 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking-Based Non-Thinking: Solving the Reward Hacking Problem in Training Hybrid Reasoning Models via Reinforcement Learning
Jan 08, 2026Large reasoning models (LRMs) have attracted much attention due to their exceptional performance. However, their performance mainly stems from thinking, a long Chain of Thought (CoT), which significantly increase computational overhead. To address this overthinking problem, existing work focuses on using reinforcement learning (RL) to train hybrid reasoning models that automatically decide whether to engage in thinking or not based on the complexity of the query. Unfortunately, using RL will suffer the the reward hacking problem, e.g., the model engages in thinking but is judged as not doing so, resulting in incorrect rewards. To mitigate this problem, existing works either employ supervised fine-tuning (SFT), which incurs high computational costs, or enforce uniform token limits on non-thinking responses, which yields limited mitigation of the problem. In this paper, we propose Thinking-Based Non-Thinking (TNT). It does not employ SFT, and sets different maximum token usage for responses not using thinking across various queries by leveraging information from the solution component of the responses using thinking. Experiments on five mathematical benchmarks demonstrate that TNT reduces token usage by around 50% compared to DeepSeek-R1-Distill-Qwen-1.5B/7B and DeepScaleR-1.5B, while significantly improving accuracy. In fact, TNT achieves the optimal trade-off between accuracy and efficiency among all tested methods. Additionally, the probability of reward hacking problem in TNT's responses, which are classified as not using thinking, remains below 10% across all tested datasets.
Tree-Based Stochastic Optimization for Solving Large-Scale Urban Network Security Games
Nov 13, 2025Urban Network Security Games (UNSGs), which model the strategic allocation of limited security resources on city road networks, are critical for urban safety. However, finding a Nash Equilibrium (NE) in large-scale UNSGs is challenging due to their massive and combinatorial action spaces. One common approach to addressing these games is the Policy-Space Response Oracle (PSRO) framework, which requires computing best responses (BR) at each iteration. However, precisely computing exact BRs is impractical in large-scale games, and employing reinforcement learning to approximate BRs inevitably introduces errors, which limits the overall effectiveness of the PSRO methods. Recent advancements in leveraging non-convex stochastic optimization to approximate an NE offer a promising alternative to the burdensome BR computation. However, utilizing existing stochastic optimization techniques with an unbiased loss function for UNSGs remains challenging because the action spaces are too vast to be effectively represented by neural networks. To address these issues, we introduce Tree-based Stochastic Optimization (TSO), a framework that bridges the gap between the stochastic optimization paradigm for NE-finding and the demands of UNSGs. Specifically, we employ the tree-based action representation that maps the whole action space onto a tree structure, addressing the challenge faced by neural networks in representing actions when the action space cannot be enumerated. We then incorporate this representation into the loss function and theoretically demonstrate its equivalence to the unbiased loss function. To further enhance the quality of the converged solution, we introduce a sample-and-prune mechanism that reduces the risk of being trapped in suboptimal local optima. Extensive experimental results indicate the superiority of TSO over other baseline algorithms in addressing the UNSGs.
Asynchronous Predictive Counterfactual Regret Minimization$^+$ Algorithm in Solving Extensive-Form Games
Mar 17, 2025



Counterfactual Regret Minimization (CFR) algorithms are widely used to compute a Nash equilibrium (NE) in two-player zero-sum imperfect-information extensive-form games (IIGs). Among them, Predictive CFR$^+$ (PCFR$^+$) is particularly powerful, achieving an exceptionally fast empirical convergence rate via the prediction in many games. However, the empirical convergence rate of PCFR$^+$ would significantly degrade if the prediction is inaccurate, leading to unstable performance on certain IIGs. To enhance the robustness of PCFR$^+$, we propose a novel variant, Asynchronous PCFR$^+$ (APCFR$^+$), which employs an adaptive asynchronization of step-sizes between the updates of implicit and explicit accumulated counterfactual regrets to mitigate the impact of the prediction inaccuracy on convergence. We present a theoretical analysis demonstrating why APCFR$^+$ can enhance the robustness. Finally, we propose a simplified version of APCFR$^+$ called Simple APCFR$^+$ (SAPCFR$^+$), which uses a fixed asynchronization of step-sizes to simplify the implementation that only needs a single-line modification of the original PCFR+. Interestingly, SAPCFR$^+$ achieves a constant-factor lower theoretical regret bound than PCFR$^+$ in the worst case. Experimental results demonstrate that (i) both APCFR$^+$ and SAPCFR$^+$ outperform PCFR$^+$ in most of the tested games, as well as (ii) SAPCFR$^+$ achieves a comparable empirical convergence rate with APCFR$^+$.
