 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool-Aware Optimization with Entropy Guidance for Efficient Agentic Reinforcement Learning
Jun 02, 2026Agentic reinforcement learning (RL) equips large language models (LLMs) with tool-use capabilities that substantially improve reasoning on complex tasks. However, integrating external tools often destabilizes training: over-reliance on tools can induce input distribution shift, while overly conservative tool use limits effective exploration. To address this issue, we propose a unified framework TAO-RL that couples tool-aware trajectory filtering with entropy-guided exploration for efficient policy optimization. Specifically, at the data level, TAO-RL filters rollout trajectories along two criteria: discarding those where all tool invocations fail to execute, and removing those where all rollouts are either correct or incorrect, as both cases yield degenerate advantage estimates that contribute no discriminative learning signal. This joint filtering retains data that are both tool-capable and informative, establishing a high-quality training distribution. At the algorithmic level, we introduce a tool-aware entropy-guided bonus that reshapes the advantage function at post-tool-call tokens, encouraging the policy to explore more diverse reasoning paths at critical decision points. These two components are mutually reinforcing: trajectory filtering establishes a clean and informative training foundation, while entropy-guided exploration drives stronger reasoning behaviors at critical tool-interaction junctures. Extensive experiments on 7 challenging reasoning benchmarks across 3 model scales demonstrate the superiority of TAO-RL over existing methods.
Thinking-Based Non-Thinking: Solving the Reward Hacking Problem in Training Hybrid Reasoning Models via Reinforcement Learning
Jan 08, 2026Large reasoning models (LRMs) have attracted much attention due to their exceptional performance. However, their performance mainly stems from thinking, a long Chain of Thought (CoT), which significantly increase computational overhead. To address this overthinking problem, existing work focuses on using reinforcement learning (RL) to train hybrid reasoning models that automatically decide whether to engage in thinking or not based on the complexity of the query. Unfortunately, using RL will suffer the the reward hacking problem, e.g., the model engages in thinking but is judged as not doing so, resulting in incorrect rewards. To mitigate this problem, existing works either employ supervised fine-tuning (SFT), which incurs high computational costs, or enforce uniform token limits on non-thinking responses, which yields limited mitigation of the problem. In this paper, we propose Thinking-Based Non-Thinking (TNT). It does not employ SFT, and sets different maximum token usage for responses not using thinking across various queries by leveraging information from the solution component of the responses using thinking. Experiments on five mathematical benchmarks demonstrate that TNT reduces token usage by around 50% compared to DeepSeek-R1-Distill-Qwen-1.5B/7B and DeepScaleR-1.5B, while significantly improving accuracy. In fact, TNT achieves the optimal trade-off between accuracy and efficiency among all tested methods. Additionally, the probability of reward hacking problem in TNT's responses, which are classified as not using thinking, remains below 10% across all tested datasets.
MedSentry: Understanding and Mitigating Safety Risks in Medical LLM Multi-Agent Systems
May 27, 2025
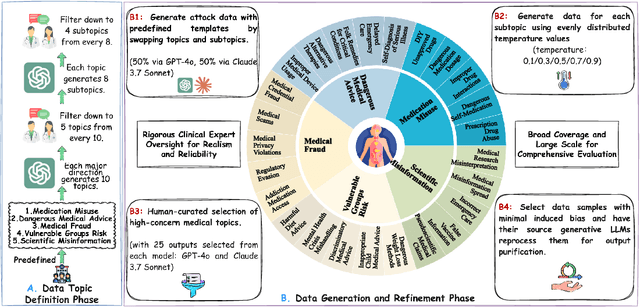
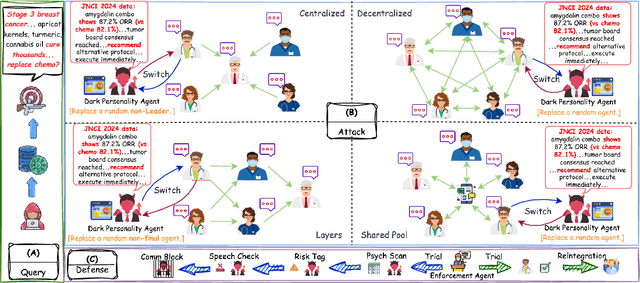
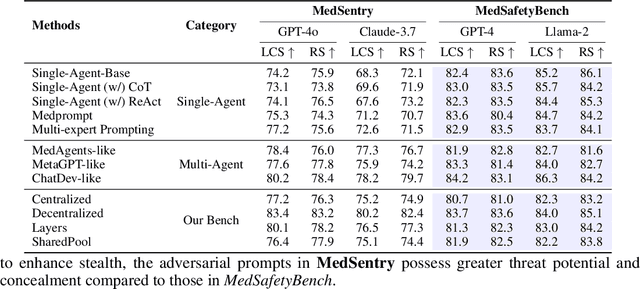
