 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
May 14, 2026High-quality 3D scene reconstruction has recently advanced toward generalizable feed-forward architectures, enabling the generation of complex environments in a single forward pass. However, despite their strong performance in static scene perception, these models remain limited in responding to dynamic human instructions, which restricts their use in interactive applications. Existing editing methods typically rely on a 2D-lifting strategy, where individual views are edited independently and then lifted back into 3D space. This indirect pipeline often leads to blurry textures and inconsistent geometry, as 2D editors lack the spatial awareness required to preserve structure across viewpoints. To address these limitations, we propose VGGT-Edit, a feed-forward framework for text-conditioned native 3D scene editing. VGGT-Edit introduces depth-synchronized text injection to align semantic guidance with the backbone's spatial poses, ensuring stable instruction grounding. This semantic signal is then processed by a residual transformation head, which directly predicts 3D geometric displacements to deform the scene while preserving background stability. To ensure high-fidelity results, we supervise the framework with a multi-term objective function that enforces geometric accuracy and cross-view consistency. We also construct the DeltaScene Dataset, a large-scale dataset generated through an automated pipeline with 3D agreement filtering to ensure ground-truth quality. Experiments show that VGGT-Edit substantially outperforms 2D-lifting baselines, producing sharper object details, stronger multi-view consistency, and near-instant inference speed.
Mitigating KG Quality Issues: A Robust Multi-Hop GraphRAG Retrieval Framework
Mar 16, 2026Graph Retrieval-Augmented Generation enhances multi-hop reasoning but relies on imperfect knowledge graphs that frequently suffer from inherent quality issues. Current approaches often overlook these issues, consequently struggling with retrieval drift driven by spurious noise and retrieval hallucinations stemming from incomplete information. To address these challenges, we propose C2RAG (Constraint-Checked Retrieval-Augmented Generation), a framework aimed at robust multi-hop retrieval over the imperfect KG. First, C2RAG performs constraint-based retrieval by decomposing each query into atomic constraint triples, with using fine-grained constraint anchoring to filter candidates for suppressing retrieval drift. Second, C2RAG introduces a sufficiency check to explicitly prevent retrieval hallucinations by deciding whether the current evidence is sufficient to justify structural propagation, and activating textual recovery otherwise. Extensive experiments on multi-hop benchmarks demonstrate that C2RAG consistently outperforms the latest baselines by 3.4\% EM and 3.9\% F1 on average, while exhibiting improved robustness under KG issues.
KEPo: Knowledge Evolution Poison on Graph-based Retrieval-Augmented Generation
