 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSNAP: A Benchmark for Testing the Effects of Capture Conditions on Fundamental Vision Tasks
May 21, 2025



Generalization of deep-learning-based (DL) computer vision algorithms to various image perturbations is hard to establish and remains an active area of research. The majority of past analyses focused on the images already captured, whereas effects of the image formation pipeline and environment are less studied. In this paper, we address this issue by analyzing the impact of capture conditions, such as camera parameters and lighting, on DL model performance on 3 vision tasks -- image classification, object detection, and visual question answering (VQA). To this end, we assess capture bias in common vision datasets and create a new benchmark, SNAP (for $\textbf{S}$hutter speed, ISO se$\textbf{N}$sitivity, and $\textbf{AP}$erture), consisting of images of objects taken under controlled lighting conditions and with densely sampled camera settings. We then evaluate a large number of DL vision models and show the effects of capture conditions on each selected vision task. Lastly, we conduct an experiment to establish a human baseline for the VQA task. Our results show that computer vision datasets are significantly biased, the models trained on this data do not reach human accuracy even on the well-exposed images, and are susceptible to both major exposure changes and minute variations of camera settings. Code and data can be found at https://github.com/ykotseruba/SNAP
Diving Deeper Into Pedestrian Behavior Understanding: Intention Estimation, Action Prediction, and Event Risk Assessment
Jun 29, 2024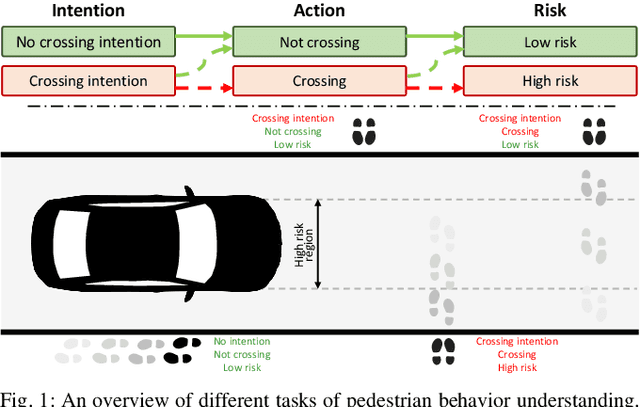



In this paper, we delve into the pedestrian behavior understanding problem from the perspective of three different tasks: intention estimation, action prediction, and event risk assessment. We first define the tasks and discuss how these tasks are represented and annotated in two widely used pedestrian datasets, JAAD and PIE. We then propose a new benchmark based on these definitions, available annotations, and three new classes of metrics, each designed to assess different aspects of the model performance. We apply the new evaluation approach to examine four SOTA prediction models on each task and compare their performance w.r.t. metrics and input modalities. In particular, we analyze the differences between intention estimation and action prediction tasks by considering various scenarios and contextual factors. Lastly, we examine model agreement across these two tasks to show their complementary role. The proposed benchmark reveals new facts about the role of different data modalities, the tasks, and relevant data properties. We conclude by elaborating on our findings and proposing future research directions.
Data Limitations for Modeling Top-Down Effects on Drivers' Attention
Apr 12, 2024



Driving is a visuomotor task, i.e., there is a connection between what drivers see and what they do. While some models of drivers' gaze account for top-down effects of drivers' actions, the majority learn only bottom-up correlations between human gaze and driving footage. The crux of the problem is lack of public data with annotations that could be used to train top-down models and evaluate how well models of any kind capture effects of task on attention. As a result, top-down models are trained and evaluated on private data and public benchmarks measure only the overall fit to human data. In this paper, we focus on data limitations by examining four large-scale public datasets, DR(eye)VE, BDD-A, MAAD, and LBW, used to train and evaluate algorithms for drivers' gaze prediction. We define a set of driving tasks (lateral and longitudinal maneuvers) and context elements (intersections and right-of-way) known to affect drivers' attention, augment the datasets with annotations based on the said definitions, and analyze the characteristics of data recording and processing pipelines w.r.t. capturing what the drivers see and do. In sum, the contributions of this work are: 1) quantifying biases of the public datasets, 2) examining performance of the SOTA bottom-up models on subsets of the data involving non-trivial drivers' actions, 3) linking shortcomings of the bottom-up models to data limitations, and 4) recommendations for future data collection and processing. The new annotations and code for reproducing the results is available at https://github.com/ykotseruba/SCOUT.
SCOUT+: Towards Practical Task-Driven Drivers' Gaze Prediction
Apr 12, 2024