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Models Alignment
Oct 22, 2024



Self-play methods have demonstrated remarkable success in enhancing model capabilities across various domains. In the context of Reinforcement Learning from Human Feedback (RLHF), self-play not only boosts Large Language Model (LLM) performance but also overcomes the limitations of traditional Bradley-Terry (BT) model assumptions by finding the Nash equilibrium (NE) of a preference-based, two-player constant-sum game. However, existing methods either guarantee only average-iterate convergence, incurring high storage and inference costs, or converge to the NE of a regularized game, failing to accurately reflect true human preferences. In this paper, we introduce Magnetic Preference Optimization (MPO), a novel approach capable of achieving last-iterate convergence to the NE of the original game, effectively overcoming the limitations of existing methods. Building upon Magnetic Mirror Descent (MMD), MPO attains a linear convergence rate, making it particularly suitable for fine-tuning LLMs. To ensure our algorithm is both theoretically sound and practically viable, we present a simple yet effective implementation that adapts the theoretical insights to the RLHF setting. Empirical results demonstrate that MPO can significantly enhance the performance of LLMs, highlighting the potential of self-play methods in alignment.
Efficient Last-iterate Convergence Algorithms in Solving Games
Aug 22, 2023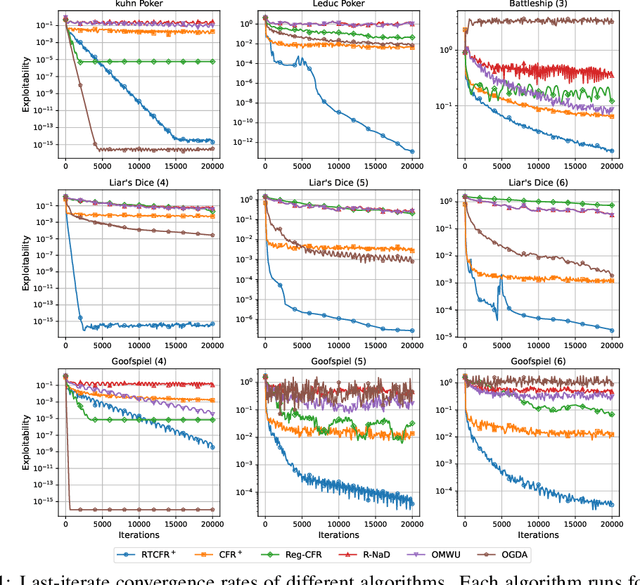
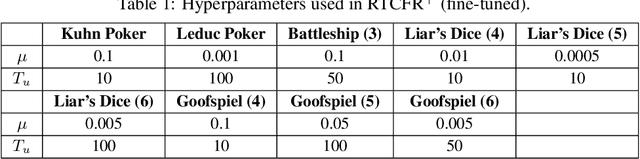
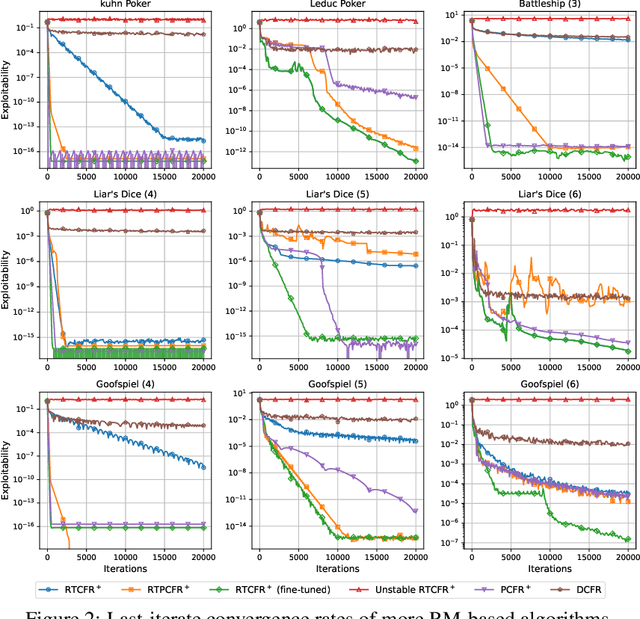
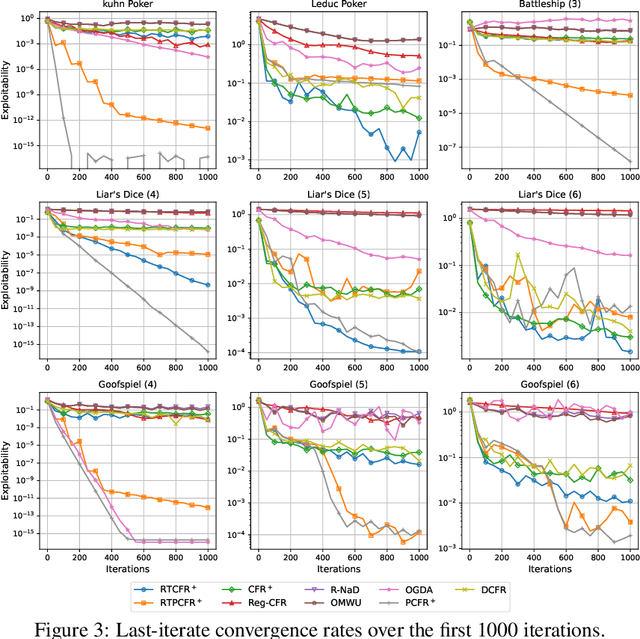
No-regret algorithms are popular for learning Nash equilibrium (NE) in two-player zero-sum normal-form games (NFGs) and extensive-form games (EFGs). Many recent works consider the last-iterate convergence no-regret algorithms. Among them, the two most famous algorithms are Optimistic Gradient Descent Ascent (OGDA) and Optimistic Multiplicative Weight Update (OMWU). However, OGDA has high per-iteration complexity. OMWU exhibits a lower per-iteration complexity but poorer empirical performance, and its convergence holds only when NE is unique. Recent works propose a Reward Transformation (RT) framework for MWU, which removes the uniqueness condition and achieves competitive performance with OMWU. Unfortunately, RT-based algorithms perform worse than OGDA under the same number of iterations, and their convergence guarantee is based on the continuous-time feedback