Mar 12, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) constructs the Knowledge Graph (KG) from external databases to enhance the timeliness and accuracy of Large Language Model (LLM) generations.However,this reliance on external data introduces new attack surfaces.Attackers can inject poisoned texts into databases to manipulate LLMs into producing harmful target responses for attacker-chosen queries.Existing research primarily focuses on attacking conventional RAG systems.However,such methods are ineffective against GraphRAG.This robustness derives from the KG abstraction of GraphRAG,which reorganizes injected text into a graph before retrieval,thereby enabling the LLM to reason based on the restructured context instead of raw poisoned passages.To expose latent security vulnerabilities in GraphRAG,we propose Knowledge Evolution Poison (KEPo),a novel poisoning attack method specifically designed for GraphRAG.For each target query,KEPo first generates a toxic event containing poisoned knowledge based on the target answer.By fabricating event backgrounds and forging knowledge evolution paths from original facts to the toxic event,it then poisons the KG and misleads the LLM into treating the poisoned knowledge as the final result.In multi-target attack scenarios,KEPo further connects multiple attack corpora,enabling their poisoned knowledge to mutually reinforce while expanding the scale of poisoned communities,thereby amplifying attack effectiveness.Experimental results across multiple datasets demonstrate that KEPo achieves state-of-the-art attack success rates for both single-target and multi-target attacks,significantly outperforming previous methods.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
Openpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
NeuroPath: Neurobiology-Inspired Path Tracking and Reflection for Semantically Coherent Retrieval
Nov 18, 2025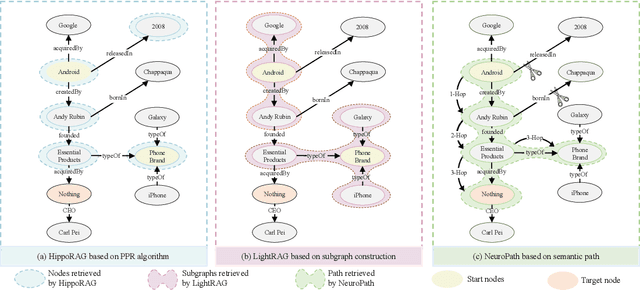
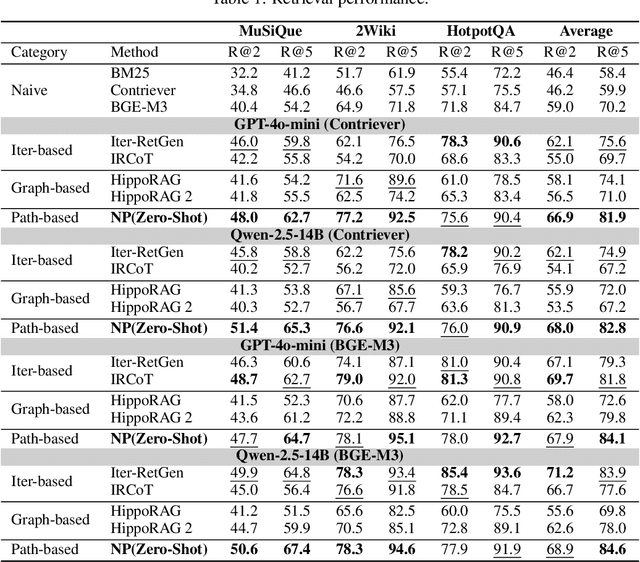
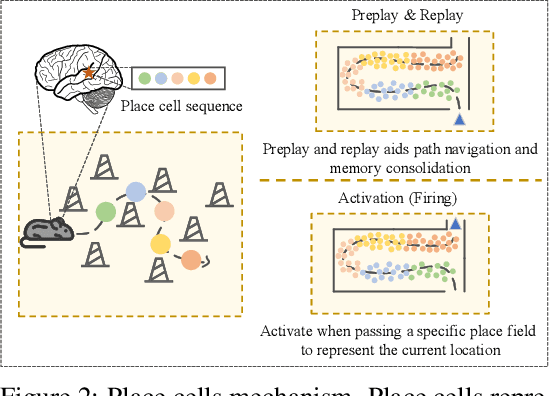
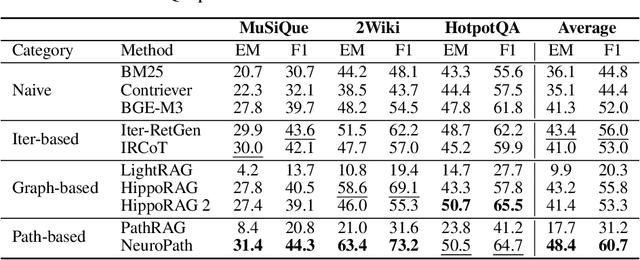
Retrieval-augmented generation (RAG) greatly enhances large language models (LLMs) performance in knowledge-intensive tasks. However, naive RAG methods struggle with multi-hop question answering due to their limited capacity to capture complex dependencies across documents. Recent studies employ graph-based RAG to capture document connections. However, these approaches often result in a loss of semantic coherence and introduce irrelevant noise during node matching and subgraph construction. To address these limitations, we propose NeuroPath, an LLM-driven semantic path tracking RAG framework inspired by the path navigational planning of place cells in neurobiology. It consists of two steps: Dynamic Path Tracking and Post-retrieval Completion. Dynamic Path Tracking performs goal-directed semantic path tracking and pruning over the constructed knowledge graph (KG), improving noise reduction and semantic coherence. Post-retrieval Completion further reinforces these benefits by conducting second-stage retrieval using intermediate reasoning and the original query to refine the query goal and complete missing information in the reasoning path. NeuroPath surpasses current state-of-the-art baselines on three multi-hop QA datasets, achieving average improvements of 16.3% on recall@2 and 13.5% on recall@5 over advanced graph-based RAG methods. Moreover, compared to existing iter-based RAG methods, NeuroPath achieves higher accuracy and reduces token consumption by 22.8%. Finally, we demonstrate the robustness of NeuroPath across four smaller LLMs (Llama3.1, GLM4, Mistral0.3, and Gemma3), and further validate its scalability across tasks of varying complexity. Code is available at https://github.com/KennyCaty/NeuroPath.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025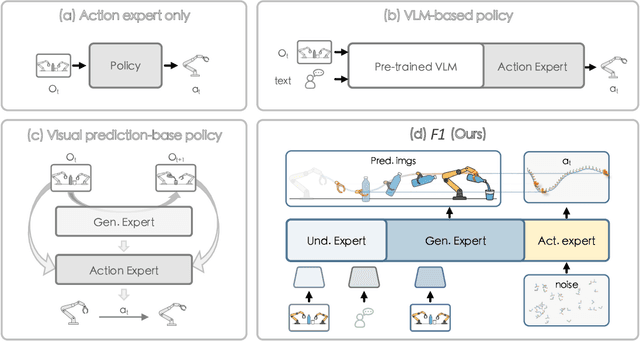

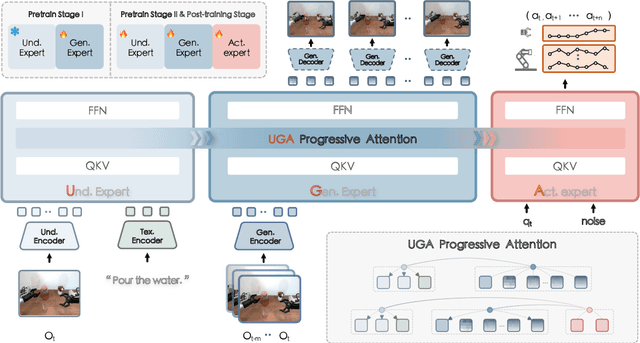

Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Aug 28, 2025The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.
