 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmulet: ReAlignment During Test Time for Personalized Preference Adaptation of LLMs
Feb 26, 2025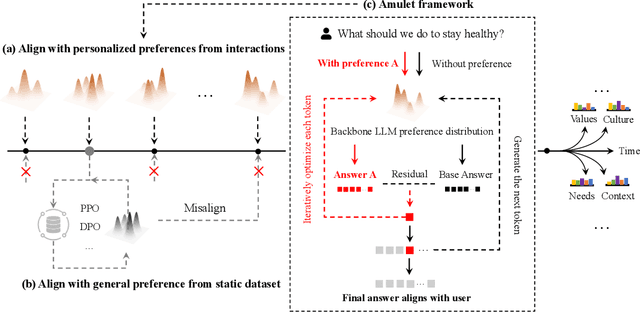
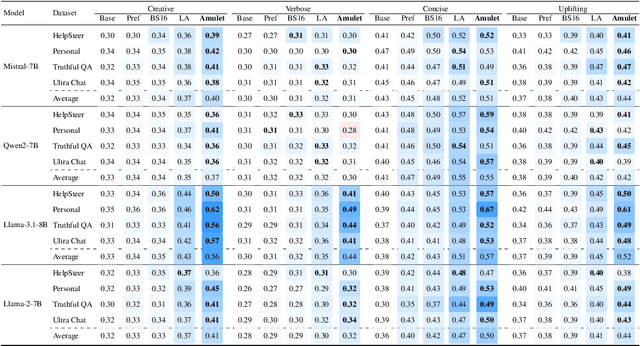
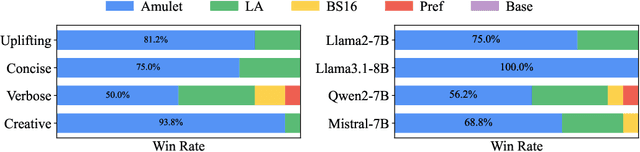

How to align large language models (LLMs) with user preferences from a static general dataset has been frequently studied. However, user preferences are usually personalized, changing, and diverse regarding culture, values, or time. This leads to the problem that the actual user preferences often do not coincide with those trained by the model developers in the practical use of LLMs. Since we cannot collect enough data and retrain for every demand, researching efficient real-time preference adaptation methods based on the backbone LLMs during test time is important. To this end, we introduce Amulet, a novel, training-free framework that formulates the decoding process of every token as a separate online learning problem with the guidance of simple user-provided prompts, thus enabling real-time optimization to satisfy users' personalized preferences. To reduce the computational cost brought by this optimization process for each token, we additionally provide a closed-form solution for each iteration step of the optimization process, thereby reducing the computational time cost to a negligible level. The detailed experimental results demonstrate that Amulet can achieve significant performance improvements in rich settings with combinations of different LLMs, datasets, and user preferences, while maintaining acceptable computational efficiency.
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Models Alignment
Oct 22, 2024



Self-play methods have demonstrated remarkable success in enhancing model capabilities across various domains. In the context of Reinforcement Learning from Human Feedback (RLHF), self-play not only boosts Large Language Model (LLM) performance but also overcomes the limitations of traditional Bradley-Terry (BT) model assumptions by finding the Nash equilibrium (NE) of a preference-based, two-player constant-sum game. However, existing methods either guarantee only average-iterate convergence, incurring high storage and inference costs, or converge to the NE of a regularized game, failing to accurately reflect true human preferences. In this paper, we introduce Magnetic Preference Optimization (MPO), a novel approach capable of achieving last-iterate convergence to the NE of the original game, effectively overcoming the limitations of existing methods. Building upon Magnetic Mirror Descent (MMD), MPO attains a linear convergence rate, making it particularly suitable for fine-tuning LLMs. To ensure our algorithm is both theoretically sound and practically viable, we present a simple yet effective implementation that adapts the theoretical insights to the RLHF setting. Empirical results demonstrate that MPO can significantly enhance the performance of LLMs, highlighting the potential of self-play methods in alignment.
Computing Ex Ante Equilibrium in Heterogeneous Zero-Sum Team Games
Oct 02, 2024