Accurate prediction of drivers' gaze is an important component of vision-based driver monitoring and assistive systems. Of particular interest are safety-critical episodes, such as performing maneuvers or crossing intersections. In such scenarios, drivers' gaze distribution changes significantly and becomes difficult to predict, especially if the task and context information is represented implicitly, as is common in many state-of-the-art models. However, explicit modeling of top-down factors affecting drivers' attention often requires additional information and annotations that may not be readily available. In this paper, we address the challenge of effective modeling of task and context with common sources of data for use in practical systems. To this end, we introduce SCOUT+, a task- and context-aware model for drivers' gaze prediction, which leverages route and map information inferred from commonly available GPS data. We evaluate our model on two datasets, DR(eye)VE and BDD-A, and demonstrate that using maps improves results compared to bottom-up models and reaches performance comparable to the top-down model SCOUT which relies on privileged ground truth information. Code is available at https://github.com/ykotseruba/SCOUT.
Understanding and Modeling the Effects of Task and Context on Drivers' Gaze Allocation
Oct 23, 2023



Understanding what drivers look at is important for many applications, including driver training, monitoring, and assistance, as well as self-driving. Traditionally, factors affecting human visual attention have been divided into bottom-up (involuntary attraction to salient regions) and top-down (task- and context-driven). Although both play a role in drivers' gaze allocation, most of the existing modeling approaches apply techniques developed for bottom-up saliency and do not consider task and context influences explicitly. Likewise, common driving attention benchmarks lack relevant task and context annotations. Therefore, to enable analysis and modeling of these factors for drivers' gaze prediction, we propose the following: 1) address some shortcomings of the popular DR(eye)VE dataset and extend it with per-frame annotations for driving task and context; 2) benchmark a number of baseline and SOTA models for saliency and driver gaze prediction and analyze them w.r.t. the new annotations; and finally, 3) a novel model that modulates drivers' gaze prediction with explicit action and context information, and as a result significantly improves SOTA performance on DR(eye)VE overall (by 24\% KLD and 89\% NSS) and on a subset of action and safety-critical intersection scenarios (by 10--30\% KLD). Extended annotations, code for model and evaluation will be made publicly available.
Intend-Wait-Perceive-Cross: Exploring the Effects of Perceptual Limitations on Pedestrian Decision-Making
Feb 08, 2023



