. The present work proposes a family of generative flows called Ergodic Generative Flows (EGFs) which are used to address the aforementioned issues. First, we leverage ergodicity to build simple generative flows with finitely many globally defined transformations (diffeomorphisms) with universality guarantees and tractable flow-matching loss (FM loss). Second, we introduce a new loss involving cross-entropy coupled to weak flow-matching control, coined KL-weakFM loss. It is designed for IL training without a separate reward model. We evaluate IL-EGFs on toy 2D tasks and real-world datasets from NASA on the sphere, using the KL-weakFM loss. Additionally, we conduct toy 2D reinforcement learning experiments with a target reward, using the FM loss.
RA-DP: Rapid Adaptive Diffusion Policy for Training-Free High-frequency Robotics Replanning
Mar 06, 2025



Diffusion models exhibit impressive scalability in robotic task learning, yet they struggle to adapt to novel, highly dynamic environments. This limitation primarily stems from their constrained replanning ability: they either operate at a low frequency due to a time-consuming iterative sampling process, or are unable to adapt to unforeseen feedback in case of rapid replanning. To address these challenges, we propose RA-DP, a novel diffusion policy framework with training-free high-frequency replanning ability that solves the above limitations in adapting to unforeseen dynamic environments. Specifically, our method integrates guidance signals which are often easily obtained in the new environment during the diffusion sampling process, and utilizes a novel action queue mechanism to generate replanned actions at every denoising step without retraining, thus forming a complete training-free framework for robot motion adaptation in unseen environments. Extensive evaluations have been conducted in both well-recognized simulation benchmarks and real robot tasks. Results show that RA-DP outperforms the state-of-the-art diffusion-based methods in terms of replanning frequency and success rate. Moreover, we show that our framework is theoretically compatible with any training-free guidance signal.
Getting SMARTER for Motion Planning in Autonomous Driving Systems
Feb 20, 2025



Motion planning is a fundamental problem in autonomous driving and perhaps the most challenging to comprehensively evaluate because of the associated risks and expenses of real-world deployment. Therefore, simulations play an important role in efficient development of planning algorithms. To be effective, simulations must be accurate and realistic, both in terms of dynamics and behavior modeling, and also highly customizable in order to accommodate a broad spectrum of research frameworks. In this paper, we introduce SMARTS 2.0, the second generation of our motion planning simulator which, in addition to being highly optimized for large-scale simulation, provides many new features, such as realistic map integration, vehicle-to-vehicle (V2V) communication, traffic and pedestrian simulation, and a broad variety of sensor models. Moreover, we present a novel benchmark suite for evaluating planning algorithms in various highly challenging scenarios, including interactive driving, such as turning at intersections, and adaptive driving, in which the task is to closely follow a lead vehicle without any explicit knowledge of its intention. Each scenario is characterized by a variety of traffic patterns and road structures. We further propose a series of common and task-specific metrics to effectively evaluate the performance of the planning algorithms. At the end, we evaluate common motion planning algorithms using the proposed benchmark and highlight the challenges the proposed scenarios impose. The new SMARTS 2.0 features and the benchmark are publicly available at github.com/huawei-noah/SMARTS.
Diving Deeper Into Pedestrian Behavior Understanding: Intention Estimation, Action Prediction, and Event Risk Assessment
Jun 29, 2024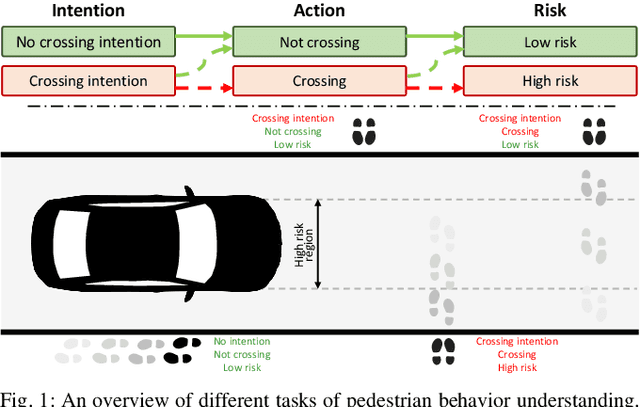