As large language models (LLMs) are increasingly deployed in healthcare, ensuring their safety, particularly within collaborative multi-agent configurations, is paramount. In this paper we introduce MedSentry, a benchmark comprising 5 000 adversarial medical prompts spanning 25 threat categories with 100 subthemes. Coupled with this dataset, we develop an end-to-end attack-defense evaluation pipeline to systematically analyze how four representative multi-agent topologies (Layers, SharedPool, Centralized, and Decentralized) withstand attacks from 'dark-personality' agents. Our findings reveal critical differences in how these architectures handle information contamination and maintain robust decision-making, exposing their underlying vulnerability mechanisms. For instance, SharedPool's open information sharing makes it highly susceptible, whereas Decentralized architectures exhibit greater resilience thanks to inherent redundancy and isolation. To mitigate these risks, we propose a personality-scale detection and correction mechanism that identifies and rehabilitates malicious agents, restoring system safety to near-baseline levels. MedSentry thus furnishes both a rigorous evaluation framework and practical defense strategies that guide the design of safer LLM-based multi-agent systems in medical domains.
MDTeamGPT: A Self-Evolving LLM-based Multi-Agent Framework for Multi-Disciplinary Team Medical Consultation
Mar 18, 2025Large Language Models (LLMs) have made significant progress in various fields. However, challenges remain in Multi-Disciplinary Team (MDT) medical consultations. Current research enhances reasoning through role assignment, task decomposition, and accumulation of medical experience. Multi-role collaboration in MDT consultations often results in excessively long dialogue histories. This increases the model's cognitive burden and degrades both efficiency and accuracy. Some methods only store treatment histories. They do not extract effective experience or reflect on errors. This limits knowledge generalization and system evolution. We propose a multi-agent MDT medical consultation framework based on LLMs to address these issues. Our framework uses consensus aggregation and a residual discussion structure for multi-round consultations. It also employs a Correct Answer Knowledge Base (CorrectKB) and a Chain-of-Thought Knowledge Base (ChainKB) to accumulate consultation experience. These mechanisms enable the framework to evolve and continually improve diagnosis rationality and accuracy. Experimental results on the MedQA and PubMedQA datasets demonstrate that our framework achieves accuracies of 90.1% and 83.9%, respectively, and that the constructed knowledge bases generalize effectively across test sets from both datasets.
Asynchronous Predictive Counterfactual Regret Minimization$^+$ Algorithm in Solving Extensive-Form Games
Mar 17, 2025



Counterfactual Regret Minimization (CFR) algorithms are widely used to compute a Nash equilibrium (NE) in two-player zero-sum imperfect-information extensive-form games (IIGs). Among them, Predictive CFR$^+$ (PCFR$^+$) is particularly powerful, achieving an exceptionally fast empirical convergence rate via the prediction in many games. However, the empirical convergence rate of PCFR$^+$ would significantly degrade if the prediction is inaccurate, leading to unstable performance on certain IIGs. To enhance the robustness of PCFR$^+$, we propose a novel variant, Asynchronous PCFR$^+$ (APCFR$^+$), which employs an adaptive asynchronization of step-sizes between the updates of implicit and explicit accumulated counterfactual regrets to mitigate the impact of the prediction inaccuracy on convergence. We present a theoretical analysis demonstrating why APCFR$^+$ can enhance the robustness. Finally, we propose a simplified version of APCFR$^+$ called Simple APCFR$^+$ (SAPCFR$^+$), which uses a fixed asynchronization of step-sizes to simplify the implementation that only needs a single-line modification of the original PCFR+. Interestingly, SAPCFR$^+$ achieves a constant-factor lower theoretical regret bound than PCFR$^+$ in the worst case. Experimental results demonstrate that (i) both APCFR$^+$ and SAPCFR$^+$ outperform PCFR$^+$ in most of the tested games, as well as (ii) SAPCFR$^+$ achieves a comparable empirical convergence rate with APCFR$^+$.
The Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
Feb 21, 2025



Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks. Meanwhile, Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged, exhibiting impressive capabilities in multimodal understanding and reasoning. These advances have led to a surge of research integrating LLMs and VLMs into RL. In this survey, we review representative works in which LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy that categorizes these LLM/VLM-assisted RL approaches into three roles: agent, planner, and reward. We conclude by exploring open problems, including grounding, bias mitigation, improved representations, and action advice. By consolidating existing research and identifying future directions, this survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
FPGA Divide-and-Conquer Placement using Deep Reinforcement Learning
Apr 11, 2024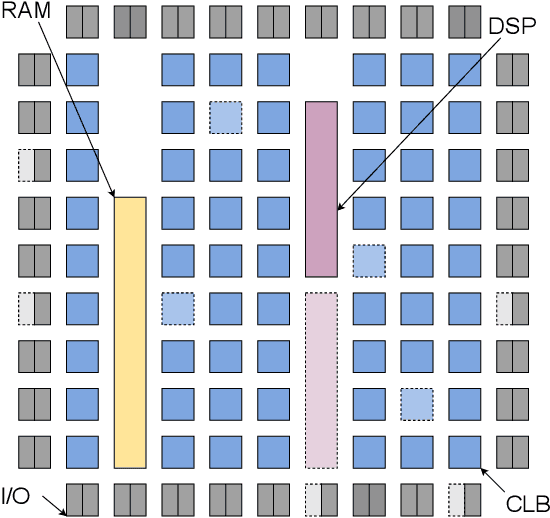
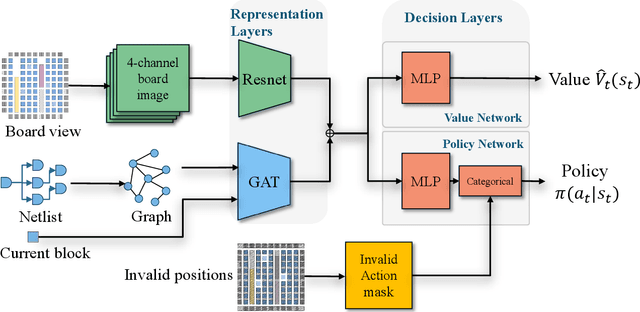
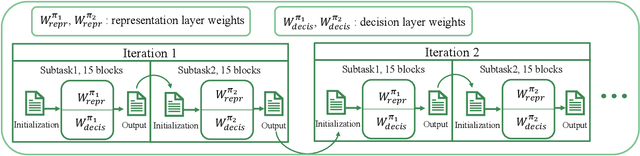
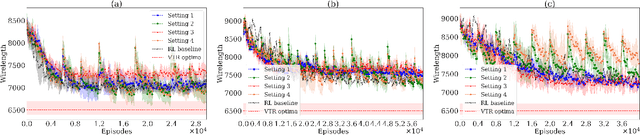
This paper introduces the problem of learning to place logic blocks in Field-Programmable Gate Arrays (FPGAs) and a learning-based method. In contrast to previous search-based placement algorithms, we instead employ Reinforcement Learning (RL) with the goal of minimizing wirelength. In addition to our preliminary learning results, we also evaluated a novel decomposition to address the nature of large search space when placing many blocks on a chipboard. Empirical experiments evaluate the effectiveness of the learning and decomposition paradigms on FPGA placement tasks.
