 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Feb 25, 2025Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.
Aerial Vision-and-Language Navigation via Semantic-Topo-Metric Representation Guided LLM Reasoning
Oct 11, 2024



Aerial Vision-and-Language Navigation (VLN) is a novel task enabling Unmanned Aerial Vehicles (UAVs) to navigate in outdoor environments through natural language instructions and visual cues. It remains challenging due to the complex spatial relationships in outdoor aerial scenes. In this paper, we propose an end-to-end zero-shot framework for aerial VLN tasks, where the large language model (LLM) is introduced as our agent for action prediction. Specifically, we develop a novel Semantic-Topo-Metric Representation (STMR) to enhance the spatial reasoning ability of LLMs. This is achieved by extracting and projecting instruction-related semantic masks of landmarks into a top-down map that contains the location information of surrounding landmarks. Further, this map is transformed into a matrix representation with distance metrics as the text prompt to the LLM, for action prediction according to the instruction. Experiments conducted in real and simulation environments have successfully proved the effectiveness and robustness of our method, achieving 15.9% and 12.5% improvements (absolute) in Oracle Success Rate (OSR) on AerialVLN-S dataset.
HPL-ESS: Hybrid Pseudo-Labeling for Unsupervised Event-based Semantic Segmentation
Mar 25, 2024



Event-based semantic segmentation has gained popularity due to its capability to deal with scenarios under high-speed motion and extreme lighting conditions, which cannot be addressed by conventional RGB cameras. Since it is hard to annotate event data, previous approaches rely on event-to-image reconstruction to obtain pseudo labels for training. However, this will inevitably introduce noise, and learning from noisy pseudo labels, especially when generated from a single source, may reinforce the errors. This drawback is also called confirmation bias in pseudo-labeling. In this paper, we propose a novel hybrid pseudo-labeling framework for unsupervised event-based semantic segmentation, HPL-ESS, to alleviate the influence of noisy pseudo labels. In particular, we first employ a plain unsupervised domain adaptation framework as our baseline, which can generate a set of pseudo labels through self-training. Then, we incorporate offline event-to-image reconstruction into the framework, and obtain another set of pseudo labels by predicting segmentation maps on the reconstructed images. A noisy label learning strategy is designed to mix the two sets of pseudo labels and enhance the quality. Moreover, we propose a soft prototypical alignment module to further improve the consistency of target domain features. Extensive experiments show that our proposed method outperforms existing state-of-the-art methods by a large margin on the DSEC-Semantic dataset (+5.88% accuracy, +10.32% mIoU), which even surpasses several supervised methods.
Fully Self-Supervised Depth Estimation from Defocus Clue
Mar 27, 2023
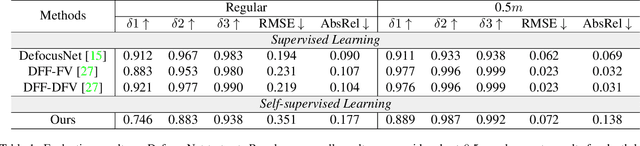
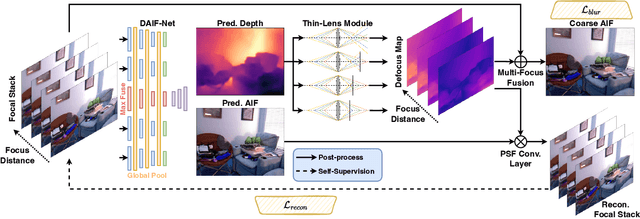
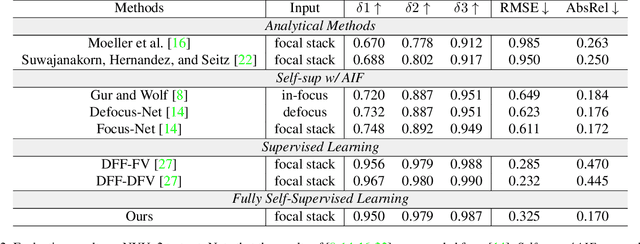
Depth-from-defocus (DFD), modeling the relationship between depth and defocus pattern in images, has demonstrated promising performance in depth estimation. Recently, several self-supervised works try to overcome the difficulties in acquiring accurate depth ground-truth. However, they depend on the all-in-focus (AIF) images, which cannot be captured in real-world scenarios. Such limitation discourages the applications of DFD methods. To tackle this issue, we propose a completely self-supervised framework that estimates depth purely from a sparse focal stack. We show that our framework circumvents the needs for the depth and AIF image ground-truth, and receives superior predictions, thus closing the gap between the theoretical success of DFD works and their applications in the real world. In particular, we propose (i) a more realistic setting for DFD tasks, where no depth or AIF image ground-truth is available; (ii) a novel self-supervision framework that provides reliable predictions of depth and AIF image under the challenging setting. The proposed framework uses a neural model to predict the depth and AIF image, and utilizes an optical model to validate and refine the prediction. We verify our framework on three benchmark datasets with rendered focal stacks and real focal stacks. Qualitative and quantitative evaluations show that our method provides a strong baseline for self-supervised DFD tasks.