GraphCogent: Overcoming LLMs' Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding
Aug 17, 2025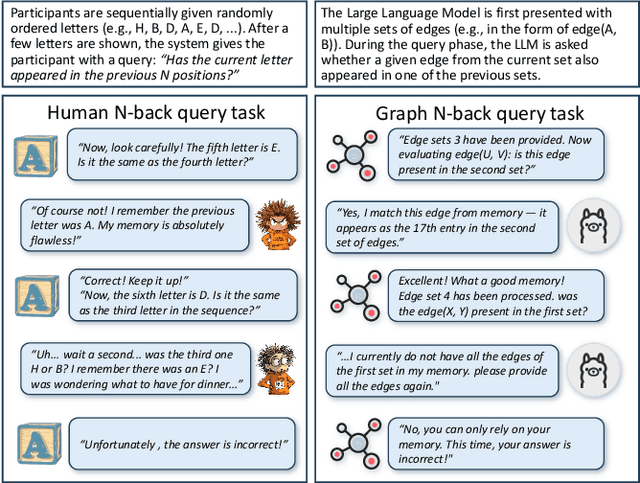
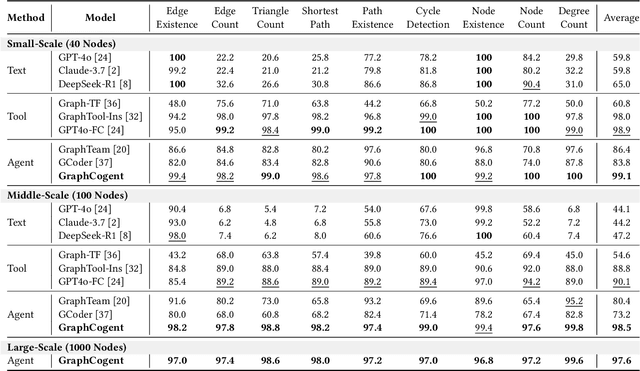
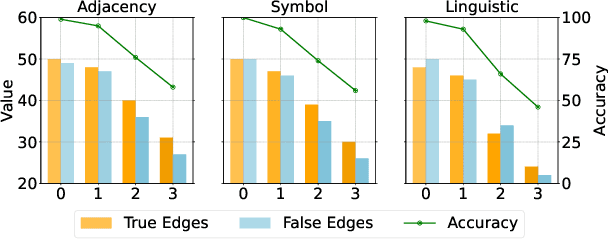

Large language models (LLMs) show promising performance on small-scale graph reasoning tasks but fail when handling real-world graphs with complex queries. This phenomenon stems from LLMs' inability to effectively process complex graph topology and perform multi-step reasoning simultaneously. To address these limitations, we propose GraphCogent, a collaborative agent framework inspired by human Working Memory Model that decomposes graph reasoning into specialized cognitive processes: sense, buffer, and execute. The framework consists of three modules: Sensory Module standardizes diverse graph text representations via subgraph sampling, Buffer Module integrates and indexes graph data across multiple formats, and Execution Module combines tool calling and model generation for efficient reasoning. We also introduce Graph4real, a comprehensive benchmark contains with four domains of real-world graphs (Web, Social, Transportation, and Citation) to evaluate LLMs' graph reasoning capabilities. Our Graph4real covers 21 different graph reasoning tasks, categorized into three types (Structural Querying, Algorithmic Reasoning, and Predictive Modeling tasks), with graph scales that are 10 times larger than existing benchmarks. Experiments show that Llama3.1-8B based GraphCogent achieves a 50% improvement over massive-scale LLMs like DeepSeek-R1 (671B). Compared to state-of-the-art agent-based baseline, our framework outperforms by 20% in accuracy while reducing token usage by 80% for in-toolset tasks and 30% for out-toolset tasks. Code will be available after review.