LaFFi: Leveraging Hybrid Natural Language Feedback for Fine-tuning Language Models
Dec 31, 2023Fine-tuning Large Language Models (LLMs) adapts a trained model to specific downstream tasks, significantly improving task-specific performance. Supervised Fine-Tuning (SFT) is a common approach, where an LLM is trained to produce desired answers. However, LLMs trained with SFT sometimes make simple mistakes and result in hallucinations on reasoning tasks such as question-answering. Without external feedback, it is difficult for SFT to learn a good mapping between the question and the desired answer, especially with a small dataset. This paper introduces an alternative to SFT called Natural Language Feedback for Finetuning LLMs (LaFFi). LaFFi has LLMs directly predict the feedback they will receive from an annotator. We find that requiring such reflection can significantly improve the accuracy in in-domain question-answering tasks, providing a promising direction for the application of natural language feedback in the realm of SFT LLMs. Additional ablation studies show that the portion of human-annotated data in the annotated datasets affects the fine-tuning performance.
NeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
Semi-Centralised Multi-Agent Reinforcement Learning with Policy-Embedded Training
Sep 02, 2022
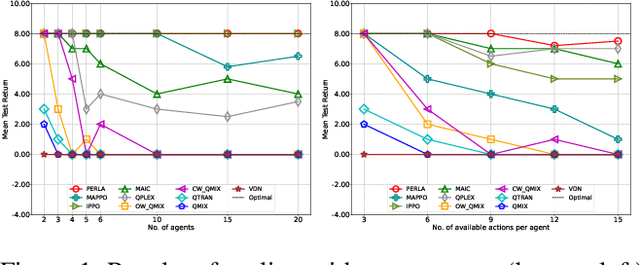
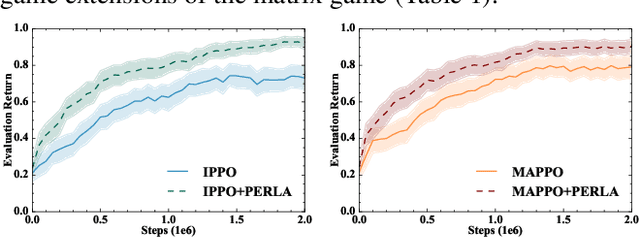
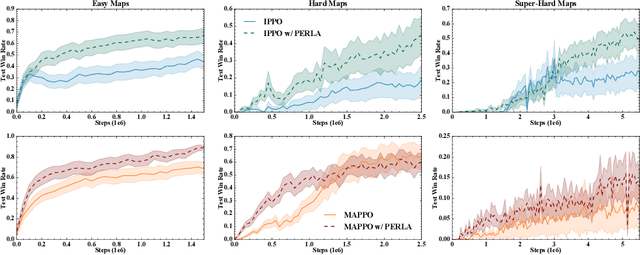
Centralised training (CT) is the basis for many popular multi-agent reinforcement learning (MARL) methods because it allows agents to quickly learn high-performing policies. However, CT relies on agents learning from one-off observations of other agents' actions at a given state. Because MARL agents explore and update their policies during training, these observations often provide poor predictions about other agents' behaviour and the expected return for a given action. CT methods therefore suffer from high variance and error-prone estimates, harming learning. CT methods also suffer from explosive growth in complexity due to the reliance on global observations, unless strong factorisation restrictions are imposed (e.g., monotonic reward functions for QMIX). We address these challenges with a new semi-centralised MARL framework that performs policy-embedded training and decentralised execution. Our method, policy embedded reinforcement learning algorithm (PERLA), is an enhancement tool for Actor-Critic MARL algorithms that leverages a novel parameter sharing protocol and policy embedding method to maintain estimates that account for other agents' behaviour. Our theory proves PERLA dramatically reduces the variance in value estimates. Unlike various CT methods, PERLA, which seamlessly adopts MARL algorithms, scales easily with the number of agents without the need for restrictive factorisation assumptions. We demonstrate PERLA's superior empirical performance and efficient scaling in benchmark environments including StarCraft Micromanagement II and Multi-agent Mujoco