In this paper, we delve into the pedestrian behavior understanding problem from the perspective of three different tasks: intention estimation, action prediction, and event risk assessment. We first define the tasks and discuss how these tasks are represented and annotated in two widely used pedestrian datasets, JAAD and PIE. We then propose a new benchmark based on these definitions, available annotations, and three new classes of metrics, each designed to assess different aspects of the model performance. We apply the new evaluation approach to examine four SOTA prediction models on each task and compare their performance w.r.t. metrics and input modalities. In particular, we analyze the differences between intention estimation and action prediction tasks by considering various scenarios and contextual factors. Lastly, we examine model agreement across these two tasks to show their complementary role. The proposed benchmark reveals new facts about the role of different data modalities, the tasks, and relevant data properties. We conclude by elaborating on our findings and proposing future research directions.
TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Apr 18, 2024As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.
AMEND: A Mixture of Experts Framework for Long-tailed Trajectory Prediction
Feb 13, 2024



Accurate prediction of pedestrians' future motions is critical for intelligent driving systems. Developing models for this task requires rich datasets containing diverse sets of samples. However, the existing naturalistic trajectory prediction datasets are generally imbalanced in favor of simpler samples and lack challenging scenarios. Such a long-tail effect causes prediction models to underperform on the tail portion of the data distribution containing safety-critical scenarios. Previous methods tackle the long-tail problem using methods such as contrastive learning and class-conditioned hypernetworks. These approaches, however, are not modular and cannot be applied to many machine learning architectures. In this work, we propose a modular model-agnostic framework for trajectory prediction that leverages a specialized mixture of experts. In our approach, each expert is trained with a specialized skill with respect to a particular part of the data. To produce predictions, we utilise a router network that selects the best expert by generating relative confidence scores. We conduct experimentation on common pedestrian trajectory prediction datasets and show that besides achieving state-of-the-art performance, our method significantly performs better on long-tail scenarios. We further conduct ablation studies to highlight the contribution of different proposed components.
DICE: Diverse Diffusion Model with Scoring for Trajectory Prediction
Oct 23, 2023Road user trajectory prediction in dynamic environments is a challenging but crucial task for various applications, such as autonomous driving. One of the main challenges in this domain is the multimodal nature of future trajectories stemming from the unknown yet diverse intentions of the agents. Diffusion models have shown to be very effective in capturing such stochasticity in prediction tasks. However, these models involve many computationally expensive denoising steps and sampling operations that make them a less desirable option for real-time safety-critical applications. To this end, we present a novel framework that leverages diffusion models for predicting future trajectories in a computationally efficient manner. To minimize the computational bottlenecks in iterative sampling, we employ an efficient sampling mechanism that allows us to maximize the number of sampled trajectories for improved accuracy while maintaining inference time in real time. Moreover, we propose a scoring mechanism to select the most plausible trajectories by assigning relative ranks. We show the effectiveness of our approach by conducting empirical evaluations on common pedestrian (UCY/ETH) and autonomous driving (nuScenes) benchmark datasets on which our model achieves state-of-the-art performance on several subsets and metrics.
A Novel Benchmarking Paradigm and a Scale- and Motion-Aware Model for Egocentric Pedestrian Trajectory Prediction
Oct 16, 2023Predicting pedestrian behavior is one of the main challenges for intelligent driving systems. In this paper, we present a new paradigm for evaluating egocentric pedestrian trajectory prediction algorithms. Based on various contextual information, we extract driving scenarios for a meaningful and systematic approach to identifying challenges for prediction models. In this regard, we also propose a new metric for more effective ranking within the scenario-based evaluation. We conduct extensive empirical studies of existing models on these scenarios to expose shortcomings and strengths of different approaches. The scenario-based analysis highlights the importance of using multimodal sources of information and challenges caused by inadequate modeling of ego-motion and scale of pedestrians. To this end, we propose a novel egocentric trajectory prediction model that benefits from multimodal sources of data fused in an effective and efficient step-wise hierarchical fashion and two auxiliary tasks designed to learn more robust representation of scene dynamics. We show that our approach achieves significant improvement by up to 40% in challenging scenarios compared to the past arts via empirical evaluation on common benchmark datasets.