Current research on pedestrian behavior understanding focuses on the dynamics of pedestrians and makes strong assumptions about their perceptual abilities. For instance, it is often presumed that pedestrians have omnidirectional view of the scene around them. In practice, human visual system has a number of limitations, such as restricted field of view (FoV) and range of sensing, which consequently affect decision-making and overall behavior of the pedestrians. By including explicit modeling of pedestrian perception, we can better understand its effect on their decision-making. To this end, we propose an agent-based pedestrian behavior model Intend-Wait-Perceive-Cross with three novel elements: field of vision, working memory, and scanning strategy, all motivated by findings from behavioral literature. Through extensive experimentation we investigate the effects of perceptual limitations on safe crossing decisions and demonstrate how they contribute to detectable changes in pedestrian behaviors.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
PedFormer: Pedestrian Behavior Prediction via Cross-Modal Attention Modulation and Gated Multitask Learning
Oct 14, 2022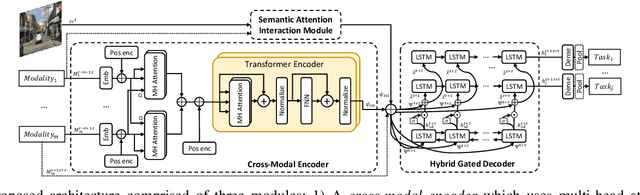
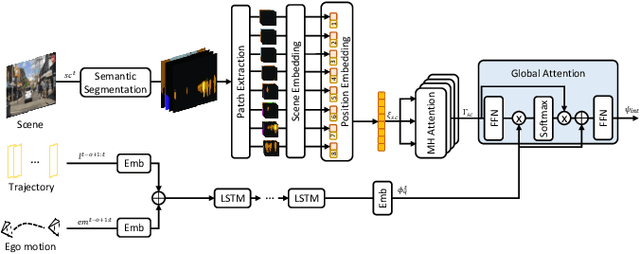
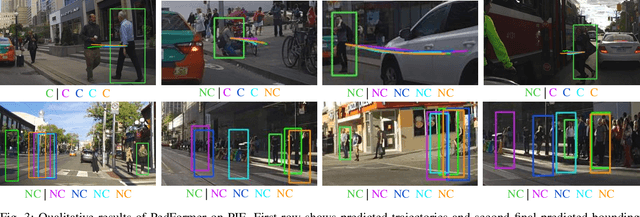
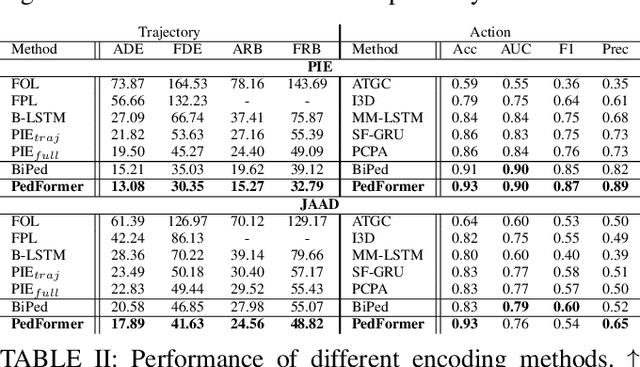
Predicting pedestrian behavior is a crucial task for intelligent driving systems. Accurate predictions require a deep understanding of various contextual elements that potentially impact the way pedestrians behave. To address this challenge, we propose a novel framework that relies on different data modalities to predict future trajectories and crossing actions of pedestrians from an ego-centric perspective. Specifically, our model utilizes a cross-modal Transformer architecture to capture dependencies between different data types. The output of the Transformer is augmented with representations of interactions between pedestrians and other traffic agents conditioned on the pedestrian and ego-vehicle dynamics that are generated via a semantic attentive interaction module. Lastly, the context encodings are fed into a multi-stream decoder framework using a gated-shared network. We evaluate our algorithm on public pedestrian behavior benchmarks, PIE and JAAD, and show that our model improves state-of-the-art in trajectory and action prediction by up to 22% and 13% respectively on various metrics. The advantages brought by components of our model are investigated via extensive ablation studies.
Intend-Wait-Cross: Towards Modeling Realistic Pedestrian Crossing Behavior
Mar 14, 2022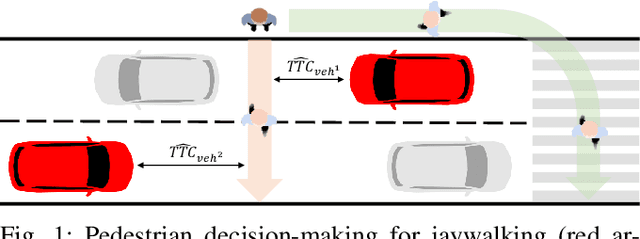
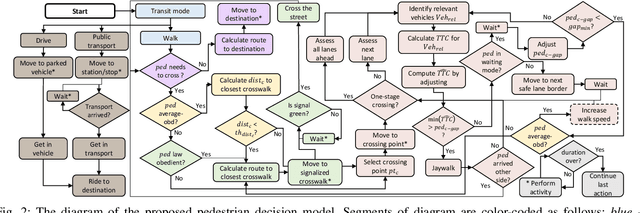


In this paper, we present a microscopic agent-based pedestrian behavior model Intend-Wait-Cross. The model is comprised of rules representing behaviors of pedestrians as a series of decisions that depend on their individual characteristics (e.g. demographics, walking speed, law obedience) and environmental conditions (e.g. traffic flow, road structure). The model's main focus is on generating realistic crossing decision-model, which incorporates an improved formulation of time-to-collision (TTC) computation accounting for context, vehicle dynamics, and perceptual noise. Our model generates a diverse population of agents acting in a highly configurable environment. All model components, including individual characteristics of pedestrians, types of decisions they make, and environmental factors, are motivated by studies on pedestrian traffic behavior. Model parameters are calibrated using a combination of naturalistic driving data and estimates from the literature to maximize the realism of the simulated behaviors. A number of experiments validate various aspects of the model, such as pedestrian crossing patterns, and individual characteristics of pedestrians.
Industry and Academic Research in Computer Vision
Jul 17, 2021



This work aims to study the dynamic between research in the industry and academia in computer vision. The results are demonstrated on a set of top-5 vision conferences that are representative of the field. Since data for such analysis was not readily available, significant effort was spent on gathering and processing meta-data from the original publications. First, this study quantifies the share of industry-sponsored research. Specifically, it shows that the proportion of papers published by industry-affiliated researchers is increasing and that more academics join companies or collaborate with them. Next, the possible impact of industry presence is further explored, namely in the distribution of research topics and citation patterns. The results indicate that the distribution of the research topics is similar in industry and academic papers. However, there is a strong preference towards citing industry papers. Finally, possible reasons for citation bias, such as code availability and influence, are investigated.