assumption, which does not hold in most scenarios. To address these issues, we provide a closer analysis of the RT framework, which holds for both continuous and discrete-time feedback. We demonstrate that the essence of the RT framework is to transform the problem of learning NE in the original game into a series of strongly convex-concave optimization problems (SCCPs). We show that the bottleneck of RT-based algorithms is the speed of solving SCCPs. To improve the their empirical performance, we design a novel transformation method to enable the SCCPs can be solved by Regret Matching+ (RM+), a no-regret algorithm with better empirical performance, resulting in Reward Transformation RM+ (RTRM+). RTRM+ enjoys last-iterate convergence under the discrete-time feedback setting. Using the counterfactual regret decomposition framework, we propose Reward Transformation CFR+ (RTCFR+) to extend RTRM+ to EFGs. Experimental results show that our algorithms significantly outperform existing last-iterate convergence algorithms and RM+ (CFR+).
Generalized Bandit Regret Minimizer Framework in Imperfect Information Extensive-Form Game
Mar 28, 2022
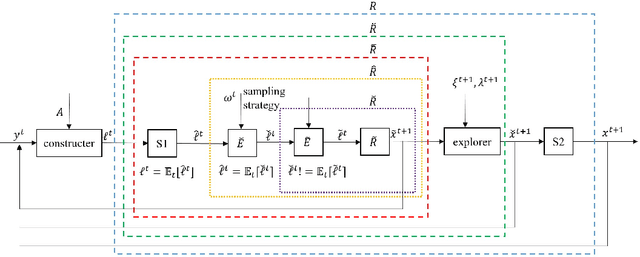
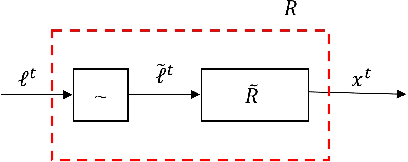
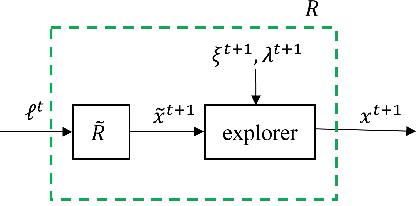
Regret minimization methods are a powerful tool for learning approximate Nash equilibrium (NE) in two-player zero-sum imperfect information extensive-form games (IIEGs). We consider the problem in the interactive bandit-feedback setting where we don't know the dynamics of the IIEG. In general, only the interactive trajectory and the reached terminal node value $v(z^t)$ are revealed. To learn NE, the regret minimizer is required to estimate the full-feedback loss gradient $\ell^t$ by $v(z^t)$ and minimize the regret. In this paper, we propose a generalized framework for this learning setting. It presents a theoretical framework for the design and the modular analysis of the bandit regret minimization methods. We demonstrate that the most recent bandit regret minimization methods can be analyzed as a particular case of our framework. Following this framework, we describe a novel method SIX-OMD to learn approximate NE. It is model-free and extremely improves the best existing convergence rate from the order of $O(\sqrt{X B/T}+\sqrt{Y C/T})$ to $O(\sqrt{ M_{\mathcal{X}}/T} +\sqrt{ M_{\mathcal{Y}}/T})$. Moreover, SIX-OMD is computationally efficient as it needs to perform the current strategy and average strategy updates only along the sampled trajectory.