The ex ante equilibrium for two-team zero-sum games, where agents within each team collaborate to compete against the opposing team, is known to be the best a team can do for coordination. Many existing works on ex ante equilibrium solutions are aiming to extend the scope of ex ante equilibrium solving to large-scale team games based on Policy Space Response Oracle (PSRO). However, the joint team policy space constructed by the most prominent method, Team PSRO, cannot cover the entire team policy space in heterogeneous team games where teammates play distinct roles. Such insufficient policy expressiveness causes Team PSRO to be trapped into a sub-optimal ex ante equilibrium with significantly higher exploitability and never converges to the global ex ante equilibrium. To find the global ex ante equilibrium without introducing additional computational complexity, we first parameterize heterogeneous policies for teammates, and we prove that optimizing the heterogeneous teammates' policies sequentially can guarantee a monotonic improvement in team rewards. We further propose Heterogeneous-PSRO (H-PSRO), a novel framework for heterogeneous team games, which integrates the sequential correlation mechanism into the PSRO framework and serves as the first PSRO framework for heterogeneous team games. We prove that H-PSRO achieves lower exploitability than Team PSRO in heterogeneous team games. Empirically, H-PSRO achieves convergence in matrix heterogeneous games that are unsolvable by non-heterogeneous baselines. Further experiments reveal that H-PSRO outperforms non-heterogeneous baselines in both heterogeneous team games and homogeneous settings.
Fusion-PSRO: Nash Policy Fusion for Policy Space Response Oracles
Jun 03, 2024A popular approach for solving zero-sum games is to maintain populations of policies to approximate the Nash Equilibrium (NE). Previous studies have shown that Policy Space Response Oracle (PSRO) algorithm is an effective multi-agent reinforcement learning framework for solving such games. However, repeatedly training new policies from scratch to approximate Best Response (BR) to opponents' mixed policies at each iteration is both inefficient and costly. While some PSRO variants initialize a new policy by inheriting from past BR policies, this approach limits the exploration of new policies, especially against challenging opponents. To address this issue, we propose Fusion-PSRO, which employs policy fusion to initialize policies for better approximation to BR. By selecting high-quality base policies from meta-NE, policy fusion fuses the base policies into a new policy through model averaging. This approach allows the initialized policies to incorporate multiple expert policies, making it easier to handle difficult opponents compared to inheriting from past BR policies or initializing from scratch. Moreover, our method only modifies the policy initialization phase, allowing its application to nearly all PSRO variants without additional training overhead. Our experiments on non-transitive matrix games, Leduc Poker, and the more complex Liars Dice demonstrate that Fusion-PSRO enhances the performance of nearly all PSRO variants, achieving lower exploitability.
Efficient Model-agnostic Alignment via Bayesian Persuasion
May 29, 2024With recent advancements in large language models (LLMs), alignment has emerged as an effective technique for keeping LLMs consensus with human intent. Current methods primarily involve direct training through Supervised Fine-tuning (SFT) or Reinforcement Learning from Human Feedback (RLHF), both of which require substantial computational resources and extensive ground truth data. This paper explores an efficient method for aligning black-box large models using smaller models, introducing a model-agnostic and lightweight Bayesian Persuasion Alignment framework. We formalize this problem as an optimization of the signaling strategy from the small model's perspective. In the persuasion process, the small model (Advisor) observes the information item (i.e., state) and persuades large models (Receiver) to elicit improved responses. The Receiver then generates a response based on the input, the signal from the Advisor, and its updated belief about the information item. Through training using our framework, we demonstrate that the Advisor can significantly enhance the performance of various Receivers across a range of tasks. We theoretically analyze our persuasion framework and provide an upper bound on the Advisor's regret, confirming its effectiveness in learning the optimal signaling strategy. Our Empirical results demonstrates that GPT-2 can significantly improve the performance of various models, achieving an average enhancement of 16.1% in mathematical reasoning ability and 13.7% in code generation. We hope our work can provide an initial step toward rethinking the alignment framework from the Bayesian Persuasion perspective.
Incentive Compatibility for AI Alignment in Sociotechnical Systems: Positions and Prospects
Mar 01, 2024

The burgeoning integration of artificial intelligence (AI) into human society brings forth significant implications for societal governance and safety. While considerable strides have been made in addressing AI alignment challenges, existing methodologies primarily focus on technical facets, often neglecting the intricate sociotechnical nature of AI systems, which can lead to a misalignment between the development and deployment contexts. To this end, we posit a new problem worth exploring: Incentive Compatibility Sociotechnical Alignment Problem (ICSAP). We hope this can call for more researchers to explore how to leverage the principles of Incentive Compatibility (IC) from game theory to bridge the gap between technical and societal components to maintain AI consensus with human societies in different contexts. We further discuss three classical game problems for achieving IC: mechanism design, contract theory, and Bayesian persuasion, in addressing the perspectives, potentials, and challenges of solving ICSAP, and provide preliminary implementation conceptions.